As you may have guessed from the title, the article is about how Fluent Bit can support multi-cloud use cases. As part of the introduction, I walked through some of the challenges that aren’t so obvious when operating with a multi-cloud scenario. The following diagram illustrates that.
The book is now in its final peer review process with updates also being sent to the Early Access Program as well (MEAP).
One of the benefits of using cloud providers is the potential to scale solutions to meet demand by scaling out with additional compute nodes without concern for physical capacity limits (cost considerations are smaller, but still apply). Dynamic scaling is typically driven by monitoring defined groups of nodes for CPU use and when demand hits a threshold an additional node is spun up. Kubernetes can create some more nuanced scaling configurations but this is tends to be used for microservice style solutions.
This is well and fine, but if we need to finesse the configuration to ensure multiple container instances (such as microservices) can be allowed on a single node without compromising the deployment of containers across nodes of a cluster to provide resilience things can get a lot more challenging. We also want to manage the number of active containers – we don’t want to have unnecessary volumes of containers effectively idling. So how do we manage this?
In addition to this, what if we’re using services that demand tens of seconds or even minutes to be spun up to a point of readiness – such as instantiating database servers, adding new nodes to data caches such as Coherence which will need time to clone data, and adjust the demand balancing algorithms? Likewise, for more traditional application servers. Some service calls will impact upstream configuration changes, such as altering load-balancing configurations. Cloud-native Load Balancers typically can understand node groups, but what if your configuration is more nuanced? If you’re running services such as ActiveMQ you need to update all the impacted nodes in a cluster to be aware of the new node. Bottomline is some solutions or solution parts need lead time to handle increased demand?
This points to more advanced, nuanced metrics than simply current CPU load. And possibly the scaling algorithm needs to be aware of lead times of the different types of functionality involved. So how can we advance a more nuanced, and informed scaling logic? You could look at the inbound traffic on firewalls or load balancers. But this will require a fair bit of additional effort to apply application context. For example is the traffic just getting directed to static page content? We do need to derive some context so that the right rules are impacted. Even in simple K8s only hosted solutions a cluster may host services that aren’t related to the changes in demand and need to be scaled as a result.
A use case perspective
Let’s look at this from a hypothetical use case. We’re a music streaming service. Artists can control when their music is made available, but the industry norm is 12:01am on a Friday morning. There is always a demand spike at this time, but the size of the demand spike can vary, with some artists triggering larger spikes (this isn’t directly correlating to an artist’s popularity, some smaller groups can have very enthusiastic fans) – so dynamic scaling is needed, and reactive to demand. Reporting, analytics, and payment services see cyclical bumps around the monthly financial periods. These monthly cyclic activities can also be done during quieter operating hours. So it is clear we may wish to apply logical partitioning, but for maximum cost efficiency keep everything in the same cluster. There are correlations between different service demands. Certain data services see increased demand during the demand spikes and reporting period, but ‘The bottom line is we need to not only address dynamic scaling, but tailor the scaling to different services at different times.
