I’ve written a bit about AI in the development process; this has been driven largely by my own experiences, colleagues’ experiences, and blog content from people I trust. So I thought it would be worthwhile to validate my perspectives against those who are more in the know on the subject. So here is my review of the book Vibe Engineering by Tomasz Lelek and Artur Skowroński.
The book opens with a very clear differentiation between vibe coding and vibe engineering (which approximates to what I’ve previously called AI-assisted development). Not only are the key conceptual differences outlined, but the consequences of vibe coding into production are also really driven home …
teams that skip the transition from prototype to engineered artifact consistently report higher defect density, longer incident resolution, and faster architectural decay
The book also shares some real horror stories of blindly trusting LLMs, particularly in operational contexts.
The crucial challenges of vibe coding beyond ideation, PoC, and possibly MVP are brilliantly distilled. Code will do something, but is it right? Is it safe? Will it scale? Can we maintain it?
Tomasz and Artur outline a form of debt called trust debt. Where we have trusted the LLM, and it accumulates issues, particularly with NFRs that are not managed and paid down, it will seriously bite, just as tech debt does. The difference is that tech debt is more readily appreciated and generally easier to understand.
debt is a direct byproduct of the dump-and-review culture. This approach uses AI to generate a large slab of code, opens a pull request, and implicitly offloads responsibility for verification to the reviewer. It’s classic diffusion of responsibility: the presence of the AI (“the model wrote it”) and a reviewer (“someone will check it”) dilutes the author’s ownership of quality
Current approaches to this kind of development can very easily lead to the issues that Human-Machine Interface researchers talk about as automation complacency and the out-of-the-loop problem
The book also highlights interesting parallels, such as those in autonomous vehicle accidents. The consequences may not be as spectacular or as tragic (today), but they can be just as harmful, given that code affects every little aspect of our lives and the decisions we make. It is only a matter of time before it is influenced by vibed code. How long before pressure and a failure to comprehend vibe coding vs vibe engineering creeps into mission-critical development?
Once the consequences and challenges are called out, the book takes us on a journey to illustrate how to better approach vibe development, specifically through defining what a successful outcome should be. The brilliantly simple thing here is that the two approaches are demonstrated with multiple different LLMs using the same prompt.
While the book provides brilliantly illustrated proofs for how to better approach vibing (moving from coding to engineering), Tomasz and Artur point out that this alone is not enough; we need to lean into broader process improvements and leverage good engineering practices.
This first chapter then sets everything up that follows, taking on a journey of re-engineering a solution. Illustrating how to prompt to extract from an existing solution the details that can then be fed as prompts to generate a new solution.
The narrative progresses through considerations such as context compression, then leverages tools to enable the LLM to take on significant tasks, such as UI design, by giving it the information it needs to work out and create React components with a consistent look and feel.
The books reveal some really good ideas that allow things to be developed far more efficiently, for example, rather than expecting the LLM to scan through code, exposing the Language Server, which provides a lot of today’s IDE smarts, such as navigation through the call chain in an application. Exposing the LSP as an MCP tool offers the LLM an efficient and more reliable approach to analysing code.
If you want to follow along and test the points that the book makes, you’re not going to need to fork out masses on LLM tokens; the authors are very clear that the cost to repeat the exercises can be done within free/trial service tiers.
Conclusion
I don’t want to spoil your enjoyment of reading the book by revealing its secrets here. But there is a lot of great content, which means that, with some adjustments to how the LLM is prompted and some setup, it becomes possible to significantly reduce that trust debt.
If you’re heading down the road of vibe-based development, I would highly recommend digging into this book. We’re already making some further refinements to our processes. The changes needed to transition from vibe coding to vibe engineering won’t be shocking to those with a software engineering background. But their adoption is likely to pay back significantly.
There are a lot of posts on various platforms about how AI is generating ‘slop’, and it is actually costing a lot of time to take what was generated and put it right. Cleaning up after AI is something people are even incorporating into their online biographies. On the other hand, others indicate they’re getting good results. So what is the reality? I think what we’re seeing is a combination of factors, but there is a healthy dose of human behaviour amplifying the issue.
There is no getting around how well a publicly available foundation AI can perform, depending on the availability of content for training. Providing simple Python logic, which has been asked for with clear precision and expressed clearly, is likely to yield positive results – that’s simply a function of the amount of accessible content on the web. If you asked an AI to generate formal method notations like Z or VDM – good luck.
But when we see what, on the surface, looks good, it is easy to be taken in and start to trust the LLM. Combine that with several other factors:
Humans, by our nature, will tend to minimise effort (or, if you want to be crass with language, lazy). You can see this through things like UX design principles that advocate avoiding ‘cognitive load‘ and ‘choice overload’ (the idea that we can only cope with so much information in working memory, going beyond that, we are more likely to make mistakes or need to apply more cognitive effort), through to George Kingsley Zipf’s Human Behavior and the Principle of Least Effort.
When we hand a task to an AI, the way LLMs work means that it will seek to provide an answer, rather than say sorry, can’t get an answer (if we did that, then the principle of least effort would explain why we’d give up with it). So we’re going to get a result, whereas the non-LLM route means we won’t see its incorrect until we’ve finished. When it comes to coding, the LLM is unlikely to make the coding errors we can make as humans, but the code it produces may not be as elegant or efficient, may not address all the edge cases, and may even miss the problem we want to solve. But the outcome will be executable.
Next issue is the quality of prompting: as humans, we have (generally) good long-term memory, and even if we forget specifics, we build a strong contextual understanding that we use. But the LLM doesn’t have this; it doesn’t know whether we’re trying an idea out or writing code that needs to be bombproof and extremely scalable. We have to define that very explicitly. If we’re working with a new or junior developer, we understand that we shouldn’t make these assumptions and will seek verbal and nonverbal feedback if there are issues with clarity or expectations.
When building things manually, each step we take to create the solution (whether that’s code or a PowerPoint) is slower, and we have more time to evaluate what we want to do, how we want to do it, and why we want to do things a particular way. In some respects, the LLM approach is like code reviewing. For a proper review, the reviewer is going to walk through each line of code and evaluate it – a process that can be lengthy. But under time pressure, what often happens is we’ll take a 1st fast pass to look for the ‘bad smells’ and pick up on any obvious issues. Then zero in on the bad smells, or at least the worst ones, and look more closely. But the time pressure, knowing the tooling we have to help eliminate issues, and the mental effort to quickly understand a lot of code take their toll. This, to varying degrees, is exactly what happens with LLM artefacts, except that the rate at which code can be properly reviewed is now a real issue relative to the rate of generation.
Commerce has always been about either innovating to compete or doing things more quickly and cheaply. That pressure has grown as technology has advanced, creating the potential to do more. As a result, it is not surprising to see that pressure results in code being generated, even if that is likely to drive an unwitting accumulation of technical debt that will bite in the years to come. Furthermore, recognising poor-quality code takes experience. Which means expensive engineers. It is possible to appreciate that a non-technical person can generate a basic desktop utility using ChatGPT.
As you can see, there are plenty of things we, as humans, can do to mitigate ‘AI slop’ and get AI delivering value, quality, and velocity.
Conclusion
The bottom line here is an issue of expectation. We wouldn’t be so harsh as to ask someone with dyscalculia to produce a company’s accounts using only a pencil and paper. Another way to look at it, you’d not ask an unqualified accountant to do your tax return. But that is often what is happening, Someone with dyscalculia could easily ‘hallucinate’ the numbers. An unqualified person is not going to know all the rules needed to complete a tax return well enough to minimise tax exposure.
to err is human; to persist in error is diabolical
Saint Augustine
It is human to make mistakes, and poorly directing (or training) an LLM is certainly an error. But we know this is possible, so we should consider what the code is for and take appropriate steps to mitigate it, working to improve how prompts are given and how context is provided to enable better outcomes.
What is clear to me is that ‘AI slop’ isn’t going away soon, and that as engineers, we have to get better at prompting to get the best code we can from an LLM. While it would be nice to think that the industry will realise that LLMs are not a panacea, and you still need those expensive engineers to prompt an LLM so that they don’t generate unnecessary reams of low-grade, brittle code.
The question really has to be, who is going to build an LLM model and agents that can pre-screen code and call out AI ‘slop’, saving code reviewers (particularly those who are looking after the open-source solutions on which so many of us depend). If Anthropic’s Mythos finds 20-year-old bugs, we should be able to help protect open-source projects from low-quality, poorly prompted AI-generated code.
As a Manning author, I am fortunate to see the books in their MEAP (early-release state). If you have a Manning online subscription or have already ordered a copy, you’ll have this privilege as well.
I’ve been reading the MEAP copy of Enterprise RAG by Tyler Suard. At the point of writing, there are still 4 more chapters to come. But, of the first 6 chapters, I have to say, I’ve been impressed. With an open, conversational writing style, it makes for an engaging read (I may be biased here, as this is the writing style I prefer).
The book also challenges assumptions and preconceptions about what RAG needs to be. This starts with differentiation between how RAG is typically described and the needs of an enterprise-grade implementation.
While the book leans into Microsoft Azure to illustrate the development of an enterprise-class solution, much of what has been demonstrated could be implemented with any cloud vendor, and if you’re prepared to put in the effort, then completely open-source.
My recommendation: unless you already have business-wide RAG solutions that are well adopted in production, this book is worth taking a look at. Even for the more knowledgeable/experienced, there are some nicely teased out nuggets of insight.
RAG vs Enterprise RAG?
Within the first couple of pages, Tyler addresses the immediate question of what distinguishes Enterprise RAG from a normal RAG. Here, the issue is elegantly laid out in the classic challenge in engineering books: do you focus on the technical functions and ideas, or on the broader challenges of using these technologies? The key here is to separate Enterprise RAG and what Tyler refers to as Naive RAG. He is tackling the difference between the basic technical mechanics of RAG and how to make RAG work at scale within enterprises, as well as the risks, challenges, and benefits of doing so. This is not to say that one approach or another is right or wrong.
