Tags
A while back I blogged (here) about designing in a license constrained world. Well I’ve taken that blog further and developed a supporting slide deck, to help elaborate on the thinking.
's Blog")
16 Monday Jun 2014
Posted in General, Technology
Tags
A while back I blogged (here) about designing in a license constrained world. Well I’ve taken that blog further and developed a supporting slide deck, to help elaborate on the thinking.
12 Thursday Jun 2014
Posted in Books, General, Technology
07 Saturday Jun 2014
Posted in General, Technology
Tags
Canonical, data, REST, slides, SOAP, Web Service, Web Services, WSDL
I’ve produced my own slide deck on how to adopt canonical data models into an environment that already exists using Web Services and used Slide Share for the 1st time to make a slide deck available. I hope you find it interesting
06 Friday Jun 2014
Posted in Books, General, Oracle, Technology
Tags
ebook, free, free eBook, NoSQL, Oracle, Oracle NoSQL Database, Oracle Press
 Oracle Press are currently offering a free eBook copy of Getting Started with Oracle NoSQL Database, all you need do is register at http://books.mcgraw-hill.com/ebookdownloads/NoSQL/ to get the book. I don’t know how long the offer will last, so I’d suggest getting it quickly.
Oracle Press are currently offering a free eBook copy of Getting Started with Oracle NoSQL Database, all you need do is register at http://books.mcgraw-hill.com/ebookdownloads/NoSQL/ to get the book. I don’t know how long the offer will last, so I’d suggest getting it quickly.
28 Wednesday May 2014
Posted in General, Technology
Tags
HTTP, organisation, project, RPC, Service Orientated Architecture, SOA, SOAP, Thomas Erl, WSDL
 SOA has become probably one of the most used and abused terms in IT in the last decade from assuming that implementing RPC over HTTP (rather than true REST) to the adoption of SOAP and WSDL equates to SOA, but this has been greatly written about. If you read texts such as the tombs from Thomas Erl & co (they are very substantial books and require a strong book case) then you will appreciate the goal to align services to more business centric thinking.
SOA has become probably one of the most used and abused terms in IT in the last decade from assuming that implementing RPC over HTTP (rather than true REST) to the adoption of SOAP and WSDL equates to SOA, but this has been greatly written about. If you read texts such as the tombs from Thomas Erl & co (they are very substantial books and require a strong book case) then you will appreciate the goal to align services to more business centric thinking.
The point I wanted to really home in on is not the business process thinking but actually the organisational challenges of realising SOA. In software houses or end user businesses design and development is aligned to projects or a proxy to that such as a product release. Understandable given the wealth of experience both technical and non-technical for managing projects. But projects line up behind delivering specific goals. In an organisation that is particularly delivery or time aggressive (some might say entrepreneurial) this project drive can, and istypically at the expensive of the wider software ecosystem. Building proper services requires input beyond the singular goal of a project in most cases.
This organisation and possibly cultural consideration is where most SOA texts don’t go, but probably where most help is needed to effect true SOA. Why do I say this, well consider statistics around failed projects, the amount of up front investment SOA demands – getting a handle on design patterns and technology is managable, but how do you know that the organisation and non technical aspects are not distorting or undermining your ability to deliver SOA properly.
From my personal experience I can see several things that can help (but not certainty) achieve the goal, namely:
But this is an approach is likely to create tensions between the project and its pressures and the desire to achieve a SOA goals. The question is can an alternate organisational model exist which allows for a more effective realisation of SOA ideals without the tensions as the stronger the personalities involved between architecture and project pulling to meet their goal.
It is worth also considering the additional complexity that offshoring the implementation can add in terms of organisational challenge; as an offshore 3rd party’s focus is revenue within in an engagement (offshore vendors aren’t charieties they need to make a profit as well) so they will work to be as efficient as possible; and not likely to be focused on your total SOA ecosystem of services (they may not even see the big picture you’re seeking to achieve) so building appropriate layers of decoupling and abstraction are not likely to be in their natural interests unless such sensitivities are built into the agreement and backed up by governance with appropriate levels of impact (which could be as extreme as rejecting the solution as it doesn’t match the service designs identified).
Further in some organisations the challenge can run deeper beyond IT and into the sponsoring side of the business. Let me illustrate this, organisations are ultimately broken into functions who can look at systems as belonging to a specific function ie system A is for marketing, that system B for eCommerce and so on. With that kind of system thinking and each department driving against its own goals (sounds like a project again) the overlap of services against software products is going to be challenging. For example services such as a service for ‘Customer’ information is likely to cross software solutions such as CRM (Marketing) and eCommerce can be subject to different demands as the different parts of the organisation pull in their desireddirection resulting in potential clashes (and likely blame IT for the issues that arise).

