There’s a growing narrative that Agentic AI and “vibe coding” (AI-assisted development is probably a better term) signal the end of SaaS, what some are calling ‘SaaS-pocalyse‘, as reflected by share price drops with some SaaS vendors.
The reality is more nuanced. SaaS vendors are being pulled in multiple directions:
Pressure to invest heavily in AI to accelerate productivity and efficiency
Fear of disruption from AI-native startups
Uncertainty over whether AI is a bubble
Broader economic caution from customers, given the wider economic disruption
Net result: share prices have been dropping rapidly. But importantly, this doesn’t necessarily reflect a collapse in demand—particularly among larger vendors. As Jakob Nielsen has suggested, what we’re more likely to see is commodification (see here) not collapse.
Jakob also pointed out AI is really disrupting approaches to UX, both in how users might approach apps and how user experience is designed.
So what happens to SaaS?
There are a few things emerging I believe …
Vendors incorporating AI into products as they drive to provide more clear value than vibe coding/home brewing your own solution. A route that Oracle have been taking with the Fusion SaaS products.
Emphasis on mechanisms to make it easier for customers to add their differentiators to the core product.
Some vendors are likely to retrench into pure data-platform thinking. But a lot of businesses don’t buy platforms (a platform buy is an act of faith that it can enable you to address a problem); many want to buy a solution to a problem, not a platform, and another 6 months of not knowing if there will be a fix.
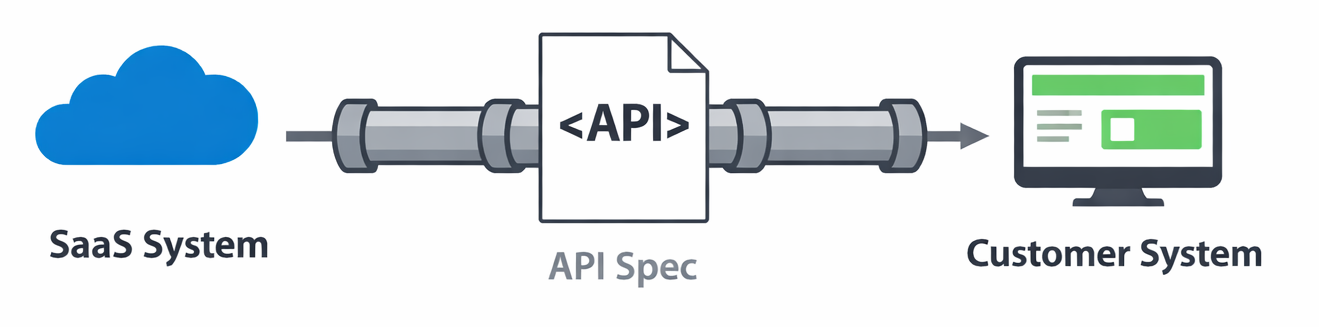
So what does this mean for APIs?
Well, APIs are becoming ever more important, but in one of several ways:
Classic API value
Having good APIs with all the support resources will make it easier to bolt on customer differentiators, as a good API (not just well coded) from design to documentation, SDKs, etc., will mean that it will be easier for AI to vibe code, or to use it agentically through MCP, etc.
You’ll need the APIs even more, since they are the means by which you protect data, IP, and/or your data moat, as some have described it.
The other approach, if people retrench SaaS to a more Platform approach, is the risk of just exposing the underlying database. If you’ve worked with an organisation that has an old-school ERP (for example, E-Business Suite) where you’re allowed legitimate access to the schema, you will probably have seen one or more of the following problems:
Unable to upgrade because the upgrade changes the underlying schema, which might break an extension
There are so many extensions that trying to prove that nothing will be harmed by an upgrade is a monumental job of testing – not only on a functional level, but also performance etc. what we have also seen as once people are on this slippery slope, the fear to stop and change tack is too much, often too politically challenging, to hard to make the ROI case.
Feature velocity on the solution slows down because the vendor has to be very careful to ensure changes are unlikely to break a deployment. Completely undermining the SaaS value proposition.
Bottom line, these issues all revolve around the fact that, because someone is using an application schema directly, there is an impediment to change (a few examples are here). As an aside, vendors like Oracle have long provided guidance on tailoring products such as CEMLIs.