In many respects, as you read through, you want to say, ‘duh, that’s obvious‘, and it is once called out. But so many AI-related projects don’t succeed because we overlook these ‘obvious’ things. AI interaction is often embodied in free text interactions, so we can’t configure the UI into showing English, Spanish, French … UI elements- but not everyone has the same native language as the developers, so we forget to allow for this. This is just one of the multitude of things that get called out.
Walking through the chapters
After setting the scene, the book’s chapters are structured to follow the development process, starting with the AI equivalent of test-driven development (TDD) for Chapter 2. The ‘evals’, the evaluation of defined questions and expected results, and how this can be done given LLMs’ non-deterministic outcomes. This, of course, gives us a framework against which we can validate the RAG and prompting process.
Chapter 3 focuses on preparing the data so it can be retrieved and fed to the LLM to answer the question; here, Tyler challenges the working assumption that the data must come from a vector database. The argument made is that for the most effective RAG process, the most effective (relevant and accurate) data is needed; how the data is obtained is secondary to the effectiveness of the data. A vector database may be the right way to source data, but don’t get locked into that thinking. Having made this point, the book does adopt Azure AI Search, which combines vector search with other techniques to deliver the best results (such as using semantic, keyword and ranking techniques). In open source terms, this is like creating a hybridisation of OpenSearch and Vector search.
Chapter 4 takes us into the data retrieval logic and prompt augmentation, now that we have searchable data. This focuses on the use of the Autogen open source framework (sponsored by Microsoft). In many respects, this is the key chapter in terms of logic, as it shows how the framework is used, with multiple agents working in a swarm.
Chapter 5 moves into the non-functional considerations of deployment and scaling, and ensuring that the solution will work under pressure. Such considerations are as important to an enterprise-scale use case as the functional behaviour. While the chapter covers approaches to automation and testing, I was hoping for more. The approaches described are good for getting things moving, but there are enterprise strategy considerations that could at least be called out, such as PII and more advanced credential management. The last point, which I think is a more significant gap, is Observability; the book talks only of logging. No mention of tracing, the measuring of token consumption, etc.
Chapter 6, the last one currently available, is definitely back on track, addressing one of the key considerations: how do we set and manage user expectations? Is my solution addressing expectations? How well is the solution performing? With conventional apps, the very UI layout and labels, as well as menus, help set expectations. If a search doesn’t give you a means to filter by an attribute, you know the result will include things with values for that attribute that aren’t relevant. But AI use cases are typically textual conversations, with no visual cues indicating the limits of an interaction. There are products that can be integrated into web apps that make it easy to track and measure user actions. But with a simple chat panel, that won’t yield much insight. This means we should provide the means to indicate satisfaction (or lack of, and why). This is what the chapter goes into, illustrating how you could shape expectations,
There are some areas I’d like to see addressed, but it is possible, and based on the chapter titles, they will likely be addressed.
an informal noun referring to the mood, atmosphere, or aura produced by a particular person, thing, or place that is sensed or felt
This is deeply at odds with the idea of software engineering, where the OED describes engineering as:
the activity of applying scientific and mathematical knowledge to the design, building, and control of structures, machines, systems, and processes
While there is a place for vibing – to explore and help test ideas, when it comes to enterprise solutions with icy, typically have large footprints, or will grow to have large footprints and high data volumes, therefore need a more disciplined approach to ensure all those non-functional considerations can be addressed, and sustained. Put it another way, would you take an artesian approach to building and maintaining a petrochemical refinery?
This is why I try to separate the idea of vibe coding from a more disciplined AI-assisted development. A name that doesn’t roll off the tongue well, but conveys the idea that the engineer is in control and can impose discipline to drive the NFRs.
Hopefully, this also helps address nuance, which is often missing in discussions about the use of AI in software engineering, which is definitely polarising viewpoints (like many things today).
Spec-driven development
Spec Driven Development (SDD) is a growing topic in the A.I. assisted development space, and growing as a reflection of the fact that LLMs are improving rapidly, best illustrated at the moment with Mythos. The basis of SDD is to help drive consistency, structure, sustainability and rigour into the AI dev process (back to vibe coding). Consistency and structure allow us to start to easily agentify or tool aspects of development.
Getting a consistent, clear explanation of what constitutes SDD isn’t necessarily straightforward, but the best definition is in an article by Birgitta Böckeler on Martin Fowler’s website. The article dives into not just a basic explanation, but also characterises the differing approaches. The article teased out three versions of the idea, which paraphrasing are:
Spec First – very much like the old-fashioned, here are the requirements that are used to generate a first iteration of the code base. Then subsequent refinements, improvements and general evolution are introduced through successive direct code changes, and/or direct prompting of the LLM to modify different pieces, and add functionality.
Spec Anchored – the Spec is retained for ongoing reference and maintained.
