This is the third and final part of the review of Oracle Press’ Oracle Big Data Handbook (and last part of our detailed review – previous parts can be seen Part 1 here and Part 2 here). With the first sections having introduced the Big Data Appliance and the case for adopting an appliance, followed by an in depth look at the technologies provided on the BDA for storing data we move into the section that really delivers the pay off, namely the mechanics of converting data to information i.e. Analytics. This means this section of the book concentrates on the likes of Oracle Data Mining (ODM), Oracle R Enterprise and Endeca. The first of the chapters in this part of the book looks at different types of analytics you might need to perform for example data mining, predictive analytics, text mining and so on, the result is that the chapter does seem to flip flop between more classic data warehousing (still Big Data in terms of shear data volumes) to the more contemporary hip and trendy of ‘Big Data’ in the form of Hadoop and R. This may work nicely for a DBA/Data Scientist, but as a technologist and enterprise architect it isn’t so easy as personally I’d prefer to get a sense of each product stack then look at how they compliment/overlap. That said, after the first couple of sections where both the tools and ideas are introduced the flip/flopping is quicker making it easier to cope with, but it also makes for a sizeable opening chapter for this section of the book. But let me show you the kinds in sights that can be gained from the book.
ODM extensions are built around the common Oracle toolkits of RDBMS, SQLDeveloper and additional packages to provide powerful visual paradigms and precanned analytics functionality. Not being a data warehouse expert, I like the fact that the book takes time to describe the processes for building a data model and predictive engine and the likely paths through these steps. The books goes onto to explaining the available Excel tooling. Most of this is helped along with the context of a scenario. Given the claim of realtime capability to take a transaction and use a predictive model against the transactions values to ascertain whether the transaction is likely to be indicative of the characteristics being sought after it would have been nice for the book to provide some outline benchmarks for the scenario. Realtime could be interpreted as a second or two. Which when you’re running millions of transactions with small profit margins per transaction means using such capabilities is a also expectation. Still this doesn’t take away from the clarity of the information that is explained.

From ODM the chapter moves onto introducing the R language. What really got my attention by the book is the apparent willingness to engage with an Open Source model (given the other major players in the evolution of R – Google, Facebook, LinkedIn etc you might argue there is no choice). But the book upfront addresses the fact that Oracle hasn’t (or not yet) incorporated an R editor into SQLDeveloper or JDeveloper and the book suggests a specific tool of RStudio. Then there is the engagement with a library of R extensions (CRAN – Comprehensive R Archive Network with over 5000 extensions).

Google Trends view of Analytics Tools
All of which begs the question, what is Oracle’s value proposition in this pace. The book answers this be describing the challenges of using the Open Source edition of R (memory consumption and single threaded characteristics) and how they have addressed those by extending R into Oracle R Enterprise. In addition to these constraints Oracle’s extension recognises and works with the database governance and security layers properly. It is at this point we’re brought back to earlier focus of the BDA as the extensions allow the BDA Hadoop deployment to be used as a data source (along with Oracle RDBMS). In many respects it feels like a similar proposition to Revolution Analytics (other than the RDBMS emphasis being different). As with the Data Mining the example scenario is used to illustrate the applications of R in conjunction with Hadoop and Oracle RDBMS. To support the illustration the different additional libraries are explained (such as the Hadoop connector, RDBMS connector etc).
R enterprise doesn’t stop here, but has been integrated with PL/SQL, OBIEE and BI Publisher meaning that although some of the tools and the core solution are open source Oracle has achieved a rather rich ecosystem – a point not really called out by the book, but the presentation of the details really makes this jump out.
Still with Chapter 9 we move onto text mining for activities such as sentiment analysis and jump back to ODM with an explanation of the product’s capability in this space and the challenges that this kind of analysis presents. Which is followed by a view of the support R offers. The chapter moves onto things like Spatial analytics and so on. The later forms of analytics don’t confront the ideas of ‘Big Data’ based on the book’s opening definition of big data. That isn’t to say that a brief overview of how Oracle Spatial works and its capabilities to support ideas such as Location Intelligence isn’t interesting but I don’t see any differentiation between big data and normal patterns of use for Oracle Spatial. The examples provided such as knowing if there are patterns of location based usage, but such analysis can be done by ensuring a consistent representation of location from which you can select by a range – either a postal/zip code or by latitude and longitude for example, for which there are more cost effective tools and don’t necessitate pulling data out of a Hadoop cluster to perform such analysis. I would conceded that Oracle Spatial has an information rich data set that could be very effective, but to explore such ideas should we not be looking at ideas like that of ESRI’s integration to Hadoop (and more here) for example if Oracle offer such a capability.
Having crossed a range of technologies Chapter 10 briefly talks about IDEs, but then goes for a deeper dive into R covering the supported Open Source Edition and Enterprise Edition (ORE). The differences between the two versions and the licensing issues are well explained. Based on the description what Oracle have done to make the optimisation and ability to transparently leverage the database seems pretty impressive. The only thing to remember is by transparently moving R’s computational load into the DB is what impact on other processes. Oracle have also enabled ORE to access the predictave analytics capabilities that can reside within an Enterprise Database which are also illustrated here.
After looking at ORE’s capabilities the book moves onto its connection to Hadoop for R (Oracle R Connector for Hadoop – ORCH). ORCH provides the means to interact with HDFS along with the file system and RDBMS. The connector allows for the creating of MapReduce jobs using the R language and interacting the the job scheduler. To fully leverage these capabilities you do want to pull in CRAN libraries. The book then walks through a detailed example of using ORCH with MapReduce (including R script elements). This is then followed by a similar set of examples demonstrating direct interaction with HDFS.