There is an argument that some may make here, that making your extensions agentic will solve that, but there are flaws to that argument we’ll come back to.
APIs to ensure data replication
The alternative approach is to provide data replication, batches if you’re old school or streaming for those who want almost immediate data to match data states. In doing so, the SaaS solution now has the freedom (within certain limits) to change its data model. We just have to ensure we can continue to meet the replication contract. This is what Fusion Data Intelligence does, and internally, there are documents that Oracle Fusion applications must adhere to. While this documentation is not a conventional API, it has all the relevant characteristics.
Using APIs for data replication doesn’t always register with people. Which is probably why, despite the popularity of technologies like Kafka, Asynchronous APIs don’t have the impact of the Open API Spec. But the transition of data from one structure to a structure that clients can access and depend upon, not to change, is still a contract.
In the world of Oracle, we would do this using a tool such as GoldenGate (Debezium is an example of an open-source product). Not only are we sharing the data, but we’re also not exposing data that might represent or illustrate how unique IP is achieved, or that is very volatile as a result of ongoing feature development.
There be dragons
Let’s step back for a moment and look at the big picture that is driving things. We want the use of AI and LLMs as they give us speed because we’re able to do things with a greater level of inherent flexibility and speed. That speed essentially comes from entrusting the LLM with the execution details, which means accepting non-determinism as the LLM may not apply the same sequence of steps every time the request is made. At the same time, any system (and particularly software) is only of help if it yields predictable in outcomes. We expect (and have been conditioned) to see consistency, if I give this input, I get this outcome – black box determinism if you like.
So, how can we achieve that deterministic black box? Let’s take a simplistic view of a real-world scenario. A hospital is our system, our deterministic behaviour expectations is sick and hurt people go in, and the system outputs healed and well people. Do we want to know how things work inside the black box? Beyond knowing the process is affordable, painless, caring and quick, then not really.
So how does a hospital do this? We invest heavily in training the tools (medical staff, etc.). We equip them with clearly understood, purposeful services (a theatre, patient monitors, and data on medications with clearly defined characteristics). The better the hospital understands how to use the services and data, the better the output. We can change how a hospital works, through its processes, training and equipment. Executed poorly, and we’ll see an uptick in problems
There is no escaping the fact that providing any API requires thought. Letting your code dictate the API can leave you boxed into a corner with a solution that can’t evolve, and even small changes to the API specification can break your API contract and harm people’s ability to consume it.
It is true that an LLM prompt can be tolerant of certain changes. But, it cuts both ways, poor API changes (e.g attributes and descriptions mismatching, attribute names are too obscure to extract meaning) can result in the LLM failing to interpret the intent from the provider side, or worse the LLM has been producing the expected results, but for unexpected reasons, as a result of small changes this may cause the LLM to start getting it wrong.
This leads to the question of what this means for application APIs? It’s an interesting question, and it’s easy to jump to the assumption that APIs aren’t needed. But, in that direction lie dragons, as the expression goes.
If we approach things from an API first strategy, the API and its definition are less susceptible to change, whether the API definition is implemented using an agent, vibe coded or traditionally developed, the contract will give us some of that determinism.
APIs further benefits
With the challenges and uncertainties mentioned in the world of SaaS, having good APIs can offer additional value, aside from the typical integration value, a good API Gateway setup, and if customers are vibe coding their own UIs from your APIs you’ll be able analyse patterns of usage which will still give some clues as to customer use cases, and which parts of the product are most valuable, just as good UI embedded analytics and trace data can reveal.
Final thought
If there is an existential threat to SaaS, it won’t be solved by abandoning structure. It will be addressed by:
making data accessible
enabling extension
and doubling down on well-designed APIs
In an agentic world, APIs aren’t obsolete. They’re the thing that stops everything from falling apart.
A number of books on the use of LLMs demonstrate how to generate queries against a table from natural language. There is no doubt that providing an LLM and the definition of a simple database and a natural language question, and seeing it provide a valid result is impressive.
The problem is that this struggles to scale to enterprise scenarios where queries need to run on very large databases with tens, if not hundreds, of tables and views. Take a look at the results of the evaluation and benchmarking frameworks like Bird, Spider2, NL2SQL360, and others.