Spec as Source – we don’t really care bout the code, we want a change, we only edit the spec. Code is almost a form of conversation memory, which prevents the LLM from recreating from scratch and producing an answer that looks a bit different, potentially resulting in API names that differ, etc.
This evolution, particularly as people move or are pushed by leadership fearing losing a competitive edge through perceived lower development velocity, increasingly towards a spec-only approach, left me thinking about the agile manifesto and its declaration:
‘we value working code over documentation‘.
While this still has to be true, as ultimately, working code delivers the value. But the heading for the documentation has to be clear, concise, and sized for LLMs’ working documentation, as that is how we get to working code. This isn’t just to bash out some instructions and unleash the LLM; it does need to be refined and iterated on (in many ways, just like a book). We should prompt the LLM to seek clarification rather than let it make assumptions. Furthermore, we need the documentation to be accurate because an LLM will exhibit childlike trust, and if it is working with misaligned content, you’re in a 50/50 position. Unleashing an LLM on your codebase may lead to the wrong outcome. Perhaps, we need to extend the Agile manifesto, with a statement like:
we value correct, accurate, clear and concise documentation over any documentation
In other words, when using an LLM in your development context, it is better to get the LLM to reverse engineer the code to create documentation of your current state (even if that is at the price of losing the original context, design ideals, requirements, etc.) than to allow the LLM to see inaccurate and poor documentation. If this new principle is true, then we need to move away from Spec first to atleast Spec anchored approach.
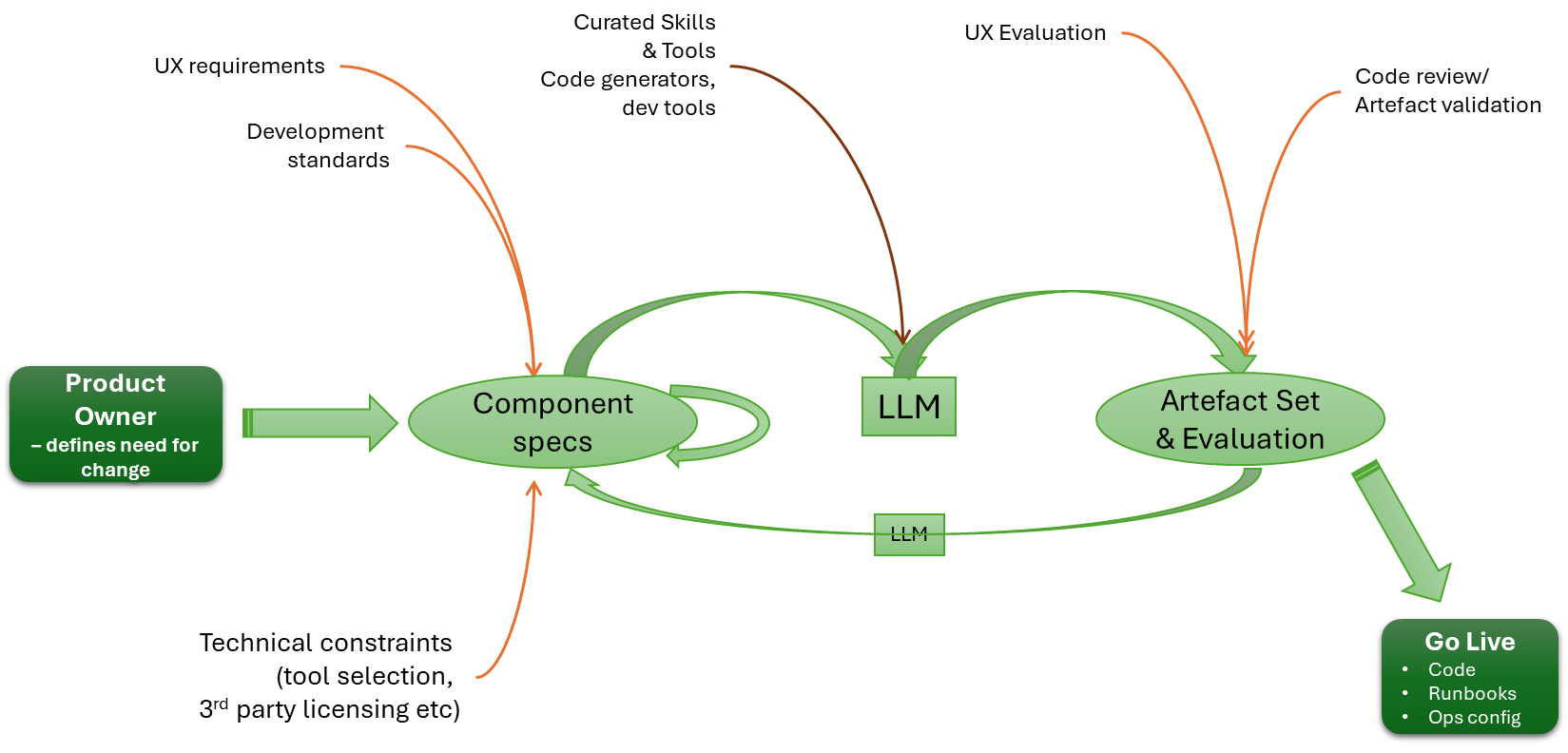
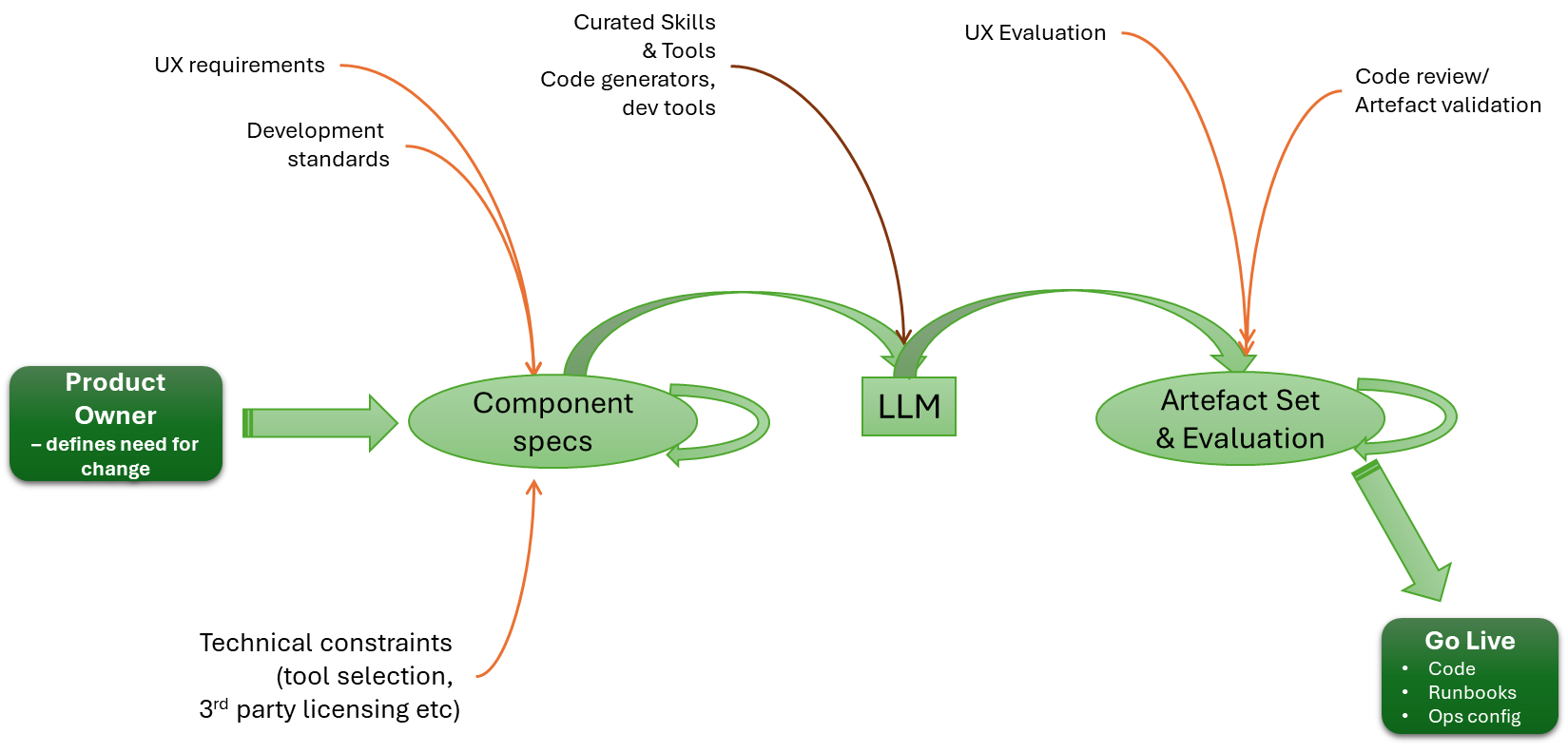
Given this, we should see the heart of an engineering process looking something like:
This is what we should expect with a Spec Anchored or Spec as Source. Whereas with Spec First, the return flow will never happen.With Spec First, our process is more like this: once the code for the first iteration is generated, we just iterate on it.
I think one of the challenges with the view of everything is that, as the Spec lead, there is an expectation that, to do it, we go from a very high-level definition straight to code. The reality is that we need the process to be more human-like. We use the LLM to take requirements and drive a high-level design. We then use the LLM to break the HLD into multiple LLDs. Importantly, we iterate on the process, until the decomposition of detail is right. The LLM cycle focuses on just one output at a time. We can certainly then use the LLM to determine consistency and integrity across all the LLDs.
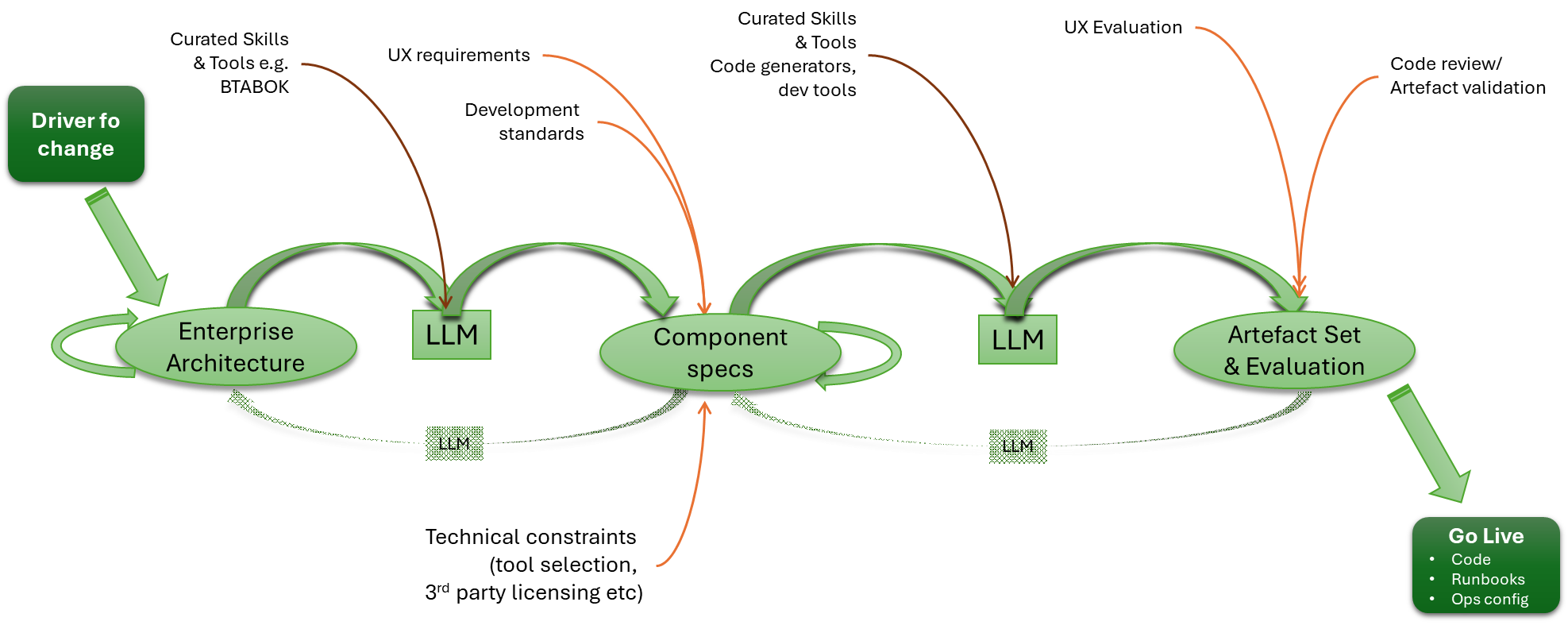
From Requirements to Architectural Views
There is a natural extension to this. If we are to swing back to a document-led approach (albeit with a very different journey from document to working code), could we see increased adoption of TOGAF and other architectural frameworks? Many in the past have used such frameworks as part of the argument as to why things should be code first, as often the framework artefacts are seen as the end, rather than the process and techniques as a means to an end (i.e. we do architecture, therefore I must create a large document set, rather than we do architecture to ensure we get the details we need from code correct).
Certainly, using an LLM to help with the creation and maintenance of architectural views, including making it easier to search for and address inconsistencies across different viewpoints, without necessarily needing very prescriptive, complex, and expensive toolsets.
The document flow if we start with architectural frameworks, from Zachman, TOGAF, C4 etc. Note the return flow needed for Spec Anchored or Spec as Source is rarely happens.
A step in this direction may well be projects such as Common Architecture Language Model (CALM), which is supported by the Fintech Open Source Foundation (FINOS), a child organisation of the Linux Foundation. While I haven’t investigated CALM very deeply, the essence is to define the architectural building blocks in a structured manner, which means that, from the definitions, more detailed diagrams can be generated and AI can be used to analyse the artefacts, etc. This sounds like a potential stepping stone between the organisation/enterprise models of Zachman and TOGAF, which aim to describe how both businesses operate and the underlying technology.
Could we see a time when docs and code stay aligned?
My experience has shown that when a spec has been involved in the process, it has exhibited the characteristics of the Spec First approach, and that the most consistently accurate documents are the user manuals, purely because they have to be created from what the code does. But such documents aren’t meant to tell you about the inner workings of a solution. This is true to the point that organisations have abandoned their architectural models, as they can’t be trusted as an as-is reflection and must start from scratch.
But to achieve the value of Spec Anchored or Spec as Source, we have to ensure that the feedback loop is working: the LLM feeds a backup stream with any changes, and downstream inputs, such as the impact of tool selection, can shift the solution. While the feedback loop should be a lot easier, it still requires commitment and effort to ensure that flow happens (certainly, since it is typically not a regularly practised behaviour).
Flies in the ointment
Trying to drive even a Spec Anchored philosophy is going to be difficult if the LLMs aren’t so great at generating quality code, or quality low-level designs that lead to the code generation. These factors are going to be dependent on choice of LLM being used, how the LLM is prompted, and most crucially the target programming languages (A.I. Codex does well with Python and Java, but I doubt it would make a good job of something like Erlang or Lisp).
The second problem is that there is a common error of people wanting to jump in and cut code (or documents), which often comes from:
Rather than stopping to ask the question, has this problem been solved before, and in a way I can leverage? We plough on creating new unproven code.