Chapter 11, gives us a focus change again, this time to Endeca for Information Discovery. The book takes us through the history of Endeca and Oracle explaining the component naming – before and after the acquisition and the two dimensions of the Endeca product stack – eCommerce specific and for more general BI.
The chapter looks at the Endeca data model as it is a faceted or tagged model (i.e. all values are represented as label & value). The book emphasis’ the benefits of this model – but not downsides (needing to use the label to determine semantic meaning can have performance implications). This is important is it has implications of the flexibility to enrich data that Endeca can then leverage. Once the basic product and technicalities are examined the book actually steps back to explain the differences between BI and information Discovery and therefore the approaches to using these tools. Then onto to the tooling such as the studio, engine and integration capabilities. The book continues to build on the technical side with the classic NFRs of how to make the technology scale. We then flip back to look at a number of example use cases. Before a final jump to look at mechanics of deploying Endeca and getting some development work underway. The sequencing of the chapter sections does seem a little odd, but it does work, but trying to dive into just the technical dimensions alone probably not a practical proposition here.

Big Data governance is taken on the final chapter of the book – Chapter 12. The emphasis here is to look at the definition of Data Management (e.g. definition by Data Management Association – DAMA) and how Big Data relates to this. So the chapter walks through the key data governance factors – many of which are characterised in the diagram above for example focusing on common legislative considerations such as HIPAA, and Patriot’s Act KYC (Know Your Customer) through to EU Data Protection and UK Financial Services Act. Having a breadth wise view of Data Governance then the book starts to look at how Big Data scenarios differ from raw data and day to day data sets. The problem I have with the chapter here, that all the points being made are valid, but they’re not Big Data issues they are any data governance issues. What Big Data does is introduce technology to capture and use data in ways previously not considered so using the technologies in this way may impact declarations that you may have made to data protection registrar e.g. declare you keep customer data to enable order fulfillment but then use the data to determine effectiveness of sales channels would be an issue. But you dont have to have big data technology to create such an issue (the book itself acknowledges that you could do the analysis with older approaches but the difference is it is easier and quicker now). Having described some ‘any data’ guidance for your big data scenarios the book goes into a raft of big data scenarios in different domains and references some of the relevant legislation. If you read the chapter as just data governance it is a good reminder of the different considerations in data governance.
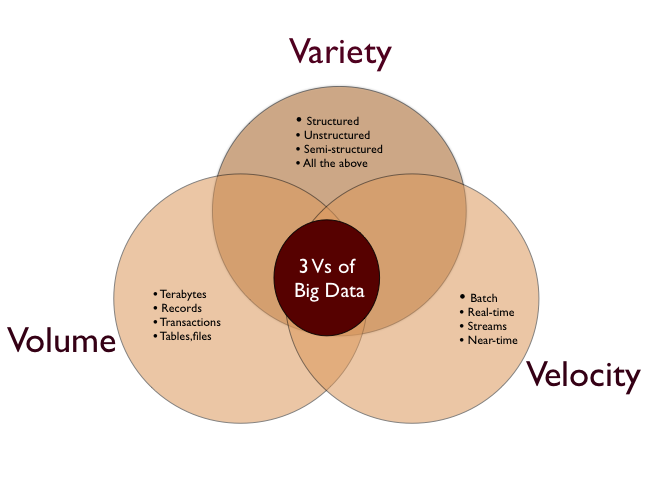
The final Chapter takes on architectural and road mapping considerations. A good way to conclude as this sort of thing will draw on all the preceeding chapters’ points; and this precisely how the chapter starts recapping the value proposition described up front followed the infrastructure considerations – data volumes need to process in parrallel to handle the volumes in timeframes that mean the insights can be assessed and reacted to in a meaningful manner. After the recap the book moves into a maturity model although the origins of the model aren’t clear (I’d have thought that the basis of what is presented is routed in a wider model). This naturally leads into looking at the Oracle Architecture Design Process (OADP). The details of OADP walks thought the goals and mechanics of developing your ‘As-Is’ and ‘To-Be’ architecture so you develop a transitional roadmap. The final step is obviously enabling the journey by developing the human skills necessary to perform such as journey.
Previous Reviews:
's Blog")
 SOA has become probably one of the most used and abused terms in IT in the last decade from assuming that implementing RPC over HTTP (rather than true REST) to the adoption of SOAP and WSDL equates to SOA, but this has been greatly written about. If you read texts such as the tombs from Thomas Erl & co (they are very substantial books and require a strong book case) then you will appreciate the goal to align services to more business centric thinking.
SOA has become probably one of the most used and abused terms in IT in the last decade from assuming that implementing RPC over HTTP (rather than true REST) to the adoption of SOAP and WSDL equates to SOA, but this has been greatly written about. If you read texts such as the tombs from Thomas Erl & co (they are very substantial books and require a strong book case) then you will appreciate the goal to align services to more business centric thinking.






You must be logged in to post a comment.