So why do we see a drop in efficacy between small use cases and enterprise systems. Let’s call out the headline challenges you may run into…
The larger the database schema, the more tokens we use just to describe it.
Understanding how relationships between tables work isn’t easy – do we need SQL to include a join, union, or nested queries?
Which tables does the LLM start with?
Does our natural language need the LLM to perform on-the-fly calculations or transformations (for example, I ask for data using inches, but data is stored using millimeters)?
When the entity needs to use attributes that contain names (particularly people, places, chemicals, and medicines), the queries will fail, as there are often multiple spellings and truncations of names.
Does the LLM have permissions to access all the schema (enterprise systems will typically have data subject to PII).
Does this mean that NL2SQL, in practice, is a bust? Not necessarily, but it is a lot harder than it might appear, and how we apply the power of LLM’s may need to be applied in more informed and targeted ways. But we should ask a few questions about the application of LLMs that may impact tolerance to issues…
Will users understand and tolerate a degree of risk and the possibility of an error resulting from hallucination? It’s just like using a calculator for performing calculations – an error in the keying sequence or a failure to apply mathematical precedence, and the result will be wrong, but do you look at the answer and ask yourself whether this is in the right ‘ballpark’? For example, 4 + 2 x 8, if you simplify to 6 x 8, you’ll get the wrong result, as multipliers have precedence over addition, so we should perform 2 x 8 first. If there is no tolerance for error, you need your solution to be completely deterministic, which rules out the use of LLMs.
More generally, will we tolerate SQL that is not performance-optimized? As we’re dealing with a non-deterministic system, we can’t anticipate all the possible indices that might help or other optimizations that could improve the query. If you’re thinking of simply creating many indexes to mitigate risk, remember that maintaining indexes comes at a cost, and the more indexes the SQL engine has to choose from, the harder it has to work to select one.
What level of ‘explainability’ to the answer does the user want? Very few users of enterprise systems will want to have an answer to their questions explained by providing the SQL, and in the world of SaaS, we don’t want that to happen either.
The last dimension is: if a user submits a question prematurely or with poor expression, do we really want to return hundreds or hundreds of thousands of records?
In addition to these questions, we should look at the complexity of our database. This can be covered using several metrics, such as:
NA – Number of Attributes
RD – Referential Degree (the amount of table cross-referencing)
DRT – Depth Relational Tree (the number of relational steps that can be performed to traverse the data model)
The complexity score indicates how hard it will be to formulate queries; in other words, the LLM will have to work harder and, as a result, be more susceptible to errors. So, if we want to move forward with NL2SQL then we need to find a means to reduce the scores.
If you’d like to understand the formulas and theory, there are papers on the subject, such as:
How we respond to these questions will demonstrate our tolerance for challenges and our ability to drive enterprise adoption. Let’s look at some possible strategies to improve things.
Moving forward
One step forward is that each attribute and table can be described; this is essential when using shortened names and acronyms. Such schema metadata can be further extended by describing the relationships and purposes of tables, and even advise the LLM on how to approach common questions, start with table x when being asked about widgets, for example. In many respects, this is not too dissimilar to how we should approach APIs. The best APIs are clearly documented, have consistent naming, and so on.
We can use the LLM to analyse the question and use the result to truncate the provided schema details. For example, in an ERP system, we could easily generate natural-language questions about a supplier or monthly operating costs. But reducing the schema by excluding details from supplier-related tables will narrow the LLM’s scope and, therefore, reduce the likelihood of getting details wrong. This is no different from addressing an exam question and taking a moment to strike out redundant information, as it is noise. You could say we’re removing confounding variables. This idea could be taken further by restricting agents to only working with specific subdomains within the data model.
We can clean up questions. When names are involved, we can use standard language models to extract nouns and their types, then look them up before we formulate an SQL statement. If the question relates to a supplier name, we can easily extract it from the natural-language statement and determine whether such an entity exists. This sort of task doesn’t require us to use powerful, clever foundational LLMs; there are plenty of smaller language models that can do this.