The view that the only place where a solution can come from is within the engineering team.
While it will be easy to blame the LLM for problems coming from these actions, are very much human.
Conclusion
As we’ve worked through much of this picture, the irony is that, in many respects, we’re no further forward. We can still make the same mistakes (failing to work through the NFRs properly, failing to define what should happen when something is wrong – aka ‘unhappy paths’, which make recovery simpler). We just have coding and document writing speed shift from 30-40Hz (the speed of a keyboard warrior) to GHz. The same problems can occur because influential decisions are still human (and remember, LLMs are, at their heart, just a computational representation of common thinking (wisdom of crowds, you might say) and therefore still vulnerable).
Going faster means mistakes happen more quickly, and uncorrected mistakes create more mess. To use an analogy, if you crash a car into a wall at 10mph, you’ll damage the bodywork, but it won’t be catastrophic. For many men, the biggest damage will be to the ego. You have the same crash at 100mph, and the outcome will be fatal. While the ability (or lack of) to absorb the energy is what will be the killer, it is actually the fact that you no longer have the time to think and change direction that is the true cause.
Perhaps what we should be seeking from AI is not to get to the end faster, but to use the acceleration to create time to consider what it is we want to achieve and how we continue building on our long-term, more sustainable achievements. This isn’t anti-agile. But it is anti ‘fail fast, fail frequently’ which has been a conflation of ideas without full understanding, and becoming more regularly challenged (like this Forbes Article)
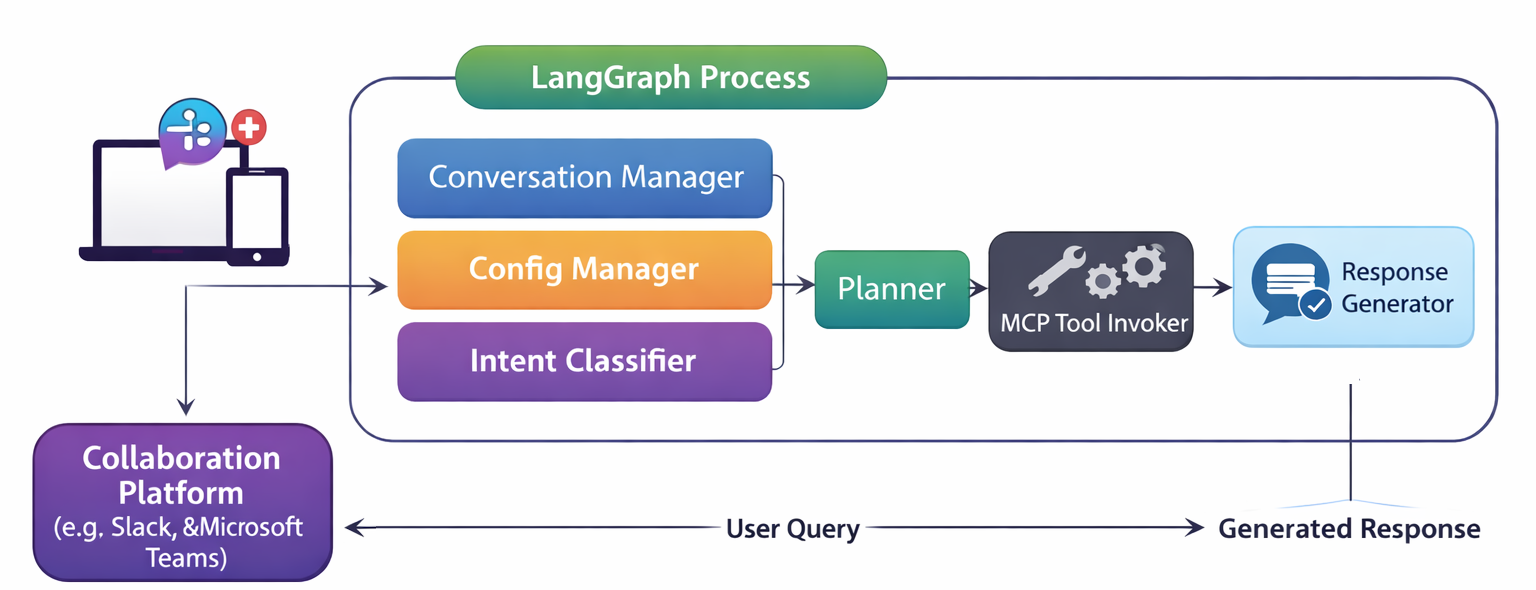
I’ve written a few times about how OpAMP (Open Agent Management Protocol) may emerge from the OpenTelemetry CNCF project, but like OTLP (OpenTelemetry Protocol), it applies to just about any observability agent, not just the OTel Collector. As a side project, giving a real-world use case work on my Python skills, as well as an excuse to work with FastMCP (and LangGraph shortly). But also to bring the evolved idea of ChatOps (see here and here).
One of the goals of ChatOps was to free us from having to actively log into specific tools to mine for information once metrics, traces, and logs reach the aggregating back ends, but being able to. If we leverage a decent LLM with Model Context Protocol tools through an app such as Claude Desktop or ChatGPT (or their mobile variants). Ideally, we have a means to free ourselves to use social collaboration tools, rather than being tied to a specific LLM toolkit.
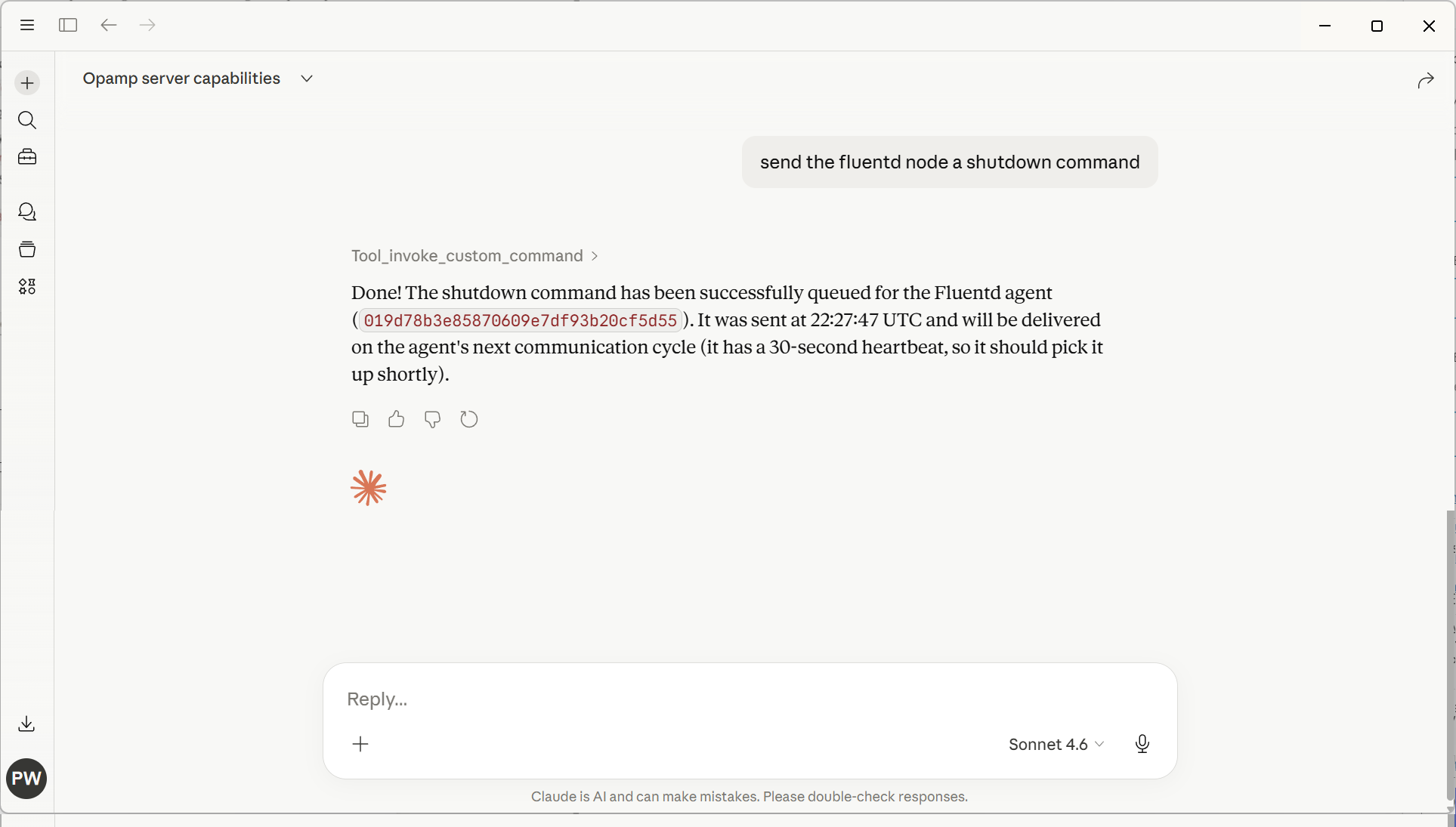
With a UI and the ability to communicate with Fluentd and Fluent Bit without imposing changes on the agent code base (we use a supervisor model), issue commands, track what is going on, and have the option of authentication. (more improvements in this space to come).