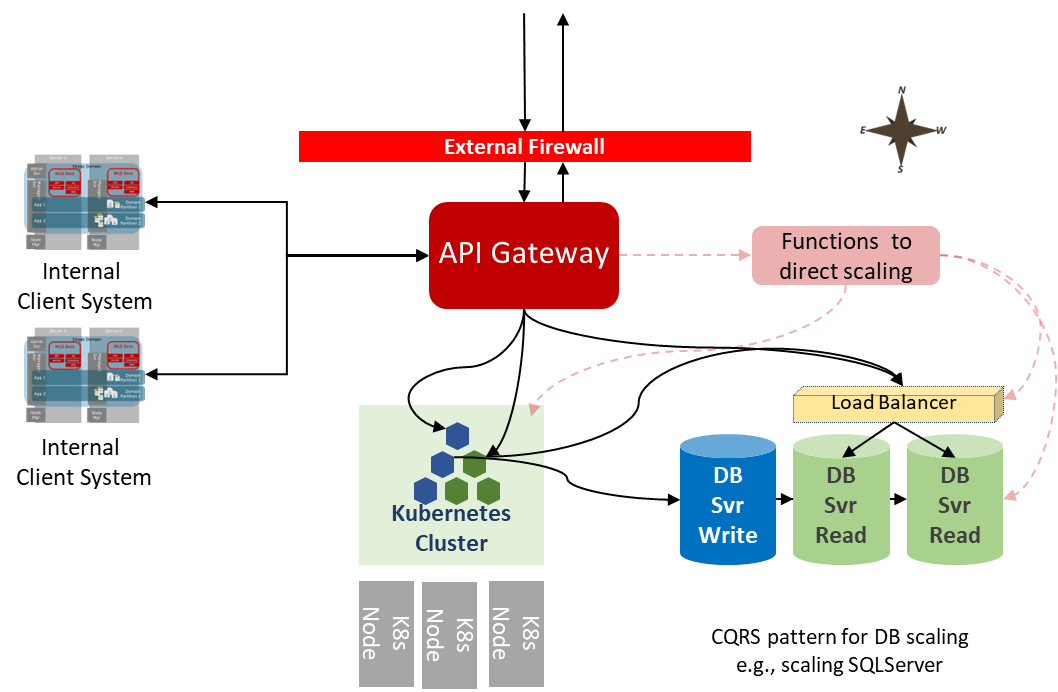
Back to our question – how do we manage the scaling? We could monitor the firewall and load balancer logs and analyze the kinds of requests being received. That would need additional processing logic to determine which services are receiving the traffic. But our API gateway is likely to have that intelligence implicitly in place as we have different API policies for the different types of endpoints. So we can monitor specific endpoints or groups of endpoints very easily – meaning we can infer the types of traffic demand and how to respond. Not only that, we may have API plans in place so we can control priority and prevent the free versions of our service from using APIs to initiate high-quality media streams. So we already have business and specific process meaning. So linking scaling controls such as KEDA (Kubernetes Event-driven Autoscaling) directly to measurements such as plans and specific APIs creates a relatively easy way to control scaling. Further, we may also use the gateways to provide a rate throttle so it’s not possible to crash our backend with an instantaneous spike. This strategy isn’t that different from an approach we’ve demonstrated for scaling message processing backends (see here and here).
Representation of how we can use the metrics from a gateway to not only support the scaling of a K8s cluster but also other cloud services
We can also use the data KEDA can see in terms of node readiness to adjust the API Gateway rate limiting dynamically as well. Either as a direct trigger from the number of active container instances or by triggering a more advanced check because we still have to address our services that need more lead time before relaxing the rate limiting.
