
Tags
AI, artificial-intelligence, development, LLM, programming, SDD, spec driven development, Technology, TOGAF
Let me start by clarifying some terminology.
an informal noun referring to the mood, atmosphere, or aura produced by a particular person, thing, or place that is sensed or felt
This is deeply at odds with the idea of software engineering, where the OED describes engineering as:
the activity of applying scientific and mathematical knowledge to the design, building, and control of structures, machines, systems, and processes
While there is a place for vibing – to explore and help test ideas, when it comes to enterprise solutions with icy, typically have large footprints, or will grow to have large footprints and high data volumes, therefore need a more disciplined approach to ensure all those non-functional considerations can be addressed, and sustained. Put it another way, would you take an artesian approach to building and maintaining a petrochemical refinery?
This is why I try to separate the idea of vibe coding from a more disciplined AI-assisted development. A name that doesn’t roll off the tongue well, but conveys the idea that the engineer is in control and can impose discipline to drive the NFRs.
Hopefully, this also helps address nuance, which is often missing in discussions about the use of AI in software engineering, which is definitely polarising viewpoints (like many things today).
Spec-driven development
Spec Driven Development (SDD) is a growing topic in the A.I. assisted development space, and growing as a reflection of the fact that LLMs are improving rapidly, best illustrated at the moment with Mythos. The basis of SDD is to help drive consistency, structure, sustainability and rigour into the AI dev process (back to vibe coding). Consistency and structure allow us to start to easily agentify or tool aspects of development.
Getting a consistent, clear explanation of what constitutes SDD isn’t necessarily straightforward, but the best definition is in an article by Birgitta Böckeler on Martin Fowler’s website. The article dives into not just a basic explanation, but also characterises the differing approaches. The article teased out three versions of the idea, which paraphrasing are:
- Spec First – very much like the old-fashioned, here are the requirements that are used to generate a first iteration of the code base. Then subsequent refinements, improvements and general evolution are introduced through successive direct code changes, and/or direct prompting of the LLM to modify different pieces, and add functionality.
- Spec Anchored – the Spec is retained for ongoing reference and maintained.
- Spec as Source – we don’t really care bout the code, we want a change, we only edit the spec. Code is almost a form of conversation memory, which prevents the LLM from recreating from scratch and producing an answer that looks a bit different, potentially resulting in API names that differ, etc.
This evolution, particularly as people move or are pushed by leadership fearing losing a competitive edge through perceived lower development velocity, increasingly towards a spec-only approach, left me thinking about the agile manifesto and its declaration:
‘we value working code over documentation‘.
While this still has to be true, as ultimately, working code delivers the value. But the heading for the documentation has to be clear, concise, and sized for LLMs’ working documentation, as that is how we get to working code. This isn’t just to bash out some instructions and unleash the LLM; it does need to be refined and iterated on (in many ways, just like a book). We should prompt the LLM to seek clarification rather than let it make assumptions. Furthermore, we need the documentation to be accurate because an LLM will exhibit childlike trust, and if it is working with misaligned content, you’re in a 50/50 position. Unleashing an LLM on your codebase may lead to the wrong outcome. Perhaps, we need to extend the Agile manifesto, with a statement like:
we value correct, accurate, clear and concise documentation over any documentation
In other words, when using an LLM in your development context, it is better to get the LLM to reverse engineer the code to create documentation of your current state (even if that is at the price of losing the original context, design ideals, requirements, etc.) than to allow the LLM to see inaccurate and poor documentation. If this new principle is true, then we need to move away from Spec first to atleast Spec anchored approach.