New ChatOps – Phase 1
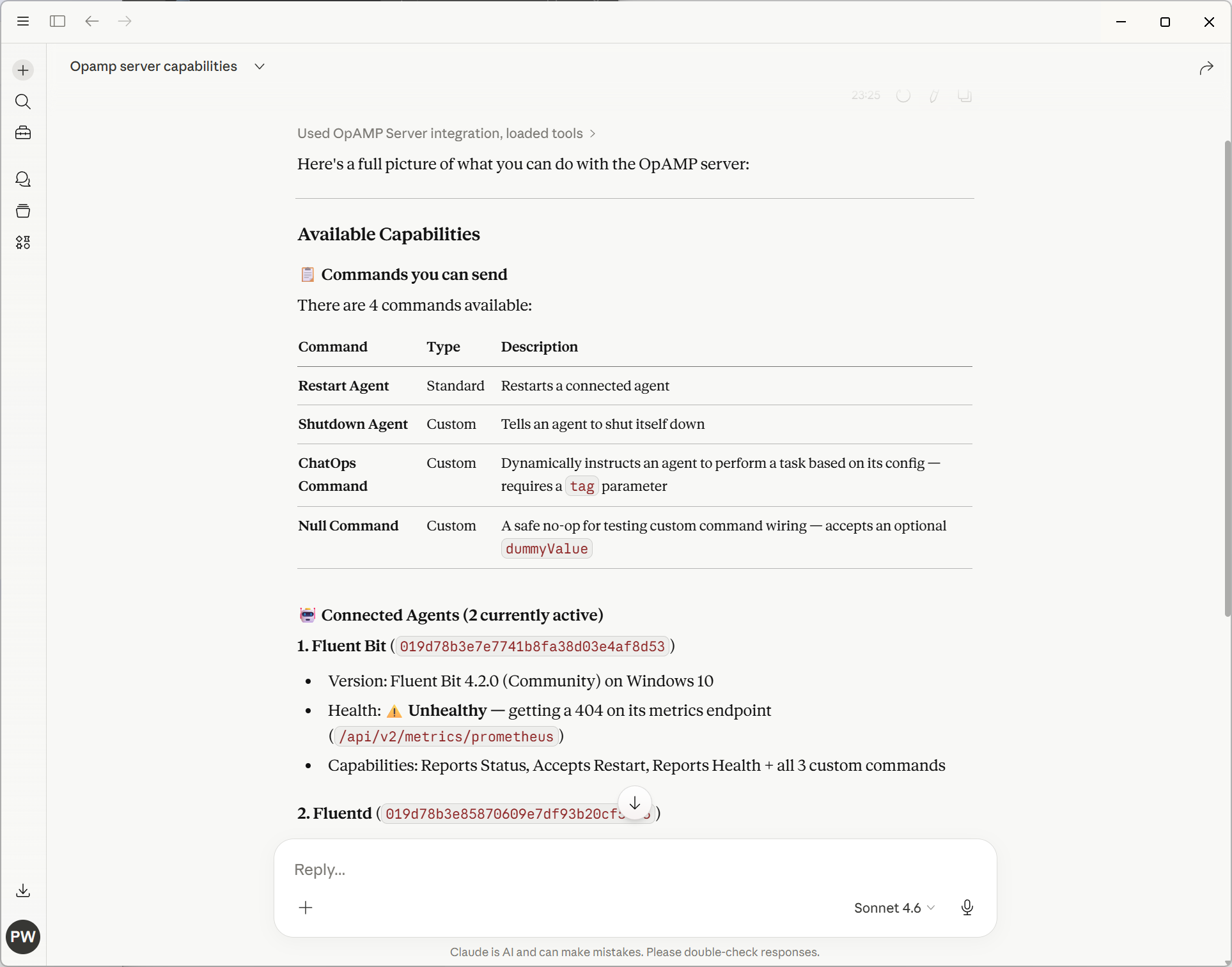
With the first level of the new ChatOps dynamism being through LLM desktop tooling and MCP, the following are screenshots showing how we’ve exposed part of our OpAMP server via APIs. As you can see in the screenshot within our OpAMP server, we have the concept of commands. What we have done is take some of the commands described in the OpAMP spec, call them standard commands, and then define a construct for Custom Commands (which can be dynamically added to the server and client).
The following screenshot illustrates using plain text rather than trying to come up with structured English to get the OpAMP server to shut down a Fluentd node (in this case, as we only had 1 Fluentd node, it worked out which node to stop).
Interesting considerations
What will be interesting to see is the LLM token consumption changes as the portfolio of managed agents changes, given that, to achieve the shutdown, the LLM will have had to obtain all the Fluent Bit & Fluentd instances being managed. If we provide an endpoint to find an agent instance, would the LLM reason to use that rather than trawl all the information?
Next phase
ChatGPT, Claude Desktop, and others already incorporate some level of collaboration capabilities if the users involved are on a suitable premium account (Team/Enterprise). It would be good to enable greater freedom and potentially lower costs by enabling the capability to operate through collaboration platforms such as Teams and Slack. This means the next steps need to look something along the lines of:
There has been a rapidly growing series of articles being written about the limited launch of Mythos, a new LLM. The evolution of models has helped quickly advance AI-assisted software development. But the capabilities of Mythos and Project Glasswing that really grabbed attention and concern.
Glasswing is an initiative that allows major partner software and service vendors to access the Mythos model. This is because Mythos has made significant advances in identifying software vulnerabilities and generating exploits for them. This has been illustrated by Anthropic’s Red team – which found bugs in OpenBSD (OS) that have evaded detection for as much as 27 years. While the BSD family of operating systems isn’t as pervasive as Linux, they both share a similar open ethos and a sufficient community to keep them active and maintained. The underlying message here is that we can find and exploit such vulnerabilities, and there are certainly opportunities to do so elsewhere, in software that can affect a great many more users, such as Firefox.
Having key software vendors, such as OS and browser vendors, get access is certainly a positive step, but it doesn’t address a key consideration. Applying code fixes and releasing updates does not, by itself, equate to being safer. The true challenge is for end users and organisations to recognise the need to roll out updates quickly. This is where the source of true concern should be. The concerns …
Organisations don’t always release patches as soon as they’re available. There is an element of testing to ensure no adverse impact on each organisation’s setup. Even with simple browser changes, something affects the app’s behaviour.
Change represents risk, and organisations that experience issues during rollouts become increasingly risk-averse. Ironically, this is counterintuitive, but a very human reaction.
Vendors’ patching tends to prioritise the latest versions of products, which can create dependency challenges. Bringing software up to date can result in a growing infrastructure footprint (more storage, memory and CPU needed – vendors add capabilities and features to compete and meet customer feature needs, driving continuous growth). That can really add costs, particularly in highly distributed use cases, such as user desktops and IoT devices. Addressing the accumulation of patches means devices no longer have the capability to properly service the new footprint. Consider this: why do people replace smartphones? Sometimes it’s hardware features like a better camera, but often it’s simply not enough storage or not being able to run all the apps, photos, etc.
.Digging into some of the details from the Red Team shows that the LLM usage costs to uncover the vulnerabilities run from $50 – $20,000. This could have ramifications for smaller, more specialised software solutions where the cost of regularly rerunning the analysis outstrips potential revenue. As a result, we could suddenly see software product prices climb, or companies simply stop producing products we depend on. This may also see bad actors wanting to more quickly recoup the cost by accelerating the use of new exploits, in other words, more attacks, coming more quickly. Such considerations will create more pressure on the speed of patch cycles.
This level of capability suggests that we really do need to ensure people shift from boundary-style security to security at every layer of our solutions. That’s not just simply authentication, but code being defensive, validating data values it gets given and os on.
All of this means we have to change mindsets from just enough, or simply putting a front-line security layer in place, to embedding. As end users, we must start to adopt several behaviours:
Security conscious with our own devices – keeping software up to date and patched. I would consider my family to be above average when it comes to tech savvy, but even I am having to go in and run Windows updates on laptops, for example.
Start voting with our feet – many of the services we use are largely or entirely software-powered (banks, energy providers), if those providers show signs of not taking security seriously enough, time to go elsewhere before we become victims.
Keeping up
One observation that the Mythos and Project Glasswing reporting is that the advancements are significant step changes, not incremental advancements (for example, Antghropic’s Sonnet 4.6 was only released a couple of months ago, and didn’t score highly for creating exploits – although better at detection). This suggests a couple of things …
IT law has always played a game of catch-up, but if the advancements are going to be this large and this frequent, we have to start legislating against hypotheticals and allowing legal precedents to produce fine detail interpretations.
We may have to consider big-brother observation of AI use, mitigated by strong transparency rules governing the handling of findings.
Is the idea that we need to start looking at incorporating something like Asimov’s 3 Laws of Robotics into LLMs now looking far-fetched?
Do we need to start thinking about mitigating the risk of deep exploits by bringing back the possibility that systems must be air-gapped?
Hyperbole?
It would be easy to put this down to hyperbole, or wanting to be a click-baity, but this is gaining a lot of high-profile attention, just consider these examples:
The software industry’s current upheavals due to AI are showing signs of unexpected and unintended victims, one of which is open-source software. Open-source foundations run very deep, from Linux to web and app servers, and even to key cryptography technologies.
While there are commercially funded open source efforts, such as chunks of Kubernetes, depending upon which reports you look at, 10-30% of the effort comes from individuals providing their own personal time for free. But we’re seeing a number of threats growing on this…
The number of maintainers is small on some projects. A really good example of this is the Nginx Ingress controller for Kubernetes, which is now no longer being maintained, not because it isn’t needed, but because no one was willing to step up to the plate with their own time or provide salaried engineers. This has triggered something of an outcry (see here, for example).
As this article Microsoft execs warn agentic AI is hollowing out the junior developer pipeline shows, AI-assisted development risks harming the flow of development skills. The issue is that if all junior engineers primarily rely on AI to code and test functionality, the hard-earned experience that teaches you what is good, bad, and where the pitfalls are, they will not gain. Meaning, the skills needed to understand and maintain very large codebases won’t be as strong.
GitHub has argued (here) that AI in development has made it easier for people to get involved and contribute to open-source initiatives, and I’d agree it makers it easier. The challenge, I think, is less an issue of ease than of mindset. I would argue that it is the motivation to contribute and the satisfaction of having contributed that drives open-source contributions, but this is at risk of being undermined (papers such as On Developers’ Personality in Large-scale Distributed Projects indicate open-source contributors tend towards a personality profile, which maybe more suspectable to issues that can lead them to disengage (Connection Between Burnout and Personality Types in Software Developers). While not concrete, overload OSS contributors, and they’re more likely to disengage from contributing.