Handling slow scaling services
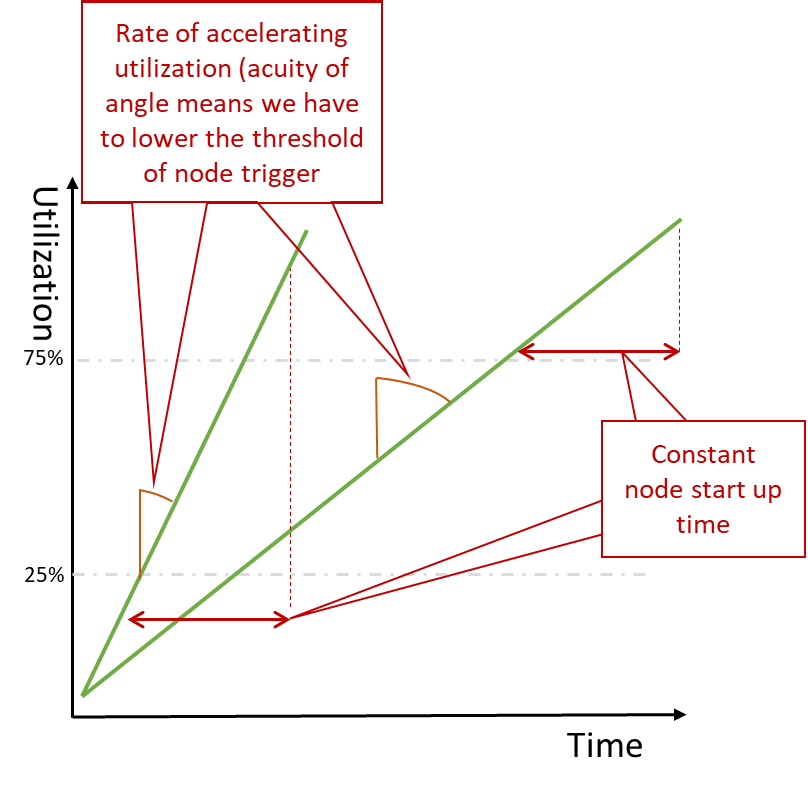
So we’ve got a way of targeting the scaling of services. But what do we do to address the slower scaling services we described? With the data dimensioned, we can do a couple of things. Firstly we can use the rate of change to determine how many nodes to add. A very sudden increase in demand and adding a node at a time will create the effect of the service performance stuttering as it scales, and all additional capacity is suddenly consumed and then scales again. Factoring in the rate of change to the workload threshold and the context of which services could generate the increased workload can be used to not only determine which databases may need scaling but also be used to adjust the threshold of workload that actually triggers the node introduction. So a sudden increase in demand on services that are known to create a lot of DB activity is then met with dropping the threshold that triggers new nodes from, say, 75% to 25% so we effectively start the nodes on a lower threshold, means the process is effectively started sooner.
With different rates of utilization growth, we can see that we need to alter the trigger threshold for launching new resources
For this to be fully effective we do need the Gateway tracking traffic both internally (East-West) and inbound (North-South). Using the gateway with East-West traffic means that we can establish an anti corruption layer.
Conclusion
Not all parts of a solution will be instantaneous in scaling – regardless of how fast the code startup cycle might be, some services have to address the need to move large chunks of data before becoming ready, e.g., in-memory databases. Some services may not have been built for the latest business demands and the ability to exploit cloud scale and dynamic scaling. Some services need time to adjust configurations.
We may also need to adjust our protection mechanisms if we’re protecting against service overloading.
Scaling capabilities that have response latency to the scaling process can be addressed by achieving earlier, more intelligent recognition of need than warning simply by CPU loads hitting a threshold. The intelligence that can be derived from implicit service context simplifies the effort in creating such intelligence and makes it easier to recognize the change. API Gateways, message queues, message streams, and shared data storage are all means that, by their nature, have implicit context.
Pushing the recognition towards the front of the process creates milliseconds or possibly seconds more warning of the demand than waiting for the impacted nodes to see compute spikes.