Inject context from the UI
Ideally when a natural query is provided, the more traditional parts of the UI are showing the data, the user can navigate through in traditional manner – replacing years of UI use with a blank conversation page is going to really limit the users understanding of what is available in terms of data and the relationships that already exist, I’ve mentioned this before – Challenges of UX for AI. Assuming that we have something more than a blank conversation window, there is plenty of context to the natural language input. Let’s ensure we’re providing this in a rich manner; this could be more than just the fields on the screen, but associated attributes. For example, if the UI is showing a table, then identifying the entities or filters applied may well help.
Simplifying the schema
Most of our systems are not designed to support NL2SQL, but for core processes that demand considerations, such as frequently occurring queries that are efficient, even more importantly, so that we don’t have issues relating to data integrity. Unless you’re fortunate to be working with a greenfield and keeping the data model simple so processes like NL2SQL have an easy time, we’re going to need to take advantage of database techniques to try to simplify the schema (at least as the NL2SQL process sees it). The sort of things we can do include:
simplify with views
We can join tables and denormalize table structures, such as supplier and address, for example. Navigating table relationships is one of the biggest risks in SQL processing.
Use virtual columns so we can offer data in different formats, such as inches and millimetres, so the LLM doesn’t need to apply unnecessary logic, such as transforming data values. Providing the calculation ourselves means we have control over issues such as precision.
Exclude columns that your NL2SQL does not require. For example, if each table has columns that record who made a change and when, is that needed by the LLM?
Synonyms and other aliasing techniques
We can use synonyms to represent the same tables or columns, enabling us to map question entities to schema tables and columns. This can really help overcome specialist column names in a schema that the LLM is less likely to resolve.
We can also use this to disambiguate meaning; for example, in our ERP, an orders table could have a column called sales. In the context of orders, that would be better expressed as sales-quantity. But then, in the accounting ledger, when we have a sales attribute, that really means sales value.
Simplifying through an Ontology and Graphs
We can model our data and the relationships using an ontology. This isn’t a small undertaking and can bring disruptions of its own. Using an ontology affords us several benefits:
Ontology can drive consistency in our language and its meaning.
An ontology in its pure form will capture the types of objects (entities), their relationships to other entities, and their connections to concepts.
We have the option to exploit standards to notate the ontology in a implementation independent manner.
Applying an ontology allows us to describe the objects, attributes, and relationships in our data model using a structured language. For example supplier has an invoicing address. One key is that we’ve abstracted away how the data is stored (some might refer to this as the physical model, but I hedge on that, as there is a whole layer of science in data-to-storage hardware).
To get to grips with ontology and how we can use it in practice, we need some familiarity with concepts such as Knowledge Graphs, OWL, and RDF. Rather than explaining all these ideas here, here are some resources that cover each technology or concept.
To get to grips with ontology and how we can practically use it, we need some familiarity with concepts such as Knowledge Graphs, OWL, and RDF. Rather than explaining all these ideas here, here are some resources that cover each technology or concept. We’ve added some references for this below.
By modelling our data this way, we make it easier for the LLM by describing our entities and relationships, and, importantly, the description makes it much easier to infer and understand those relationships.
The step up using an ontology gives us the fact that we can express it with a Graph database. We can describe the ontology using graph notation (our entities are objects connected by edges that represent relationships; e.g., a supplier object and an address object are connected by an edge indicating that a supplier has an invoicing address. When we start describing our schema this way, we can begin to think about resolving our question using a graph query.
Not only do we have the relationship between our entities, but we can also describe entity instances with the relationship of ‘is a ‘, e.g., Acme Inc is a supplier.
But, before we start thinking, this is an easily solvable problem; there are still some challenges to be overcome. There is a lot of published advice on how to approach ontology development, including not extrapolating from a database schema (sometimes referred to as a bottom-up approach). If you develop your ontology from a top-down approach, you’ll likely have a nice logical representation of your data. But, the more practical issue is that we can’t convert our existing ERP schema to a fit the logical model, or impose a graph database onto our existing solution; that has horrible implications, such as:
Our existing data model will, even with abstraction layers, affect our application code (yes, the abstractions will mitigate and simplify), but those abstractions will need to be overhauled.
Existing application schemas reflect a balancing act of performance, managing data integrity, and maintainability. Replacing the relational model with a Graph will impact the performance dimension because we’ve abstracted the relationships.