Given this, we should see the heart of an engineering process looking something like:
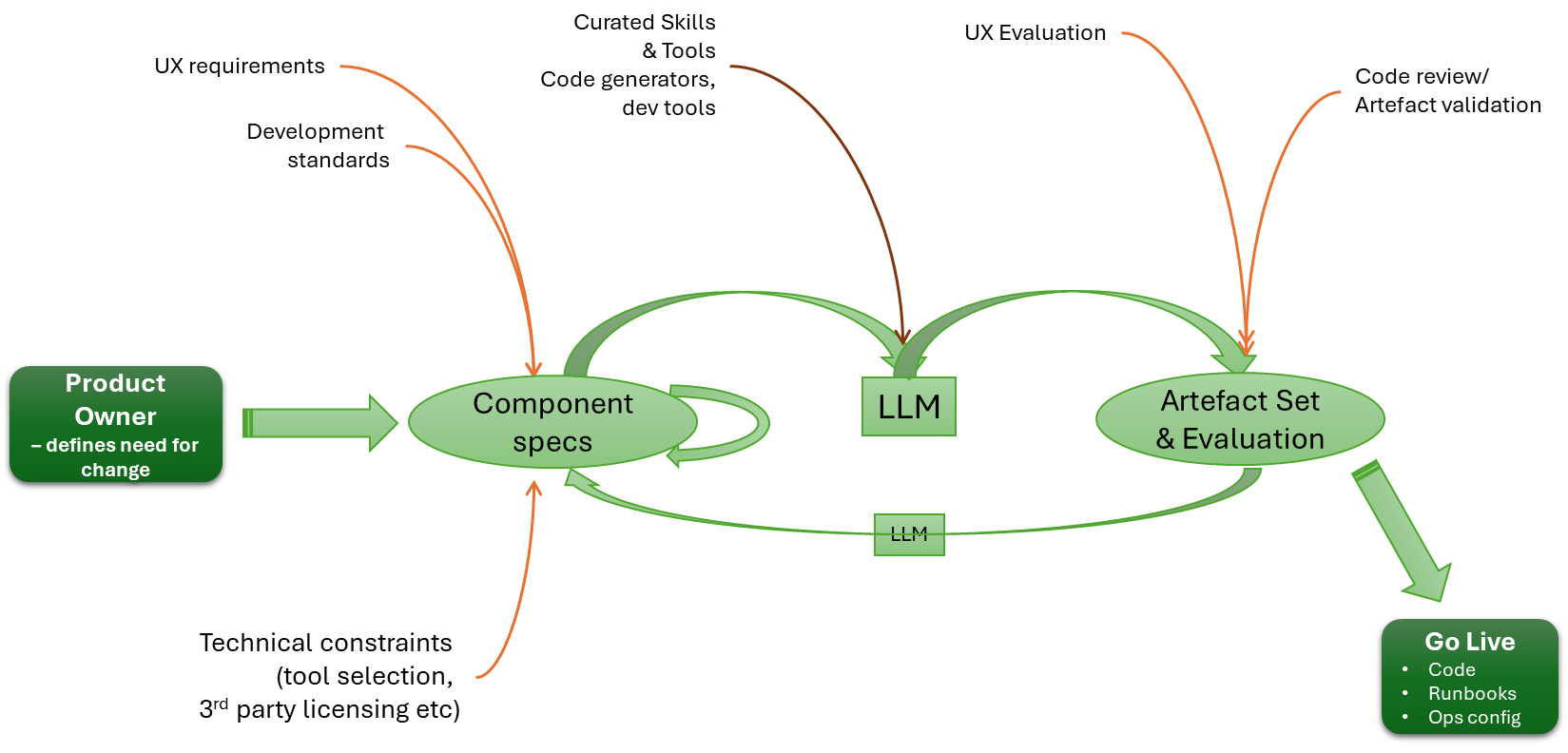
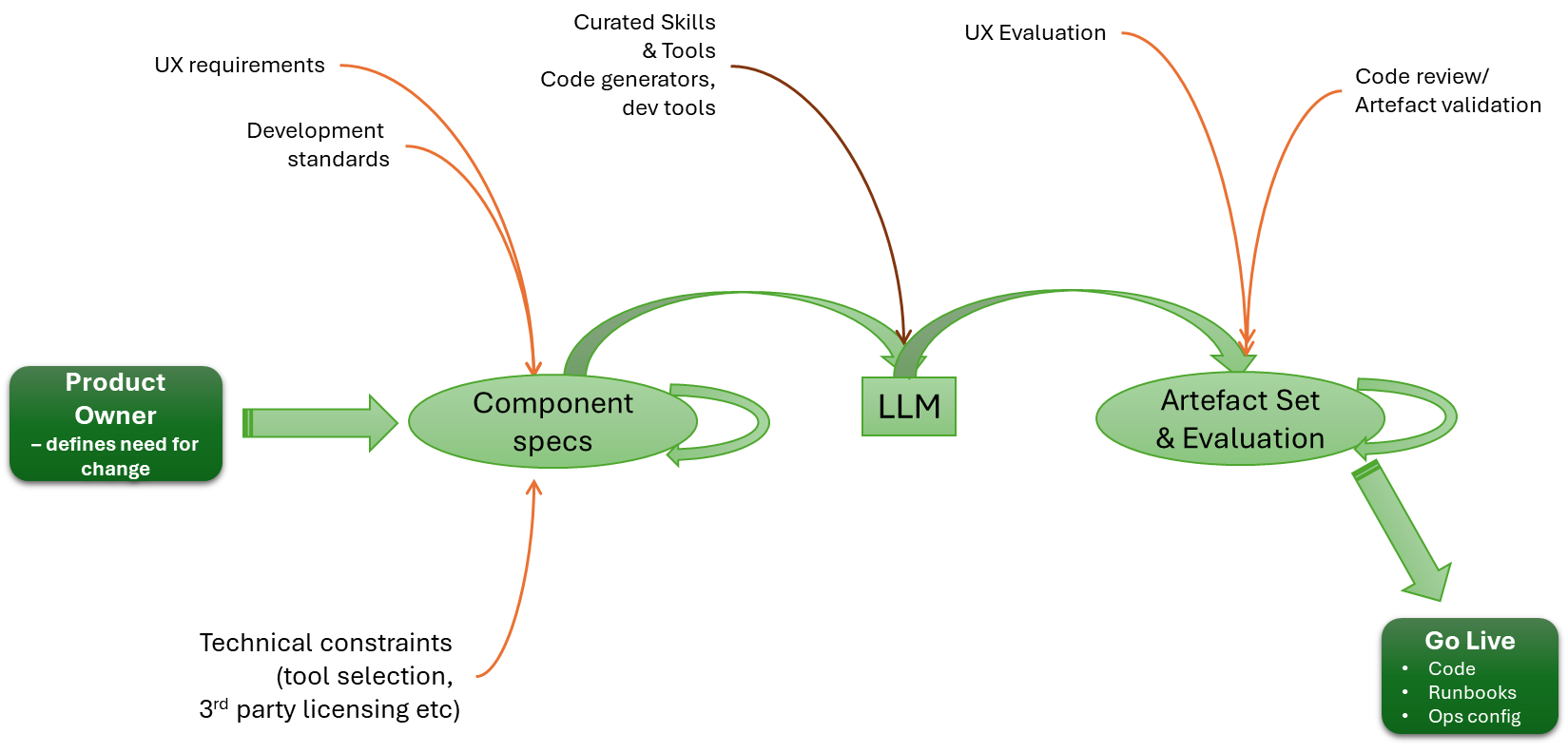
I think one of the challenges with the view of everything is that, as the Spec lead, there is an expectation that, to do it, we go from a very high-level definition straight to code. The reality is that we need the process to be more human-like. We use the LLM to take requirements and drive a high-level design. We then use the LLM to break the HLD into multiple LLDs. Importantly, we iterate on the process, until the decomposition of detail is right. The LLM cycle focuses on just one output at a time. We can certainly then use the LLM to determine consistency and integrity across all the LLDs.
From Requirements to Architectural Views
There is a natural extension to this. If we are to swing back to a document-led approach (albeit with a very different journey from document to working code), could we see increased adoption of TOGAF and other architectural frameworks? Many in the past have used such frameworks as part of the argument as to why things should be code first, as often the framework artefacts are seen as the end, rather than the process and techniques as a means to an end (i.e. we do architecture, therefore I must create a large document set, rather than we do architecture to ensure we get the details we need from code correct).
Certainly, using an LLM to help with the creation and maintenance of architectural views, including making it easier to search for and address inconsistencies across different viewpoints, without necessarily needing very prescriptive, complex, and expensive toolsets.
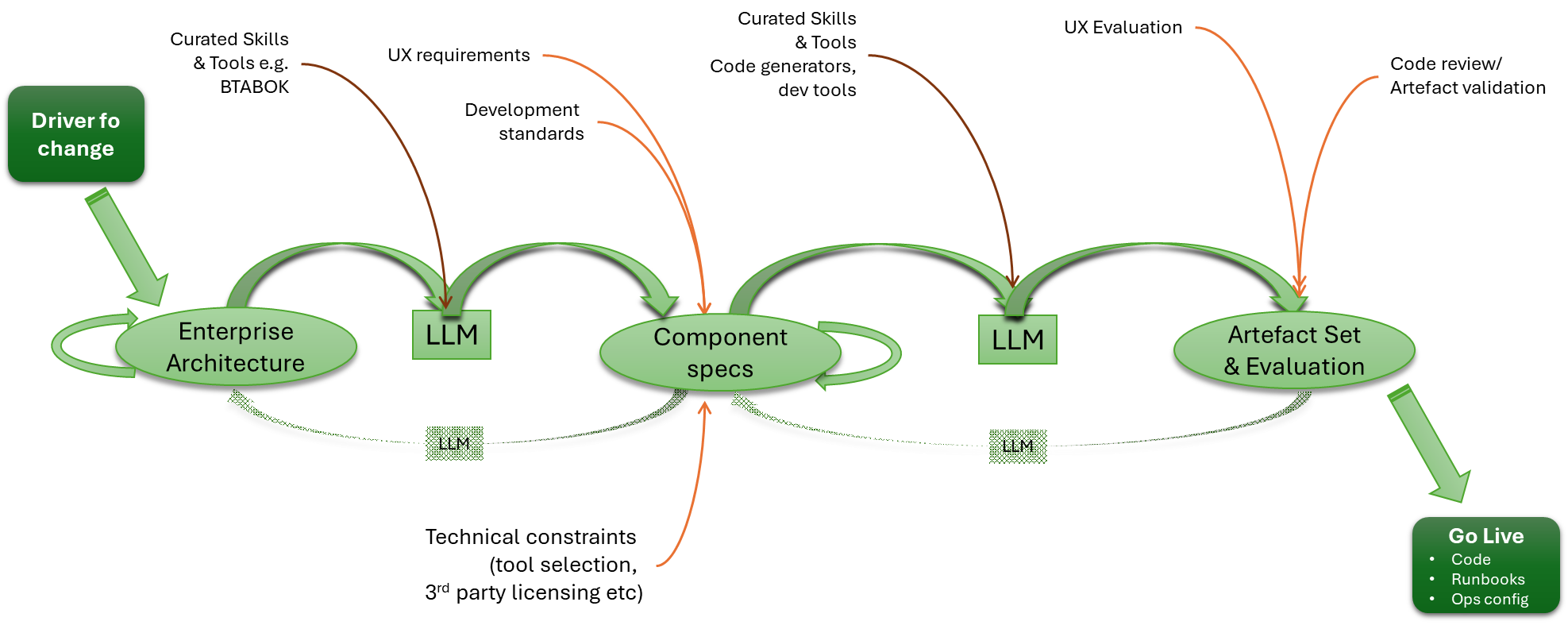