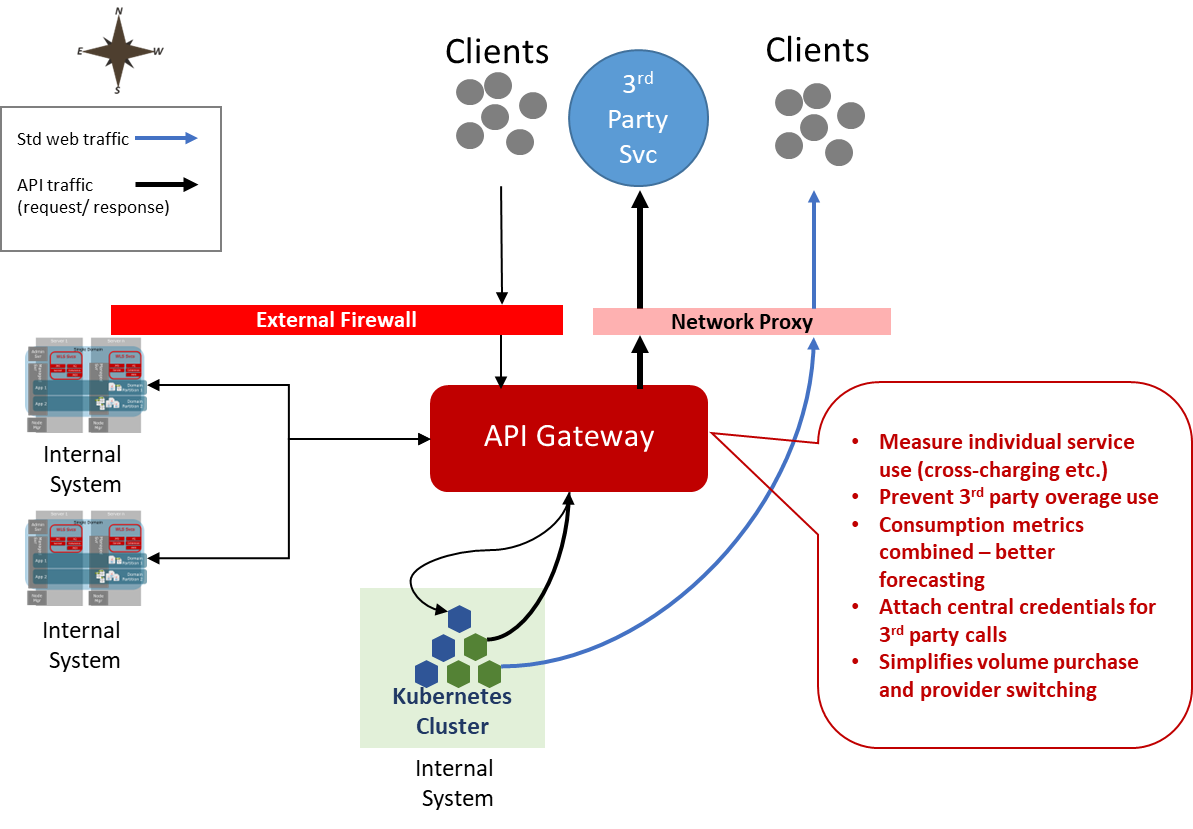
Most larger organizations route their outbound web traffic through a web proxy. The primary motivation for this is to measure where traffic is going. Log traffic for analysis to try and detect activities trying to egress data that should remain within the organization and prevent access to websites that are considered harmful in one form or another.
So why consider an API Gateway as part of an outbound traffic flow? After all, isn’t a Gateway there to protect us? Several very good reasons. Let’s look at them:
Managing the use of an external paid service. You may have multiple solutions using a third-party service – for example, an SMS service. Rather than expecting all these different calls to the external API, each having a copy of the 3rd party credentials to manage, we could use the gateway as a single point to attach the credentials.
When it comes to being charged for a service, being able to identify the requests at the API level makes it very easy to track your own consumption and forecast forward before being billed. This is really helpful if you have an agreement that provides a good price for pre-booked capacity and a higher charge for overage/capacity not pre-booked.
Economies of scale for using 3rd party services can be very powerful. But it can also present two problems.
Switching providers quickly can be difficult as multiple points of possible change
How to partition the cost of the external service across different departments if everyone is using a common account.
The first of these issues can be easily overcome using the anti-corruption layer pattern where the gateway represents the correct route so it can reformat the requests in one place to work with a different provider.
At the same time, we can more intelligently use Gateway’s metering mechanisms rather than having to implement functionality to mine the proxy’s logs.
Of course you can achieve same effect without a gateway, but you don’t get the benefits that a gateway will offer out of the box. In addition the chances are that you have already got an API Gateway running for your current North-South traffic.