There is also the double-edged challenge of a top-down approach that may reveal entities and relationships we should have in our ERP that aren’t represented for one reason or another. I say double-edged, because knowing the potential gap and representation is a good thing, but it may also create pressure to introduce those entities into a system that doesn’t make it easy to realize them.
If you follow the guidance on developing an Ontology from the research referenced by NIST, which points to defining ontologies in layers and avoiding drawing on data models.
There is also the challenge of avoiding the ontology from imposing an enterprise-wide data model, which slows an organization’s ability to adapt to new needs quickly (the argument for microservices and schema alignment to services). While the effective use of an ontology should act as an accelerator (we know how to represent data constructs, etc.) within an organization that is more siloed in its thinking, it could well become an impediment. Eric Evans’ book Domain Driven Design tries to address indirectly.
Graphs – the magic sauce of ontology and its application
With a schema expressed as a graph (tables and attributes are nodes, and edges represent relationships), we can query the graph to determine how to traverse the schema (if possible or practical) to reach different entities. If the relational schema’s details can be enriched with strong semantic meaning in the relationships, we get further clues about which tables need to be joined. We say practical because it may be possible to traverse the schema, but the number of steps can result in a series of joins that generate unworkable datasets.
We could consider storing not just the schema as a graph, but also the data. There are limits when the nodes become records, and the edges link each node; as a result, data volume explodes, particularly if each leaf node is an attribute. Some graph databases also try to manage things in memory – for multimillion-row tables, this is going to be a challenge.
Some databases that support a converged model can map queries, schemas, and data across the different models. This is very true for Oracle, where services exist that allow us to retrieve the schema as a graph (docs on RDF-based capabilities), translate graph queries (SPARQL / GQL) into relational ones, and so on. The following papers address this sort of capability more generally:
One consideration when using graph queries is the constraints imposed by meeting data manipulation needs, since most relational database SQL provides many more operators.
Ontology more than an aide to AI
A lot of research and thought pieces on ontology have focused on its role in supporting the application of AI. But the concepts as applied to IT and software aren’t new. We can see this by examining standards such as OWL and RDF. Ontology can support many design activities, such as developing initial data models (pre-normalization), API design, and user journey description. The change is that these processes implicitly or indirectly engage with ontological ideas. For example, when we’re designing APIs, particularly for graph queries, we’re thinking about entities and how they relate. While we tend to view relationships through the CRUD lens, this is a crude classification of the relationship that exists.
Getting from Natural Language to the query
This leads us to the question of how to translate our natural language question into a Graph query without encountering the same problems. This is a question of understanding intent; the focus is no longer to jump to prompting for SQL generation, but to extract the attributes that are wanted by examining the natural language (we can even look to do this with smaller models focusing on language), and tease out the actual values (keys) that may be referenced. With this information, we can determine how to traverse the schema and potentially generate the query. If we can’t make that direct step with the graph (we may be asked to perform data manipulation operations that graph query languages aren’t designed for), relational databases offer a wealth of DML operators that graph query languages lack. We can now provide more explicit instructions to the LLM to generate SQL. To the point, our prompt for this step could look more like a developer prompt. Of course, with these prechecks, we can also direct the process to address ambiguities, such as matching the NL statement to the schemas’ attributes that should be involved.
As you can see through the use of graph representations of our relational data, we can look to move the LLM from trying to reason about complex schemas to examining the natural language, providing information on its intent, and then directing it to generate a formalized syntax – all of which leans into the strengths of LLMs. Yes, LLMs are getting better as research and development drive ever-improving reasoning. But ultimately, to assure results and eliminate hallucination, the more we can push towards deterministic behaviour, the better. After all, determinism means we can be confident that the result is right for the right reasons, rather than getting things right, but that the means by which the answer was achieved was wrong.