AI slop, as a result of using a poor coding model, or poor prompting, is showing us that, unwittingly (or through deliberate maliciousness we are seeing pull requests that are buggy, or junk being created at ever faster rates. This puts more work on the core developers to just manage PRs, as described in AI is burning out the people who keep open source alive (another such article at CNCF – Sustaining open source in the age of generative AI). Not to mention even worse actions, such as that described in An AI Agent Published a Hit Piece on Me. This sort of thing will affect people’s willingness to be involved, even when their time is being paid for by a company. This concern is such that InfoWorld reported GitHub are considering the ability to restrict PR velocity (see here).
Another side effect, with the ‘AI arms war’, increases pressure within organisations to adapt, or accelerate as a result of AI expectations. Those donating personal time are less likely to find time to support open-source initiatives, as their focus will be very much on staying secure in their day jobs.
There is no single or simple solution. But that doesn’t mean there aren’t things we can do to help. Some immediate possibilities include:
better messaging about what makes up and propels open-source initiatives beyond commercial contributions. This can help counter the perception that organisations like the CNCF appear to be leaning into large commercial organisations and following open-source business models. But that isn’t the case, and even in the commercial setup, the teams aren’t necessarily that large.
I’m not an advocate of the dual licensing model, as it can create uncertainty in user communities and potential adopters of technologies. This uncertainty can drive disruptive changes; we’ve seen this with OpenSearch and ElasticSearch, OpenELA fork of Linux, among others. It can also hamper early-stage startups. But we can do something: a low-cost entry into CNCF that can help finance the not-for-profit development setups. Use the PR process to help collect metrics and recognise organisations that contribute even a little through PRs, biasing that recognition toward projects with limited support. Not to mention recognising contributors and committers individually (just as CNCF and Linux Foundation provide recognition to conference speakers).
Companies employing early years engineers should implement initiatives that require some development work to be performed without AI assistance and use performance tooling. Yes, this means a short-term drop in productivity, but one thing my years in the industry and training have taught me is that understanding how things work under the hood makes it easier to address problems and recognise ‘bad smells’. Understanding this, helps understand how solutions can scale.
Perhaps University courses could consider awarding credits to students who support important open-source projects, or allow a level of contribution to count toward coursework. This sort of thing would also open up the open-source world a lot more. I, for one, would give credit to a graduate who has contributed to a reputable open-source initiative.
There is on thing I am certain of, though, it is the leadership and sponsors of organisations such as CNCF, Linux Foundation, Apache, Open Source Initiative that can influence the situation the most, and it is in everyone’s interest that when open-source components have to be folded that there is atleast an easier off-ramp, than the 6 months given to switch from using something like NGINX Ingress Controller.
There’s a growing narrative that Agentic AI and “vibe coding” (AI-assisted development is probably a better term) signal the end of SaaS, what some are calling ‘SaaS-pocalyse‘, as reflected by share price drops with some SaaS vendors.
The reality is more nuanced. SaaS vendors are being pulled in multiple directions:
Pressure to invest heavily in AI to accelerate productivity and efficiency
Fear of disruption from AI-native startups
Uncertainty over whether AI is a bubble
Broader economic caution from customers, given the wider economic disruption
Net result: share prices have been dropping rapidly. But importantly, this doesn’t necessarily reflect a collapse in demand—particularly among larger vendors. As Jakob Nielsen has suggested, what we’re more likely to see is commodification (see here) not collapse.
Jakob also pointed out AI is really disrupting approaches to UX, both in how users might approach apps and how user experience is designed.
So what happens to SaaS?
There are a few things emerging I believe …
Vendors incorporating AI into products as they drive to provide more clear value than vibe coding/home brewing your own solution. A route that Oracle have been taking with the Fusion SaaS products.
Emphasis on mechanisms to make it easier for customers to add their differentiators to the core product.
Some vendors are likely to retrench into pure data-platform thinking. But a lot of businesses don’t buy platforms (a platform buy is an act of faith that it can enable you to address a problem); many want to buy a solution to a problem, not a platform, and another 6 months of not knowing if there will be a fix.
So what does this mean for APIs?
Well, APIs are becoming ever more important, but in one of several ways:
Classic API value
Having good APIs with all the support resources will make it easier to bolt on customer differentiators, as a good API (not just well coded) from design to documentation, SDKs, etc., will mean that it will be easier for AI to vibe code, or to use it agentically through MCP, etc.
You’ll need the APIs even more, since they are the means by which you protect data, IP, and/or your data moat, as some have described it.
The other approach, if people retrench SaaS to a more Platform approach, is the risk of just exposing the underlying database. If you’ve worked with an organisation that has an old-school ERP (for example, E-Business Suite) where you’re allowed legitimate access to the schema, you will probably have seen one or more of the following problems:
Unable to upgrade because the upgrade changes the underlying schema, which might break an extension
There are so many extensions that trying to prove that nothing will be harmed by an upgrade is a monumental job of testing – not only on a functional level, but also performance etc. what we have also seen as once people are on this slippery slope, the fear to stop and change tack is too much, often too politically challenging, to hard to make the ROI case.
Feature velocity on the solution slows down because the vendor has to be very careful to ensure changes are unlikely to break a deployment. Completely undermining the SaaS value proposition.
Bottom line, these issues all revolve around the fact that, because someone is using an application schema directly, there is an impediment to change (a few examples are here). As an aside, vendors like Oracle have long provided guidance on tailoring products such as CEMLIs.
There is an argument that some may make here, that making your extensions agentic will solve that, but there are flaws to that argument we’ll come back to.
APIs to ensure data replication
The alternative approach is to provide data replication, batches if you’re old school or streaming for those who want almost immediate data to match data states. In doing so, the SaaS solution now has the freedom (within certain limits) to change its data model. We just have to ensure we can continue to meet the replication contract. This is what Fusion Data Intelligence does, and internally, there are documents that Oracle Fusion applications must adhere to. While this documentation is not a conventional API, it has all the relevant characteristics.
Using APIs for data replication doesn’t always register with people. Which is probably why, despite the popularity of technologies like Kafka, Asynchronous APIs don’t have the impact of the Open API Spec. But the transition of data from one structure to a structure that clients can access and depend upon, not to change, is still a contract.
In the world of Oracle, we would do this using a tool such as GoldenGate (Debezium is an example of an open-source product). Not only are we sharing the data, but we’re also not exposing data that might represent or illustrate how unique IP is achieved, or that is very volatile as a result of ongoing feature development.
There be dragons
Let’s step back for a moment and look at the big picture that is driving things. We want the use of AI and LLMs as they give us speed because we’re able to do things with a greater level of inherent flexibility and speed. That speed essentially comes from entrusting the LLM with the execution details, which means accepting non-determinism as the LLM may not apply the same sequence of steps every time the request is made. At the same time, any system (and particularly software) is only of help if it yields predictable in outcomes. We expect (and have been conditioned) to see consistency, if I give this input, I get this outcome – black box determinism if you like.
So, how can we achieve that deterministic black box? Let’s take a simplistic view of a real-world scenario. A hospital is our system, our deterministic behaviour expectations is sick and hurt people go in, and the system outputs healed and well people. Do we want to know how things work inside the black box? Beyond knowing the process is affordable, painless, caring and quick, then not really.
So how does a hospital do this? We invest heavily in training the tools (medical staff, etc.). We equip them with clearly understood, purposeful services (a theatre, patient monitors, and data on medications with clearly defined characteristics). The better the hospital understands how to use the services and data, the better the output. We can change how a hospital works, through its processes, training and equipment. Executed poorly, and we’ll see an uptick in problems
There is no escaping the fact that providing any API requires thought. Letting your code dictate the API can leave you boxed into a corner with a solution that can’t evolve, and even small changes to the API specification can break your API contract and harm people’s ability to consume it.
It is true that an LLM prompt can be tolerant of certain changes. But, it cuts both ways, poor API changes (e.g attributes and descriptions mismatching, attribute names are too obscure to extract meaning) can result in the LLM failing to interpret the intent from the provider side, or worse the LLM has been producing the expected results, but for unexpected reasons, as a result of small changes this may cause the LLM to start getting it wrong.
This leads to the question of what this means for application APIs? It’s an interesting question, and it’s easy to jump to the assumption that APIs aren’t needed. But, in that direction lie dragons, as the expression goes.
If we approach things from an API first strategy, the API and its definition are less susceptible to change, whether the API definition is implemented using an agent, vibe coded or traditionally developed, the contract will give us some of that determinism.
APIs further benefits
With the challenges and uncertainties mentioned in the world of SaaS, having good APIs can offer additional value, aside from the typical integration value, a good API Gateway setup, and if customers are vibe coding their own UIs from your APIs you’ll be able analyse patterns of usage which will still give some clues as to customer use cases, and which parts of the product are most valuable, just as good UI embedded analytics and trace data can reveal.
Final thought
If there is an existential threat to SaaS, it won’t be solved by abandoning structure. It will be addressed by:
making data accessible
enabling extension
and doubling down on well-designed APIs
In an agentic world, APIs aren’t obsolete. They’re the thing that stops everything from falling apart.
A number of books on the use of LLMs demonstrate how to generate queries against a table from natural language. There is no doubt that providing an LLM and the definition of a simple database and a natural language question, and seeing it provide a valid result is impressive.
The problem is that this struggles to scale to enterprise scenarios where queries need to run on very large databases with tens, if not hundreds, of tables and views. Take a look at the results of the evaluation and benchmarking frameworks like Bird, Spider2, NL2SQL360, and others.
So why do we see a drop in efficacy between small use cases and enterprise systems. Let’s call out the headline challenges you may run into…
The larger the database schema, the more tokens we use just to describe it.
Understanding how relationships between tables work isn’t easy – do we need SQL to include a join, union, or nested queries?
Which tables does the LLM start with?
Does our natural language need the LLM to perform on-the-fly calculations or transformations (for example, I ask for data using inches, but data is stored using millimeters)?
When the entity needs to use attributes that contain names (particularly people, places, chemicals, and medicines), the queries will fail, as there are often multiple spellings and truncations of names.