Those who have been using my Logging in Action book will know that to help test the configuration of monitoring tools including Fluentd we have built a LogGenerator that can very easily play and replay logging events into a variety of destinations and formats. all written in Groovy to make the utility easy to run as a script and extend without needing to set up a proper Java development environment.
With the number of different destinations built into the script and the logic to load the source log events and format them the utility is getting rather large for a single file. Rather than letting it continue to grow as we add more destinations to pump log events too, I’ve extended the implementation so you can point to a Groovy file that implements the logic to send the log events. It only requires three simple methods to be implemented.
To demonstrate the feature we have created a custom extension and fully documented it. The extension allows you to send log events to the OCI Logging service. This includes an optional crude aggregation mechanism as sending individual log events is a little inefficient over REST. By doing this we can send synthetic or playback logs as if we’re an application in real-life to ensure that any alerting or routing for the logging works properly before we get anywhere production and do not need to run the application and induce error events.
Beyond this, we’re also thinking about creating a plugin to fire log events at Prometheus so we can send events using the Prometheus pushgateway. As a result, we can tune Prometheus’ configuration.
More improvements – refactoring the existing code
We will refactor the existing code to use the same approach which should make the code more maintainable, but the changes won’t stop the utility from working as it always has (so we won’t break out the existing output channels from the core).
We have also started to improve the code commenting – so hopefully it will make the code a bit more navigable.
One of the areas I present publicly is the use of Fluentd. including the use of distributed and multiple nodes. As many events have been virtual it has been easy to demo everything from my desktop – everything is set up so I can demo things very easily. While doing this all on one machine does point to how compact and efficient Fluentd is as I can run multiple instances concurrently it does undermine distributed capabilities somewhat.
Add to that I now work for Oracle it makes sense to use OCI resources. With that, I have been developing the scripts to configure Ubuntu VMs to set up the demo environments installing Ruby, Fluentd, and various gems needed and pulling the relevant configurations in. All the assets can be found in the GitHub repository https://github.com/mp3monster/logging-demos. The repository readme includes plenty of information as well.
While I’ve been putting this together using OCI, the fact that everything is based on Ubuntu should mean it can be run locally on VMs, WSL2, and adaptable for MacOS as well. The environment has been configured means you can still run on Ubuntu with a single node if desired.
Additional Log Destinations
As the demo will typically be run on OCI we can not only run the demo with a multinode setup, we have extended the setup with several inclusion files so we can utilize OCI services OpenSearch and OCI Log Analytics. If you don’t want to use these services simply replace the contents of several inclusion files including files with the contents of the dummy_inclusion.conf file provided.
Representation of the Demo setup
The configuration works by each destination having one or two inclusion files. The files with the postfix of label-inclusion.conf contains the configuration to direct traffic to the respective service with a configuration that will push log events at a very high frequency to the destination. The second inclusion file injects the duplication of log events to each service. The inclusion declarations in the main node Fluentd config file references an environment variable that should provide the path to the inclusion file to use. As a result, by changing the environment variable to point to a dummy file it becomes possible o configure out the use of one of the services. The two inclusions mean we can keep the store declarations compact and show multiple labels being used. With the OpenSearch setup, we have a variant of the inclusion file model where the route inclusion can reference the logic that we would use in the label directly within the sore declaration.
The best way to see the use of the inclusions is to experiment with setting the different environment variables to reference the different files and then using the Fluentd dry-run feature (more on this in the book).
Setup script
The setup script performs a number of tasks including:
Pulling from Git all the resources needed in terms of configuration files and folders
Retrieving the necessary plugins against the possibility of their use.
Setting up the various environment variables for:
Slack token
environment variables to reference inclusion files
shortcut environment variables and aliases
network (IP) address for external services such as OpenSearch
Setting up a folder for OCI tokens needed.
Setting up temp folders to be used by OCI Plugins as a file-based cache.