Growing evidence that graph is the way to go
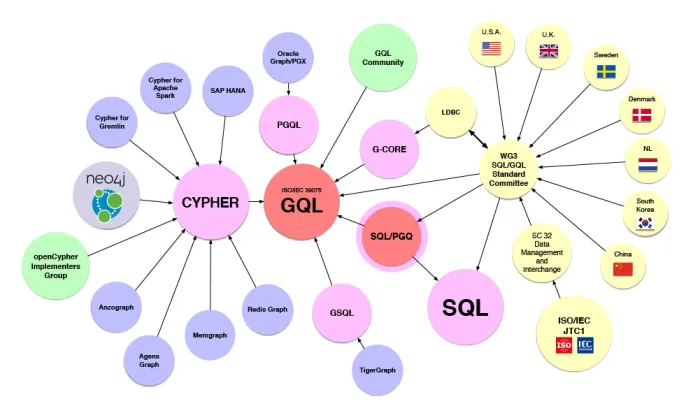
This blog has been evolving for some time, since I started to dial into the use of ontologies and, more critically, graphs. I’ve started to see more articles on the strategy as a way to make NL2SQL work with enterprise schemas. So I’ve added a few of these references to the following useful resources.
Graph querying can be a bit of a challenging landscape to initially get your head around; after all, there is SPARQL, PGQL, GQL, and if you come from a Neo4J background, you’ll be most familiar with Cipher/OpenCipher. Rather than try to address this here, there is a handy blog here, and the following diagram from graph.build.
Now that details of the product I’ve been involved with for the last 18 months or so are starting to reach the public domain (such as the recent announcement at the UN General Assembly on September 25), I can talk to a bit about what we’ve been doing. Oracle’s Digital Government Global Industry Unit has been working on a solution that can help governments address the questions of food security.
Food security exists when people have access to enough safe and nutritious food for normal growth and development, and an active and healthy life. By contrast, food insecurity refers to when the aforementioned conditions don’t exist. Chronic food insecurity is when a person is unable to consume enough food over an extended period to maintain a normal, active and healthy life. Acute food insecurity is any type that threatens people’s lives or livelihoods.
By referencing the World Food Programme, it would be easy to interpret this as a 3rd world problem. But in reality, it applies to just about every nation. We can see this, with the effect the war in Ukraine has had on crops like Wheat, as reported by organizations such as CGIAR, European Council, and World Development journal. But global commodities aren’t the only driver for every nation to consider food security. Other factors such as Food Miles (an issue that perhaps has been less attention over the last few years) and national farming economics (a subject that comes up if you want to it through a humour filter with Clarkson’s Farm to dry UK government reports and US Department of Agriculture.
Looking at it from another perspective, some countries will have a notable segment of their export revenue coming from the production of certain crops. We know this from simple anecdotes like ‘for all the tea in China’, coffee variants are often referred to by their country of origin (Kenyan, Columbian etc.). For example, Palm Oil is the fourth-largest economic contributor in Malaysia (here).
So, how is Oracle helping countries?
One of the key means of managing food security is understanding food production and measuring the factors that can impact it (both positively and negatively), which range from the obvious—like weather (and its relationship to soil, water management, etc.) —to what crop is being planted and when. All of which can then be overlayed with government policies for land management and farming subsidies (paying farmers to help them diversify crops, periodically allowing fields to go fallow, or subsidizing the cost of fertilizer).
Oracle is a technology company capable of delivering systems that can operate at scale. Technology and the recent progress in using AI to help solve problems are not new to agriculture; in fact, several trailblazing organizations in this space run on Oracle’s Cloud (OCI), such as Agriscout. Before people start assuming that this is another story of a large cloud provider eating their customers’ lunch, far from it, many of these companies operate at the farm or farm cooperative level, often collecting data through aerial imagery from drones and aircraft, along with ground-based sensors. Some companies will also leverage satellite imagery for localized areas to complement these other sources. This is where Oracle starts to differentiate itself – by taking high-resolution imagery (think about the resolution level needed to differentiate Wheat and Maize, or spot rice and carrots, differentiate an orchard from a natural copse of trees). To get an idea, look at Google Earth and try to identify which crops are growing.
We take the satellite multi-spectral images from each ‘satellite over flight’ and break it down, working out what the land is being used for (ruling out roads, tracks, buildings, and other land usage). To put the effort to do this into context, the UK is 24,437,600,000 square meters and is only 78th in the list of countries by area (here). It’s this level of scale that makes it impractical to use more localized data sources (imagine how many people and the number of drones needed to fly over every possible field in a country, even at a monthly frequency).