One of the few diagrams that makes reference to organisation in the context of SOA
So what is the answer? I can only offer up my experiences above, point to the fact that some organisations perhaps just are not ready for realising true SOA. I would certainly love to read a SOA book that approaches the question not from a technology perspective but that of a organisational and process view point.
23 Friday May 2014
Posted in Oracle, Technology
When it comes to understanding the range of products and how product families fit together Oracle have created some helpful block diagrams, such as the one below.

SOA / AIA Structure
This really helpful – particuarly when trying to understand potential licensing relationships. However there doesn’t appear to be an equivalent diagram (certainly not on OTN). So after a bit of navigating around OTN we have produced the following diagram:
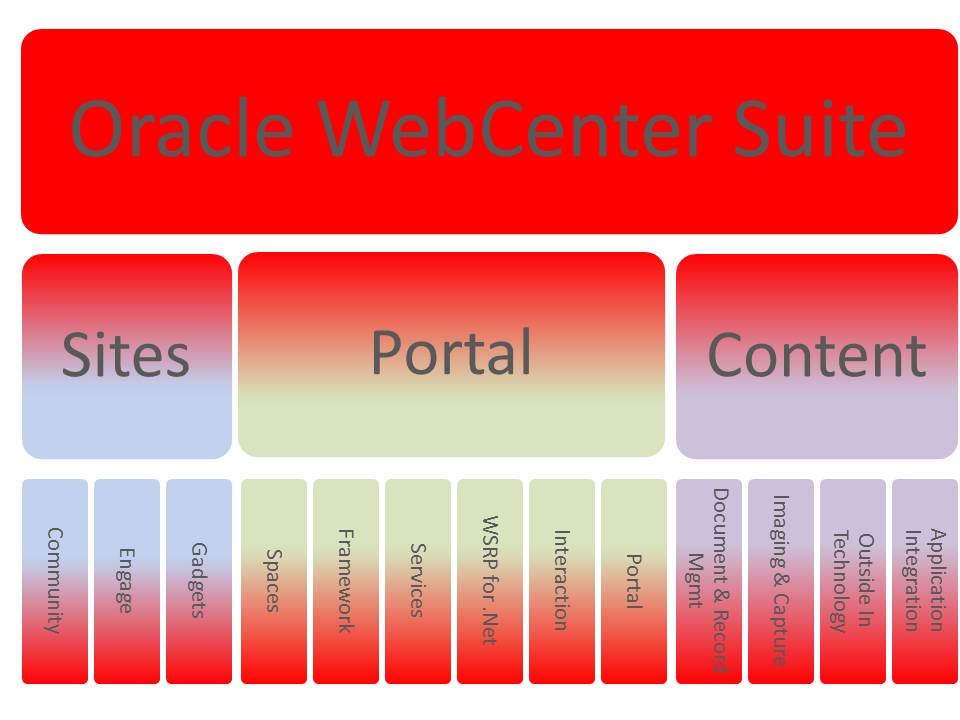
WebCentre Suite Makup
If you find it useful, help yourself but a nod would be appreciated.
05 Monday May 2014
Posted in Book Reviews, Books, Oracle, Oracle Press, Technology
Tags
Big Data, Big Data Appliance, book, Endeca, Enterprise R, Hadoop, NoSQL, ODI, Oracle, Oracle Big Data Handbook, Oracle Press
Having written several detailed reviews of Oracle Press’ Oracle Big Data Handbook (links below) I thought it useful to produce a summary. Over all is a very insightful and informative book covering the range of technologies that Oracle offers to address the ‘Big Data’ space from a number of view points such hardware with the Big Data Appliance (BDA), software with NoSQL, Enterprise R and Hadoop along with the various adapters (e.g. ODI) and existing product features that existing products make available to support the big data story and contribute to make a cohesive ecosystem. The book looks beyond the technologies classically linked to the ‘Big Data’ term to explore products such as Endeca. I like the act that the book tries to explain the rational behind some of the approaches adopted and the associated value propositions. Finally book looks at governance, maturity and architectural capabilities. All of which makes for an informative and insightful book.
The book isn’t flawless a few challenges that can make the reading a little frustrating occasionally (at least for me as I went cover to cover), for example,looking at the Big Data Appliance we seem to revisit the hardware specifications multiple times. The data governance perspective is data governance not specific to big data in my opinion. Occasionally the book seems to jump about when explaining a number of related areas which means that using the book as more a reference isn’t so easy. Don’t get me wrong these issues are hugely out weighed by the value it brings.
my detailed reviews:

Oracle Big Data Handbook
05 Monday May 2014
Posted in Book Reviews, Books, General, Oracle, Oracle Press, Technology
Tags
BDA, Big Data, book, CRAN, data mining, Endeca, ODM, Oracle, Oracle Press, Oracle R Enterprise, review, Revolution analytics, RStudio, spatial, warehouse
This is the third and final part of the review of Oracle Press’ Oracle Big Data Handbook (and last part of our detailed review – previous parts can be seen Part 1 here and Part 2 here). With the first sections having introduced the Big Data Appliance and the case for adopting an appliance, followed by an in depth look at the technologies provided on the BDA for storing data we move into the section that really delivers the pay off, namely the mechanics of converting data to information i.e. Analytics. This means this section of the book concentrates on the likes of Oracle Data Mining (ODM), Oracle R Enterprise and Endeca. The first of the chapters in this part of the book looks at different types of analytics you might need to perform for example data mining, predictive analytics, text mining and so on, the result is that the chapter does seem to flip flop between more classic data warehousing (still Big Data in terms of shear data volumes) to the more contemporary hip and trendy of ‘Big Data’ in the form of Hadoop and R. This may work nicely for a DBA/Data Scientist, but as a technologist and enterprise architect it isn’t so easy as personally I’d prefer to get a sense of each product stack then look at how they compliment/overlap. That said, after the first couple of sections where both the tools and ideas are introduced the flip/flopping is quicker making it easier to cope with, but it also makes for a sizeable opening chapter for this section of the book. But let me show you the kinds in sights that can be gained from the book.
ODM extensions are built around the common Oracle toolkits of RDBMS, SQLDeveloper and additional packages to provide powerful visual paradigms and precanned analytics functionality. Not being a data warehouse expert, I like the fact that the book takes time to describe the processes for building a data model and predictive engine and the likely paths through these steps. The books goes onto to explaining the available Excel tooling. Most of this is helped along with the context of a scenario. Given the claim of realtime capability to take a transaction and use a predictive model against the transactions values to ascertain whether the transaction is likely to be indicative of the characteristics being sought after it would have been nice for the book to provide some outline benchmarks for the scenario. Realtime could be interpreted as a second or two. Which when you’re running millions of transactions with small profit margins per transaction means using such capabilities is a also expectation. Still this doesn’t take away from the clarity of the information that is explained.

From ODM the chapter moves onto introducing the R language. What really got my attention by the book is the apparent willingness to engage with an Open Source model (given the other major players in the evolution of R – Google, Facebook, LinkedIn etc you might argue there is no choice). But the book upfront addresses the fact that Oracle hasn’t (or not yet) incorporated an R editor into SQLDeveloper or JDeveloper and the book suggests a specific tool of RStudio. Then there is the engagement with a library of R extensions (CRAN – Comprehensive R Archive Network with over 5000 extensions).