Feeding the log analytics service is a more complex process to set up as the feeds need to have metadata about the events being ingested. The downside is the configuration effort is greater, but the payback is that it becomes easier to extract meaningful information quickly because the service has a greater understanding of the content. For example, attributing the logs to a type of source means the predefined or default log formats are immediately understood, and maximum meaning can be retrieved from the log event.
Going to OCI Log Analytics does cut out the need for the Connections hub, which would allow rules and routing to be defined to different OCI services which functionally can help such as directing log events to PagerDuty.
Infrastructure as Code (IaC) should be treated the same way as any other code. That is to say that we should be considering configuration management, testing, regression, code quality, and coverage. We should be addressing these points for the same reasons we address them with our application code. Such as ensuring that we don’t introduce bugs as things evolve and develop, ensuring that the code is maintainable over a prolonged period etc.
The problem is that the only real way to test IaC is to run it. Particularly with the likes of Terraform where it is largely declarative rather than containing a lot of logic. This point is nicely conveyed by Yevgeniy Brikman’s presentation (below)
The presentation goes on to illustrate Terratest which has the look and feel of JUnit or any other xUnit test framework. Terratest is implemented in Golang, But to be honest, given the nature of Terraform ( largely declarative meaning it enables ideas of composition and not sophisticated logic) it means the writing of the tests isn’t going to demand anything clever like how to achieve polymorphic behavior through Go’s type structures.
While Yevgeniy focussed on testing by invoking an application on the infrastructure deployed something we’ve described though our Platform Test logic (more here). You may wish to test things further by interrogating infrastructure components. For example, do I have the right number of nodes in a dynamic group or are container or server logs going into the cloud monitoring services.
Performing such checks is very easy with OCI as it provides a Golang SDK making it very easy to write tests that can call the OCI APIs and interrogate the setup. Better still when considering whether the Terraform configuration will behave correctly to support dynamic/auto-scaling can be done easily without modifying the Terraform configurations as part of the Terratest logic can include Go API calls to temporarily modify scaling triggers or invoking code that can stimulate OCI dynamic features.
Testing App Configuration
There is an interesting question to be considered. There is a point of separation between when to use Terraform (or Pulumi and others for that matter) and tools better suited to application deployment and configuration like Ansible and Chef. Therefore should we separate the testing of these details? Maybe I am too purist but seeing local and remote execs in Terraform as these actions are very opaque and can be used to conceal things or unwittingly depend on the way Terraform handles its dependency graph.
Of course, Ansible has its test framework ansible_test and has the means to measure test coverage. So one possibility is to treat Ansible as a separate module, independently test it, and then integrate its use in the wider picture of deploying infrastructure.
Before joining Oracle I used to typically refer to a couple of key resources from Oracle – docs.oracle.com, and occasionally developer.oracle.com and ateam-oracle.com. We’d obviously use cloud.oracle.com and the main oracle.com to be able to reference published stats, success references etc. Now I’m part of the company and working in the OCI product team with an outbound side of things, I needed to gem up on all the assets that exist. So that we can help contribute, and ensure that they are up to date etc. In doing so, the number of resources available is so much more than I’d realized.
Upon reflection, this may have been from the fact we didn’t drill down deeply enough, also in part that Capgemini has its own approaches and strategies as well.
This in part is linked to the organizational structures e.g. OCI Product Management’s outbound work overlaps with the Marketing Developer Relations, for example, something that is inevitable in an organization that provides such a diverse portfolio of products.
For my own benefit, and for others to exploit, the following table summarises the different areas of information. The nature of the content and – where content overlaps or is presented in different ways.
We’ve moved this content so it can be easily revised to here (and accessible from the site menu). But also available here …
The members of this team are the ‘gurus’ of product applications. These cover a range of domains – structured in a similar way to blogs.oracle.com with different posts. These posts represent patterns and solutions to problems encountered by the team. How to, or not to implement things. This can overlap with some blogs in so far as both product blogs and A-Team blogs may address how to leverage product features.