Does the LLM have permissions to access all the schema (enterprise systems will typically have data subject to PII).
Does this mean that NL2SQL, in practice, is a bust? Not necessarily, but it is a lot harder than it might appear, and how we apply the power of LLM’s may need to be applied in more informed and targeted ways. But we should ask a few questions about the application of LLMs that may impact tolerance to issues…
Will users understand and tolerate a degree of risk and the possibility of an error resulting from hallucination? It’s just like using a calculator for performing calculations – an error in the keying sequence or a failure to apply mathematical precedence, and the result will be wrong, but do you look at the answer and ask yourself whether this is in the right ‘ballpark’? For example, 4 + 2 x 8, if you simplify to 6 x 8, you’ll get the wrong result, as multipliers have precedence over addition, so we should perform 2 x 8 first. If there is no tolerance for error, you need your solution to be completely deterministic, which rules out the use of LLMs.
More generally, will we tolerate SQL that is not performance-optimized? As we’re dealing with a non-deterministic system, we can’t anticipate all the possible indices that might help or other optimizations that could improve the query. If you’re thinking of simply creating many indexes to mitigate risk, remember that maintaining indexes comes at a cost, and the more indexes the SQL engine has to choose from, the harder it has to work to select one.
What level of ‘explainability’ to the answer does the user want? Very few users of enterprise systems will want to have an answer to their questions explained by providing the SQL, and in the world of SaaS, we don’t want that to happen either.
The last dimension is: if a user submits a question prematurely or with poor expression, do we really want to return hundreds or hundreds of thousands of records?
In addition to these questions, we should look at the complexity of our database. This can be covered using several metrics, such as:
NA – Number of Attributes
RD – Referential Degree (the amount of table cross-referencing)
DRT – Depth Relational Tree (the number of relational steps that can be performed to traverse the data model)
The complexity score indicates how hard it will be to formulate queries; in other words, the LLM will have to work harder and, as a result, be more susceptible to errors. So, if we want to move forward with NL2SQL then we need to find a means to reduce the scores.
If you’d like to understand the formulas and theory, there are papers on the subject, such as:
How we respond to these questions will demonstrate our tolerance for challenges and our ability to drive enterprise adoption. Let’s look at some possible strategies to improve things.
Moving forward
One step forward is that each attribute and table can be described; this is essential when using shortened names and acronyms. Such schema metadata can be further extended by describing the relationships and purposes of tables, and even advise the LLM on how to approach common questions, start with table x when being asked about widgets, for example. In many respects, this is not too dissimilar to how we should approach APIs. The best APIs are clearly documented, have consistent naming, and so on.
We can use the LLM to analyse the question and use the result to truncate the provided schema details. For example, in an ERP system, we could easily generate natural-language questions about a supplier or monthly operating costs. But reducing the schema by excluding details from supplier-related tables will narrow the LLM’s scope and, therefore, reduce the likelihood of getting details wrong. This is no different from addressing an exam question and taking a moment to strike out redundant information, as it is noise. You could say we’re removing confounding variables. This idea could be taken further by restricting agents to only working with specific subdomains within the data model.
We can clean up questions. When names are involved, we can use standard language models to extract nouns and their types, then look them up before we formulate an SQL statement. If the question relates to a supplier name, we can easily extract it from the natural-language statement and determine whether such an entity exists. This sort of task doesn’t require us to use powerful, clever foundational LLMs; there are plenty of smaller language models that can do this.
Inject context from the UI
Ideally when a natural query is provided, the more traditional parts of the UI are showing the data, the user can navigate through in traditional manner – replacing years of UI use with a blank conversation page is going to really limit the users understanding of what is available in terms of data and the relationships that already exist, I’ve mentioned this before – Challenges of UX for AI. Assuming that we have something more than a blank conversation window, there is plenty of context to the natural language input. Let’s ensure we’re providing this in a rich manner; this could be more than just the fields on the screen, but associated attributes. For example, if the UI is showing a table, then identifying the entities or filters applied may well help.
Simplifying the schema
Most of our systems are not designed to support NL2SQL, but for core processes that demand considerations, such as frequently occurring queries that are efficient, even more importantly, so that we don’t have issues relating to data integrity. Unless you’re fortunate to be working with a greenfield and keeping the data model simple so processes like NL2SQL have an easy time, we’re going to need to take advantage of database techniques to try to simplify the schema (at least as the NL2SQL process sees it). The sort of things we can do include:
simplify with views
We can join tables and denormalize table structures, such as supplier and address, for example. Navigating table relationships is one of the biggest risks in SQL processing.
Use virtual columns so we can offer data in different formats, such as inches and millimetres, so the LLM doesn’t need to apply unnecessary logic, such as transforming data values. Providing the calculation ourselves means we have control over issues such as precision.
Exclude columns that your NL2SQL does not require. For example, if each table has columns that record who made a change and when, is that needed by the LLM?
Synonyms and other aliasing techniques
We can use synonyms to represent the same tables or columns, enabling us to map question entities to schema tables and columns. This can really help overcome specialist column names in a schema that the LLM is less likely to resolve.
We can also use this to disambiguate meaning; for example, in our ERP, an orders table could have a column called sales. In the context of orders, that would be better expressed as sales-quantity. But then, in the accounting ledger, when we have a sales attribute, that really means sales value.
Simplifying through an Ontology and Graphs
We can model our data and the relationships using an ontology. This isn’t a small undertaking and can bring disruptions of its own. Using an ontology affords us several benefits:
Ontology can drive consistency in our language and its meaning.
An ontology in its pure form will capture the types of objects (entities), their relationships to other entities, and their connections to concepts.
We have the option to exploit standards to notate the ontology in a implementation independent manner.
Applying an ontology allows us to describe the objects, attributes, and relationships in our data model using a structured language. For example supplier has an invoicing address. One key is that we’ve abstracted away how the data is stored (some might refer to this as the physical model, but I hedge on that, as there is a whole layer of science in data-to-storage hardware).
To get to grips with ontology and how we can use it in practice, we need some familiarity with concepts such as Knowledge Graphs, OWL, and RDF. Rather than explaining all these ideas here, here are some resources that cover each technology or concept.
To get to grips with ontology and how we can practically use it, we need some familiarity with concepts such as Knowledge Graphs, OWL, and RDF. Rather than explaining all these ideas here, here are some resources that cover each technology or concept. We’ve added some references for this below.
By modelling our data this way, we make it easier for the LLM by describing our entities and relationships, and, importantly, the description makes it much easier to infer and understand those relationships.
The step up using an ontology gives us the fact that we can express it with a Graph database. We can describe the ontology using graph notation (our entities are objects connected by edges that represent relationships; e.g., a supplier object and an address object are connected by an edge indicating that a supplier has an invoicing address. When we start describing our schema this way, we can begin to think about resolving our question using a graph query.
Not only do we have the relationship between our entities, but we can also describe entity instances with the relationship of ‘is a ‘, e.g., Acme Inc is a supplier.
But, before we start thinking, this is an easily solvable problem; there are still some challenges to be overcome. There is a lot of published advice on how to approach ontology development, including not extrapolating from a database schema (sometimes referred to as a bottom-up approach). If you develop your ontology from a top-down approach, you’ll likely have a nice logical representation of your data. But, the more practical issue is that we can’t convert our existing ERP schema to a fit the logical model, or impose a graph database onto our existing solution; that has horrible implications, such as:
Our existing data model will, even with abstraction layers, affect our application code (yes, the abstractions will mitigate and simplify), but those abstractions will need to be overhauled.
Existing application schemas reflect a balancing act of performance, managing data integrity, and maintainability. Replacing the relational model with a Graph will impact the performance dimension because we’ve abstracted the relationships.
There is also the double-edged challenge of a top-down approach that may reveal entities and relationships we should have in our ERP that aren’t represented for one reason or another. I say double-edged, because knowing the potential gap and representation is a good thing, but it may also create pressure to introduce those entities into a system that doesn’t make it easy to realize them.
If you follow the guidance on developing an Ontology from the research referenced by NIST, which points to defining ontologies in layers and avoiding drawing on data models.
There is also the challenge of avoiding the ontology from imposing an enterprise-wide data model, which slows an organization’s ability to adapt to new needs quickly (the argument for microservices and schema alignment to services). While the effective use of an ontology should act as an accelerator (we know how to represent data constructs, etc.) within an organization that is more siloed in its thinking, it could well become an impediment. Eric Evans’ book Domain Driven Design tries to address indirectly.
Graphs – the magic sauce of ontology and its application
With a schema expressed as a graph (tables and attributes are nodes, and edges represent relationships), we can query the graph to determine how to traverse the schema (if possible or practical) to reach different entities. If the relational schema’s details can be enriched with strong semantic meaning in the relationships, we get further clues about which tables need to be joined. We say practical because it may be possible to traverse the schema, but the number of steps can result in a series of joins that generate unworkable datasets.
We could consider storing not just the schema as a graph, but also the data. There are limits when the nodes become records, and the edges link each node; as a result, data volume explodes, particularly if each leaf node is an attribute. Some graph databases also try to manage things in memory – for multimillion-row tables, this is going to be a challenge.
Some databases that support a converged model can map queries, schemas, and data across the different models. This is very true for Oracle, where services exist that allow us to retrieve the schema as a graph (docs on RDF-based capabilities), translate graph queries (SPARQL / GQL) into relational ones, and so on. The following papers address this sort of capability more generally:
One consideration when using graph queries is the constraints imposed by meeting data manipulation needs, since most relational database SQL provides many more operators.
Ontology more than an aide to AI
A lot of research and thought pieces on ontology have focused on its role in supporting the application of AI. But the concepts as applied to IT and software aren’t new. We can see this by examining standards such as OWL and RDF. Ontology can support many design activities, such as developing initial data models (pre-normalization), API design, and user journey description. The change is that these processes implicitly or indirectly engage with ontological ideas. For example, when we’re designing APIs, particularly for graph queries, we’re thinking about entities and how they relate. While we tend to view relationships through the CRUD lens, this is a crude classification of the relationship that exists.