Google Trends view of Analytics Tools
All of which begs the question, what is Oracle’s value proposition in this pace. The book answers this be describing the challenges of using the Open Source edition of R (memory consumption and single threaded characteristics) and how they have addressed those by extending R into Oracle R Enterprise. In addition to these constraints Oracle’s extension recognises and works with the database governance and security layers properly. It is at this point we’re brought back to earlier focus of the BDA as the extensions allow the BDA Hadoop deployment to be used as a data source (along with Oracle RDBMS). In many respects it feels like a similar proposition to Revolution Analytics (other than the RDBMS emphasis being different). As with the Data Mining the example scenario is used to illustrate the applications of R in conjunction with Hadoop and Oracle RDBMS. To support the illustration the different additional libraries are explained (such as the Hadoop connector, RDBMS connector etc).
R enterprise doesn’t stop here, but has been integrated with PL/SQL, OBIEE and BI Publisher meaning that although some of the tools and the core solution are open source Oracle has achieved a rather rich ecosystem – a point not really called out by the book, but the presentation of the details really makes this jump out.
Still with Chapter 9 we move onto text mining for activities such as sentiment analysis and jump back to ODM with an explanation of the product’s capability in this space and the challenges that this kind of analysis presents. Which is followed by a view of the support R offers. The chapter moves onto things like Spatial analytics and so on. The later forms of analytics don’t confront the ideas of ‘Big Data’ based on the book’s opening definition of big data. That isn’t to say that a brief overview of how Oracle Spatial works and its capabilities to support ideas such as Location Intelligence isn’t interesting but I don’t see any differentiation between big data and normal patterns of use for Oracle Spatial. The examples provided such as knowing if there are patterns of location based usage, but such analysis can be done by ensuring a consistent representation of location from which you can select by a range – either a postal/zip code or by latitude and longitude for example, for which there are more cost effective tools and don’t necessitate pulling data out of a Hadoop cluster to perform such analysis. I would conceded that Oracle Spatial has an information rich data set that could be very effective, but to explore such ideas should we not be looking at ideas like that of ESRI’s integration to Hadoop (and more here) for example if Oracle offer such a capability.
Having crossed a range of technologies Chapter 10 briefly talks about IDEs, but then goes for a deeper dive into R covering the supported Open Source Edition and Enterprise Edition (ORE). The differences between the two versions and the licensing issues are well explained. Based on the description what Oracle have done to make the optimisation and ability to transparently leverage the database seems pretty impressive. The only thing to remember is by transparently moving R’s computational load into the DB is what impact on other processes. Oracle have also enabled ORE to access the predictave analytics capabilities that can reside within an Enterprise Database which are also illustrated here.
After looking at ORE’s capabilities the book moves onto its connection to Hadoop for R (Oracle R Connector for Hadoop – ORCH). ORCH provides the means to interact with HDFS along with the file system and RDBMS. The connector allows for the creating of MapReduce jobs using the R language and interacting the the job scheduler. To fully leverage these capabilities you do want to pull in CRAN libraries. The book then walks through a detailed example of using ORCH with MapReduce (including R script elements). This is then followed by a similar set of examples demonstrating direct interaction with HDFS.

Chapter 11, gives us a focus change again, this time to Endeca for Information Discovery. The book takes us through the history of Endeca and Oracle explaining the component naming – before and after the acquisition and the two dimensions of the Endeca product stack – eCommerce specific and for more general BI.
The chapter looks at the Endeca data model as it is a faceted or tagged model (i.e. all values are represented as label & value). The book emphasis’ the benefits of this model – but not downsides (needing to use the label to determine semantic meaning can have performance implications). This is important is it has implications of the flexibility to enrich data that Endeca can then leverage. Once the basic product and technicalities are examined the book actually steps back to explain the differences between BI and information Discovery and therefore the approaches to using these tools. Then onto to the tooling such as the studio, engine and integration capabilities. The book continues to build on the technical side with the classic NFRs of how to make the technology scale. We then flip back to look at a number of example use cases. Before a final jump to look at mechanics of deploying Endeca and getting some development work underway. The sequencing of the chapter sections does seem a little odd, but it does work, but trying to dive into just the technical dimensions alone probably not a practical proposition here.