Developer relations lead, which covers not only Oracle products but also the application of open source. By its very name, there is a strong emphasis on coding (rather than low-code) covering not just Java but .Net languages such as C#, Node, JavaScript, and so on. There is some content overlap here with the Architectural Center, where Architecture Centre provides reference solutions.
Developer relations lead, which covers not only Oracle products but also the application of open source. By its very name, there is a strong emphasis on coding (rather than low-code) covering not just Java, but .Net languages such as C#, Node, JavaScript, and so on. There is some content overlap here with the Architectural Center, where Architecture Centre provides reference solutions.
This is the Architecture Center which provides reference solutions. But these aren’t exclusive to the SaaS products (which would be easy to interpret). A lot of examples cover deploying and running open-source solutions on IaaS, for example, Drupal, WordPress, and Magento to name just a couple. A lot of these are backed up with scripts, Terraform, and code to achieve the deployment and configuration. In addition to this, there are use cases of what customers have deployed into production (known as built and deployed).
This contains a lot of free tutorials and labs that can be taken a run to implement different things, from deploying a Python with Flask solution on Kubernetes to Creating USB Installation Media for Oracle Linux with Fedora Media Writer. As you can see from these examples, the tutorials cover both Oracle products and open source. These resources interlink with the Architecture Centre and can overlap with developer.oracle.com.
This contains the code artifacts developed by Developer Relations and the Architecture Center team. So covers Reference Architectures, tutorials, and Live Labs all freely available to use.
This provides a catalog of links to the various open-source repositories available. This includes oracle-sample and devrel but also the many other projects including, but not limited to Helidon, Fn, Verrrazano, GraalVM, Apiary
This is really for the educational community (Universities, Colleges & Schools) and provides resources to take you from zero to certified skills for Java and Oracle Database.
This provides a catalog of links to the various open-source repositories available. This includes oracle-sample and devrel but also many other projects including, but not limited to Helidon, Fn, Verrrazano, GraalVM, Apiary
YouTube training videos. With multiple channels based on different technologies.
Java (OpenJDK and Oracle JDK)
A number of Oracle open-source projects have their own independent web resources as well. Helidon includes additional technical resources. The ones we know more about are : Helidon, Fn, Verrrazano, GraalVM, Apiary But it includes references to Java core language etc.
Managed by Jurgen Kress (Prod Mgr for Oracle PaaS). It acts as an aggregator for contributions from the community and shares news about what is happening within Oracle to support customers and partners in the PaaS space.
Perhaps not access usable as documentation, how-to, etc. but Podcasts can yield a lot of broad picture insights. Oracle has a range of podcasts covering a diverse range of subjects. Not all podcasts are active at any one time. But the site provides a catalog and episode list.
I’ve had some time to catch up on books I’d like to read, including Kubernetes Best Practises in the last few weeks. While I think I have a fair handle on Kubernetes, the development of my understanding has been a bit ad-hoc as I’ve dug into different areas as I’ve needed to know more. This meant reading a Dummies/Introduction to entry style guide would, to an extent, likely prove to be a frustrating read. Given this, I went for the best practises book because if I don’t understand the practises, then there are gaps in my understanding still, and I can look at more foundation resources.
As it goes, this book was perfect. It quickly covered the basics of the different aspects of Kubernetes helping to give context to the more advanced aspects, and the best practices become almost a formulated summary in each section. The depth of coverage and detail is certainly very comprehensive, explaining the background of CNI (Container Network Interface) to network-level security within Kubernetes.
The book touched upon Service Meshes such as Istio and Linkerd2 but didn’t go into great depth, but again this is probably down to the fact that Service Mesh ideas are still maturing, and you have initiatives like SMI (Service Mesh Interface still in the CNCF’s sandbox).