This only solves the 1st step of the problem, which is to tell us the total crop growing area. It doesn’t tell us whether the crop will actually grow well and produce a good yield. For this, you’re going to need to know about weather (current, forecast, and historic trends), soil chemical composition and structure, and information such as elevation, angle, etc. Combined with an understanding of optimal crop growing needs (water levels, sun light duration, atmospheric moisture, soil types and health) – good crops can be ruined by it simply being too wet to harvest them, or store them dryly. All these factors need to be taken into account for each ‘cell’ we’re detecting, so we can calculate with any degree of confidence what can be produced.
If this isn’t hard enough, we need to account for the fact that some crops may have several growing seasons per year, or succession planting is used, where Carrots may be grown between March and June, followed by Cucumbers through to August, and so on.
Using technology
Hopefully, you can see there are tens of millions of data points being processed every day, and Oracle’s data products can handle that. As a cloud vendor, we’re able to provide the computing scale and, importantly, elasticity, so we can crunch the numbers quickly enough that users benefit from the revised numbers and can work out mitigation actions to communicate to farmers. As mentioned, this could be planning where to best use fertilizer or publishing advice on when to plant which crops for optimal growing conditions. In the worst cases recognizing there is going to be a national shortage of a staple crop and start purchasing crops from elsewhere and ensure when the crops arrive in ports they get moved out to the markets (like all large operations – as we saw with the Covid crises – if you need to react quickly, more mistakes can be made, costs grow massively driven by demand).
I mentioned AI, if you have more than the most superficial awareness of AI, you will probably be wondering how we use it, and the problems of AI hallucination – the last thing you want is a being asked to evaluate something and hallucinating (injecting data/facts that are not based on the data you have collected) to create a projection. At worst, this would mean providing an indication that everything is going well, when things are about to really go wrong. So, first, most of the AI discussed today is generative, and that is where we see issues like hallucinations. We’re have and are adopting this aspect of AI where it fits best, such as explainability and informing visualization, but Oracle is making heavy use of the more traditional ideas of AI in the form of Machine Learning and Deep Learning which are best suited to heavy numerical computational uses, that is not to say there aren’t challenges to be ddressed with training the AI.
Conclusion
When it comes to Oracle’s expertise in the specialized domains of agriculture and government, Oracle has a strong record of working with governments and government agencies from its inception. But we’ve also worked closely with the Tony Blair Institute for Global Change, which works with many national government agencies, including the agriculture sector.
My role in this has been as an architect, focused primarily on applying integration techniques (enabling scaling and operational resilience, data ingestion, and how our architecture can work as we work with more and more data sources) and on applying AI (in the generative domain). We’re fortunate to be working alongside two other architects who cover other aspects of the product, such as infrastructure needs and the presentation tier. In addition, there is a specialist data science team with more PhDs and related awards than I can count.
Oracle’s Digital Government business is more than just this agriculture use case; we’ve identified other use cases that can benefit from the data and its volume being handled here. This is in addition to bringing versions of its better-known products, such as ERP, Healthcare (digital health records management, vaccine programmes, etc.), national Energy and Water (metering, infrastructure management, etc).
The hyper scaler cloud vendors all offer Logging and monitoring capabilities. But they tend to focus on supporting their native services. If you’re aware of Oracle’s Cloud (OCI) messaging, then you’ll know that there is a strong recognition of the importance of multi-cloud. This extends not only to connecting apps across clouds but also to be able to observe and manage cloud-spanning solutions. Ultimately, most organizations want to headline observability-related views of their solutions.
Late last year, I presented these ideas, illustrating the ideas with the use of Fluent Bit and OCI’s Observability and Management products to visualize and analyze what is happening. I finally found the time to write how the very basic demo was built from a clean sheet over on the Oracle Devs blog on Medium.
This also highlights the fact that the Fluent Bit book, while I believe, once completed, will be through, can’t cover everything – and certainly not build end-to-end use cases like the Oracle Observability & Management example. To help address this, the book includes an appendix of helpful additional information, some of which I have included here, along with other content that we encounter – all of which can be found at Fluentd & Fluent Bit Additional stuff.
We’ve recently had several pieces published on other websites, so I thought we should link them together.
Here is a short piece on Ubuntu security on OCI here.
Another here (DZone) on the use of Solace for multi-cloud messaging.