Big Data governance is taken on the final chapter of the book – Chapter 12. The emphasis here is to look at the definition of Data Management (e.g. definition by Data Management Association – DAMA) and how Big Data relates to this. So the chapter walks through the key data governance factors – many of which are characterised in the diagram above for example focusing on common legislative considerations such as HIPAA, and Patriot’s Act KYC (Know Your Customer) through to EU Data Protection and UK Financial Services Act. Having a breadth wise view of Data Governance then the book starts to look at how Big Data scenarios differ from raw data and day to day data sets. The problem I have with the chapter here, that all the points being made are valid, but they’re not Big Data issues they are any data governance issues. What Big Data does is introduce technology to capture and use data in ways previously not considered so using the technologies in this way may impact declarations that you may have made to data protection registrar e.g. declare you keep customer data to enable order fulfillment but then use the data to determine effectiveness of sales channels would be an issue. But you dont have to have big data technology to create such an issue (the book itself acknowledges that you could do the analysis with older approaches but the difference is it is easier and quicker now). Having described some ‘any data’ guidance for your big data scenarios the book goes into a raft of big data scenarios in different domains and references some of the relevant legislation. If you read the chapter as just data governance it is a good reminder of the different considerations in data governance.

The final Chapter takes on architectural and road mapping considerations. A good way to conclude as this sort of thing will draw on all the preceeding chapters’ points; and this precisely how the chapter starts recapping the value proposition described up front followed the infrastructure considerations – data volumes need to process in parrallel to handle the volumes in timeframes that mean the insights can be assessed and reacted to in a meaningful manner. After the recap the book moves into a maturity model although the origins of the model aren’t clear (I’d have thought that the basis of what is presented is routed in a wider model). This naturally leads into looking at the Oracle Architecture Design Process (OADP). The details of OADP walks thought the goals and mechanics of developing your ‘As-Is’ and ‘To-Be’ architecture so you develop a transitional roadmap. The final step is obviously enabling the journey by developing the human skills necessary to perform such as journey.
Previous Reviews:
22 Tuesday Apr 2014
Posted in Book Reviews, General, Oracle, Oracle Press, Technology
Tags
adaptors, BDA, BerkeleyDB, Big Data, book, connectors, Hadoop, NoSQL, ODI, Oracle, Oracle Press, review, Sleepycat, sqoop
After an excellent start in Part 1 of Oracle Press’ Oracle Big Data Handbook (reviewed here). Part 2 moves on to looking at Apache Hadoop, Oracle’s Big Data Appliance and Oracle’s NoSQL offerings.
So chapter 3 provides a brilliant overview of Hadoop and the echo system that has been developed around it. Addressing the divergent versions of Map Reduce leading to the likes of YARN. Touching on how commericalised versions of Hadoop have been taken forward with this (such as Cloudera).

Moving onto to describe the core solution components such as Node Managers and the relationship to hardware and the use of more commodity kit rather than using nice expensive SAN technology.

So now we have good (pretty much uncoloured by Oracle) view of Hadoop. Which leads into the the next chapter (chapter 4) which looks at why Oracle have taken the approach of an Appliance (which could be seen as contrary to the previous stated adoption of commodity kit).