In terms of best practices, that really stood out for me:
Use of Taints and Tolerations for refined control of pod deployment (Allowing affinity to be controlled to optimise resilience, or direct types of pod deployment to nodes with specialist capabilities such as GPU).
There are a lot more differences and options then you might realize in terms of ingress controller capabilities, so take time to identify what you may need from an ingress controller.
Don’t forget pods can be scaled vertically with the VPA (Vertical Pod Autoscaler)as well as horizontally through the HPA.
While using a managed persistence service will make statement storage a lot easier, stateful sets will give you a very portable solution.
As with a lot of technical books I read. As I go through the book I build up a mind map of what I think are the key points. Doing so leaves me with a resource I can use as a quick reference, but creating the mind map helps reinforce the learning. So here is the mind map …
As a consultant working with clients, we always need to address security considerations for clients, their networks and data. Typically this might mean ensuring I could connect to the correct network through a VPN with the secure client software installed. Then work through a Citrix set-up for the tools we’re allowed to use.
Since the start of the pandemic, there seems to be a marked shift towards issuing consultants with customer provided laptops that have been configured and locked down. This means I can’t use the client laptop to connect to my employer’s network to interact with our own systems – making it easy to leverage our existing resources to support the customer and conversely no trust or contractual position that might allow our company devices connecting to a VPN or ring-fenced part of a network.
Interestingly there seems to have been a drift away from the ideas of BYOD (Bring Your Own Device) which may come from the fact that outside of smaller very tech-savvy organizations, BYOD can be seen as challenging to support.
As this Google Trends report shows over the last five years the trend has been until the last couple of months showing a generally downward trend. Not authoritative proof, but hints that it hasn’t accelerated as you might expect given remote working.
By the customer supplying a laptop, there is an effort to control intrusion and other security risks. But the problem is, now I have a device that I could easily take off-line and work to defeat the security setup and the client would be non the wiser, or worse it is another laptop that could ‘get lost’ or ‘stolen’ with a greater chance of having sensitive material. Every new device is without a doubt an elevated risk for the client and a cost to support (this of course is also an argument for not applying BYOD).
This isn’t the first time I’ve written about the Oracle Cloud SDK (check here), but it seems rather fitting, as some of the utilities I’ve been working on are open to the community, and #JoelKallmanDay is all about community. If you’d like to know more about #JoelKallmanDay then checkout Tim Hall’s blog here.
Oracle have provided a very rich API and then overlaid it with a number of SDKs in Python, Java etc. The SDKs immediately remove the work of creating connections and correct payloads. Taking the Python SDK for example, all I need to do is create a standard configuration file with all the necessary connection properties to my OCI instance. Then it’s simply a case of creating the correct Python object for the correct group of services wanted. Then it’s down to populating the object attributes. This is the illustration of exactly what a good SDK does. I can lean on my IDE to use the correct set and get operators. The code for establishing a connection is done for me.
What I’ve found most striking is the level of consistency in the methods provided by the SDK regardless of the service. This makes it very easy to develop functionality without needing to check every API before I can write any code. it would be easy to say, so what. But when you look at the breadth of the OCI services it becomes more impressive.
The convenience doesn’t end there. Rather than having to run your utilities from a local command line (Python means we’re pretty much OS agnostic), the Oracle Cloud shell is preconfigured with Python, OCI SDK, GitHub and FTP server and basic Linux text editors. The all amounts to the fact that you can use your scripts/tools from within the web UI of OCI. Edit your credentials file locally, push and pull any changes to the scripts from the shell and any Git repo such as GitHub.
With this insight, we just need to build that catalogue of accelerator tools to make those repetitive processes just a little easier. For example ensuring that when you tear down your manually created services all interlinked entities are deleted first (which can be troublesome with policies, groups, compartments and so on).
's Blog")

/filters:no_upscale()/articles/multi-cloud-observability-fluent-bit/en/resources/1fig1T-1713532832144.jpg)







You must be logged in to post a comment.