We’re expecting another article to appear here in the New Year as well. Plus, the book is moving along at a very nice pace – we’ve got a separate post for that.
On the book front – watch out for the Manning and Packt festive promotions.
While this might be my home for sharing thoughts and knowledge, my domain name can work against me when it comes to new potential readers (once people have found me – it’s a fairly easy domain name to remember and get back to). That does mean I occasionally write and publish content elsewhere (Software Engineering Daily, and Medium, for example). I’ve recently written a couple of posts on DZone, the latest of which looks at how IDEs have evolved.
Today we’ve just heard that the article is on the DZone homepage (top left in the image below). If you’re a bit old school, it feels like we’ve made the front page of the national press (for the really old, it would be fair to say as a More Articles piece, it is ‘below the fold’). Go check it out here.
We could solve this with custom integrations, or we can exploit an IETF standard called SCIM (System for Cross-domain Identity Management). The beauty of SCIM is that it brings a level of standardization to the mechanics of sharing personal identity information, addressing the fact that this data goes through a life cycle.
While Oracle’s IDCS and IAM support identity management for authentication and authorization for OCI and SaaS such as HCM, SCM, and so on. Most software ecosystems need more than that. If you have personalized custom applications or COTS or non-Oracle SaaS that need more than just authentication and need some of your people’s data needs to be replicated.
The lifecycle would include:
Creation of users.
Users move in and out of groups as their roles and responsibilities change.
User details change, reflecting life events such as changing names.
Users leave as they’re no longer employees, deleted their account for the service, or exercise their right to be forgotten.
It means any SCIM-compliant application can be connected to IDCS or IAM, and they’ll receive the relevant changes. Not only does it standardize the process of integrating it helps handle compliance needs such as ensuring data is correct in other applications, that data is not retained any longer than is needed (removal in IDCS can trigger the removal elsewhere through the SCIM interface). In effect we have the opportunity to achieve master data management around PII.
SCIM works through the use of standardized RESTful APIs. The payloads have a standardized set of definitions which allows for customized extension as well. The customization is a lot like how LDAP can accommodate additional data.
The value of SCIM is such that there are independent service providers who support and aid the configuration and management of SCIM to enable other applications.
Securing such data flows
As this is flowing data that is by its nature very sensitive, we need to maximize security. Risks that we should consider:
Malicious intent that results in the introduction of a fake SCIM client to egress data
Use of the SCIM interface to ingress the poisoning of data (use of SCIM means that poisoned data could then propagate to all the identity-connected systems).
Identity hijacking – manipulating an identity to gain further access.
There are several things that can be done to help secure the SCIM interfaces. This can include the use of an API Gateway to validate details such as the identity of the client and where the request originated from. We can look at the payload and validate it against the SCIM schema using an OCI Function.
We can block the use of operations by preventing the use of certain HTTP verbs and/or URLs for particular or all origins.
Outside of my Oracle cloud-related content, we’ve just published an article on DZone. Those who follow this blog will be familiar with the article theme as it relates to the Log Simulator work. We’ve also written for Devmio – although we don’t yet know when the article will be published and whether the content will be publicly available or behind their paid firewall.
The last week or so has been the DeveloperWeek 23 Conference – in Hybrid form, with the physical event last week and online this week. Circumstances prevented me from attending physically, but yesterday I was honored with the opportunity to present virtually. My session covered the adoption of API Streaming as an alternative approach to needing to poll with APIs to get the latest data state/updates.
Just before the Christmas break, I got to record an excellent podcast with Anatolii of UNmiss. It was a great conversation about Cloud Integration, APIs, and approaches to Cloud-based integration. While I am not in a consulting role in the conventional sense, a lot of an Evangelist’s task is still to listen, understand, and, when necessary, challenge assumptions and help people understand how technologies can help address problems. This might include sketching out a journey of evolution and improvement. During the podcast, we discussed some of these ideas.
In addition to some of the practices, we’ve used. The conversation touched upon books. My books are on the sidebar, including links to Manning, who, as a publisher, I’d recommend. I’ve previously blogged some reading recommendations and previously written some book reviews which may be of interest to anyone following up.
's Blog")








You must be logged in to post a comment.