So as you can see Oracle woven together a set of technologies into an Exadata based platform which would not only deal with Big Data Analytics but ideally support other volume scenario needs so you’re not adding another data silo. all of which fits with Oracle’s Engineered Solutions view point. The book takes on a explains the other factors involved in the BDA design – those of commercial considerations and value propositions in relation to its customer base – very refreshing to see (rather than rationalisation through technical arguments alone).
The book addresses the challenge of why should I go to Oracle for big data? Which is well argued on the experience of very large relational deployments. Oracle’s contributions to Hadoop via Cloudera and so on. The chapter finishes with the argument around cost comparison between buying a comparable hardware solution to build your own cluster. Taking just list prices compared to HP and the hardware costs come in more or less the same, that’s before you account for the fact the Oracle price includes all the software.
Chapter 5 addresses the deployment of the BDA, explaining the configuration process, which with the combination of a tool called Mammoth (appropriate really) and the lies of Puppet seems pretty simple as a lot of the solution is preconfigured on the box ready. all of which is reasonably well explained. my only grumble is that we do seem to revisit the details of the hardware fairly regularly as the details are again presented here, although we go into a deeper dive in the configuration. One surprise that I’d not picked up on is that Oracle have made their NoSQL solution available as open source, although a little digging might contribute to why as it has links back to Sleepycat’s BerkeleyDB that Oracle acquired (more here). As the chapter move through the physical aspects of the deployment it also highlights in clear terms any constraints Oracle imposes to ensure that the whole appliance is supportable, the most significant of these areas is the advanced networking that is setup.
Chapter 5 as it moves through deployment considerations addresses the means to know that the appliance is running properly – so we’re talking about system monitoring not just of the hardware but the distributed nature of Hadoop and Map Reduce. So a brief view of the products deployed is given. Obviously this centres on the Enterprise Manager extensions, but also the component level tooling such as Cloudera’s Hadoop Manager.
Chapter 6 in many respects continues building out the view of Hadoop to describe briefly the analytics tooling both in the Oracle RDBMS, R language and data mining/discovery of Endeca. The interesting points in the chapter are about the relationship with RDBMS particularly as an enterprise data warehouse – something I’ve not seen really addressed elsewhere as the common world view seems to put Hadoop in the same camp as NoSQL which seems to be gaining the zeal and polarity that Linux vs Windows used to have when it comes to RDBMS. But I think the book makes a good case for right tool for the right job.

Oracle’s Strategic Product View
Chapter 7 starts to drill in to how the connector package offers which consider Oracle database data transfer, combining the R language with MapReduce and ODI.
The database connector aim to provide efficiency in transferring data between Hadoop and the Oracle RDBMS over say using Sqoop to transfer data to and from an Oracle database (ODI connectors, JDBC, direct OCI etc). To fully understand the explanation of how this works you do need to understand the basics of MapReduce although as the chapter progresses the relevant MapReduce operations are elaborated upon. As the chapter progresses we start being shown configuration fragments for the different connection approaches.
The final chapter of this section of the book looks at the NoSQL database in detail, starting with high level ideas such as how NoSQL relates to ACID and BASE ideas, dropping down into significant (but valuable) detail by describing how clients are kept in sync through the use of separate threads picking up data about the data partitioning (sharding). Once the key components have been well described the chapter moves onto explain how Oracle has optimized the process to make the NoSQL as performant as is possible whilst providing a solution that is elastic in nature and highly resilient but still predictable in its dynamics.
The chapter finishes off with considerations such as installation, how it integrates with Hadoop and OBIEE.
Overall, this a very informative chapter, occasionally it feels like some of the information is being repeated but in a different structure but it isn’t the end of the world, although if you’re reading from cover to cover you need to just press on.
14 Monday Apr 2014
Posted in Book Reviews, Books, General, Oracle, Oracle Press, Technology

So having written a series of detailed blog entries reviewing a couple of chapters at at time I thought it might be worth just providing a very brief review. Writing a book that provides both breadth of coverage for a very large subject area as well as meaningful depth is a very difficult trick to pull off. But the authors of this book have succeeded magnificently. The book tackles the subject of basic customization that users can perform through to in-depth feature development using the Oracle SOA stack. Not to mention reporting and analytics. The book has been written in an engaging way providing context, background and Fusion Application principles and then taking examples of how to implement the different kinds of capabilities. From this book, you should have a good grasp of what to expect and how to approach Fusion application Extension work.
As a result I’d recommend this book to Architects, Project Manager’s who want to understand what their development team should be doing and the risks of their approach. This would also form a good roadmap into the detail for developers starting out in the Fusion applications space.
Detailed reviews can be seen at:


You must be logged in to post a comment.