Getting from Natural Language to the query
This leads us to the question of how to translate our natural language question into a Graph query without encountering the same problems. This is a question of understanding intent; the focus is no longer to jump to prompting for SQL generation, but to extract the attributes that are wanted by examining the natural language (we can even look to do this with smaller models focusing on language), and tease out the actual values (keys) that may be referenced. With this information, we can determine how to traverse the schema and potentially generate the query. If we can’t make that direct step with the graph (we may be asked to perform data manipulation operations that graph query languages aren’t designed for), relational databases offer a wealth of DML operators that graph query languages lack. We can now provide more explicit instructions to the LLM to generate SQL. To the point, our prompt for this step could look more like a developer prompt. Of course, with these prechecks, we can also direct the process to address ambiguities, such as matching the NL statement to the schemas’ attributes that should be involved.
As you can see through the use of graph representations of our relational data, we can look to move the LLM from trying to reason about complex schemas to examining the natural language, providing information on its intent, and then directing it to generate a formalized syntax – all of which leans into the strengths of LLMs. Yes, LLMs are getting better as research and development drive ever-improving reasoning. But ultimately, to assure results and eliminate hallucination, the more we can push towards deterministic behaviour, the better. After all, determinism means we can be confident that the result is right for the right reasons, rather than getting things right, but that the means by which the answer was achieved was wrong.
Growing evidence that graph is the way to go
This blog has been evolving for some time, since I started to dial into the use of ontologies and, more critically, graphs. I’ve started to see more articles on the strategy as a way to make NL2SQL work with enterprise schemas. So I’ve added a few of these references to the following useful resources.
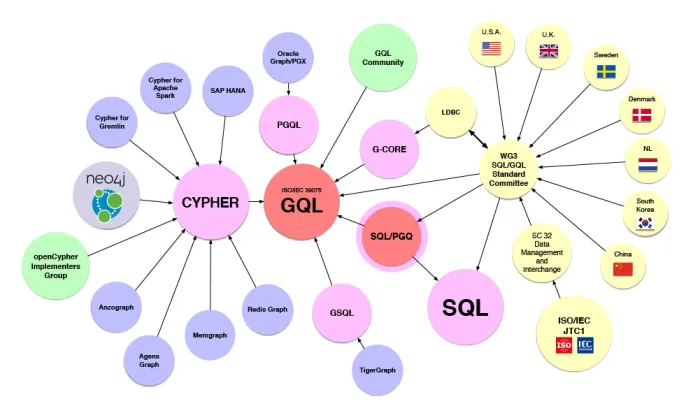
Graph querying can be a bit of a challenging landscape to initially get your head around; after all, there is SPARQL, PGQL, GQL, and if you come from a Neo4J background, you’ll be most familiar with Cipher/OpenCipher. Rather than try to address this here, there is a handy blog here, and the following diagram from graph.build.
MCP (Model Context Protocol) has really taken off as a way to amplify the power of AI, providing tools for utilising data to supplement what a foundation model has already been trained on, and so on.
With the rapid uptake of a standard and technology that has been development/implementation led aspects of governance and security can take time to catch up. While the use of credentials with tools and how they propagate is well covered, there are other attack vectors to consider. On the surface, it may seem superficial until you start looking more closely. A recent paper Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions highlights this well, and I thought (even if for my own benefit) to explain some of the vectors.
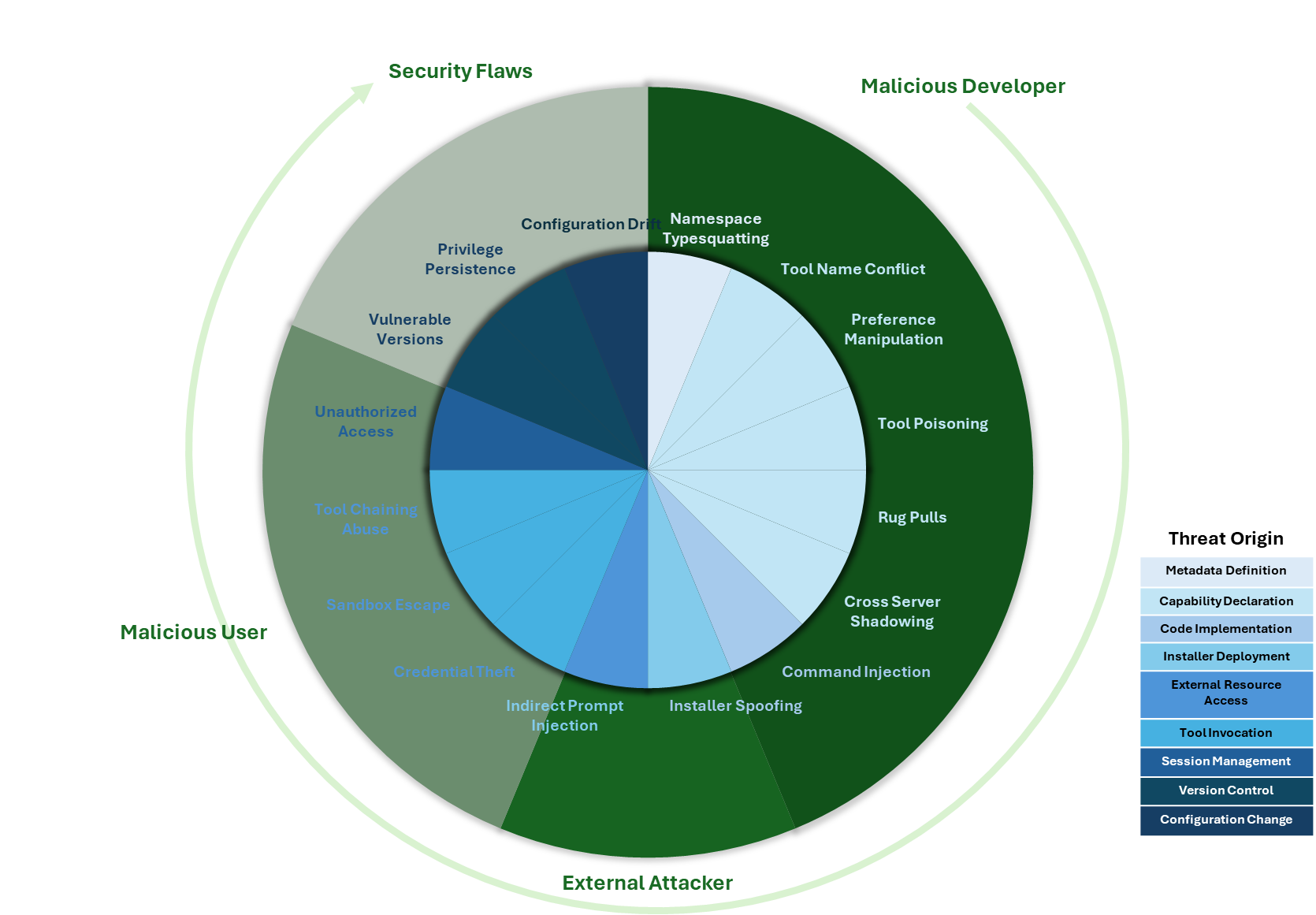
I’ve also created a visual representation based on the paper of the vectors described.
The inner ring represents each threat, with its color denoting the likely origin of the threat. The outer ring groups threats into four categories, reflecting where in the lifecycle of an MCP solution the threat could originate.
I won’t go through all the vectors in detail, though I’ve summarized them below (the paper provides much more detail on each vector). But let’s take a look at one or two to highlight the unusual nature of some of the issues, where the threat in some respects is a hybrid of potential attack vectors we’ve seen elsewhere. It will be easy to view some of the vectors as fairly superficial until you start walking through the consequences of the attack, at which point things look a lot more insidious.
Several of the vectors can be characterised as forms of spoofing, such as namespace typosquatting, where a malicious tool is registered on a portal of MCP services, appearing to be a genuine service — for example, banking.com and bankin.com. Part of the problem here is that there are a number of MCP registries/markets, but the governance they have and use to mitigate abuse varies, and as this report points out, those with stronger governance tend to have smaller numbers of services registered. This isn’t a new problem; we have seen it before with other types of repositories (PyPI, npm, etc.). The difference here is that the attacker could install malicious logic, but also implement identity theft, where a spoofed service mimics the real service’s need for credentials. As the UI is likely to be primarily textual, it is far easier to deceive (compared to, say, a website, where the layout is adrift or we inspect URIs for graphics that might give clues to something being wrong). A similar vector is Tool Name Conflict, where the tool metadata provided makes it difficult for the LLM to distinguish the correct tool from a spoofed one, leading the LLM to trust the spoof rather than the user.
Another vector, which looks a little like search engine gaming (additional text is hidden in web pages to help websites improve their search rankings), is Preference Manipulation Attacks, where the tool description can include additional details to prompt the LLM to select one solution over another.
The last aspect of MCP attacks I wanted to touch upon is that, as an MCP tool can provide prompts or LLM workflows, it is possible for the tool to co-opt other utilities or tools to action the malicious operations. For example, an MCP-provided prompt or tool could ask the LLM to use an approved FTP tool to transfer a file, such as a secure token, to a legitimate service, such as Microsoft OneDrive, but rather than an approved account, it is using a different one for that task. While the MCP spec says that such external connectivity actions should have the tool request approval, if we see a request coming from something we trust, it is very typical for people to just say okay without looking too closely.
Even with these few illustrations, tooling interaction with an LLM comes with deceptive risks, partially because we are asking the LLM to work on our behalf, but we have not yet trained LLMs to reason about whether an action’s intent is in the user’s best interests. Furthermore, we need to educate users on the risks and telltale signs of malicious use.
Attack Vector Summary
The following list provides a brief summary of the attack vectors. The original paper examines each in greater depth, illustrating many of the vectors and describing possible mitigation strategies. While many technical things can be done. One of the most valuable things is to help potential users understand the risks, use that to guide which MCP solutions are used, and watch for signs that things aren’t as they should be.
's Blog")





You must be logged in to post a comment.