A step in this direction may well be projects such as Common Architecture Language Model (CALM), which is supported by the Fintech Open Source Foundation (FINOS), a child organisation of the Linux Foundation. While I haven’t investigated CALM very deeply, the essence is to define the architectural building blocks in a structured manner, which means that, from the definitions, more detailed diagrams can be generated and AI can be used to analyse the artefacts, etc. This sounds like a potential stepping stone between the organisation/enterprise models of Zachman and TOGAF, which aim to describe how both businesses operate and the underlying technology.
Could we see a time when docs and code stay aligned?
My experience has shown that when a spec has been involved in the process, it has exhibited the characteristics of the Spec First approach, and that the most consistently accurate documents are the user manuals, purely because they have to be created from what the code does. But such documents aren’t meant to tell you about the inner workings of a solution. This is true to the point that organisations have abandoned their architectural models, as they can’t be trusted as an as-is reflection and must start from scratch.
But to achieve the value of Spec Anchored or Spec as Source, we have to ensure that the feedback loop is working: the LLM feeds a backup stream with any changes, and downstream inputs, such as the impact of tool selection, can shift the solution. While the feedback loop should be a lot easier, it still requires commitment and effort to ensure that flow happens (certainly, since it is typically not a regularly practised behaviour).
Flies in the ointment
Trying to drive even a Spec Anchored philosophy is going to be difficult if the LLMs aren’t so great at generating quality code, or quality low-level designs that lead to the code generation. These factors are going to be dependent on choice of LLM being used, how the LLM is prompted, and most crucially the target programming languages (A.I. Codex does well with Python and Java, but I doubt it would make a good job of something like Erlang or Lisp).
The second problem is that there is a common error of people wanting to jump in and cut code (or documents), which often comes from:
- Rather than stopping to ask the question, has this problem been solved before, and in a way I can leverage? We plough on creating new unproven code.
- The view that the only place where a solution can come from is within the engineering team.
While it will be easy to blame the LLM for problems coming from these actions, are very much human.
Conclusion
As we’ve worked through much of this picture, the irony is that, in many respects, we’re no further forward. We can still make the same mistakes (failing to work through the NFRs properly, failing to define what should happen when something is wrong – aka ‘unhappy paths’, which make recovery simpler). We just have coding and document writing speed shift from 30-40Hz (the speed of a keyboard warrior) to GHz. The same problems can occur because influential decisions are still human (and remember, LLMs are, at their heart, just a computational representation of common thinking (wisdom of crowds, you might say) and therefore still vulnerable).
Going faster means mistakes happen more quickly, and uncorrected mistakes create more mess. To use an analogy, if you crash a car into a wall at 10mph, you’ll damage the bodywork, but it won’t be catastrophic. For many men, the biggest damage will be to the ego. You have the same crash at 100mph, and the outcome will be fatal. While the ability (or lack of) to absorb the energy is what will be the killer, it is actually the fact that you no longer have the time to think and change direction that is the true cause.
Perhaps what we should be seeking from AI is not to get to the end faster, but to use the acceleration to create time to consider what it is we want to achieve and how we continue building on our long-term, more sustainable achievements. This isn’t anti-agile. But it is anti ‘fail fast, fail frequently’ which has been a conflation of ideas without full understanding, and becoming more regularly challenged (like this Forbes Article)

Pingback: Vibe Coding, a book review | Phil (aka MP3Monster)'s Blog