Tags
development, Technology, blog, observability, DZone, FluentBit, OpenTelemetry, OTel, OpAMP
Just a quick post, we’ve had an article about OpAMP published on DZone check it out at OpenTelemetry’s OpAMP Potential Far Beyond Supporting Collectors

's Blog")
27 Monday Jul 2026
Posted in Fluent Observability, General, OpAMP
Tags
development, Technology, blog, observability, DZone, FluentBit, OpenTelemetry, OTel, OpAMP
Just a quick post, we’ve had an article about OpAMP published on DZone check it out at OpenTelemetry’s OpAMP Potential Far Beyond Supporting Collectors
15 Monday Jun 2026
Posted in Fluent Observability, General, OpAMP, Technology
Tags
AI, artificial-intelligence, development, Fluent Bit, LLM, MCP, OpAMP, open telementry, Technology
So we’ve been busy working on our OpAMP solution. We’ve made a number of enhancements since we labelled the code v0.4 back in April. For this post, we’ll look at the features added and where we’re looking next.
For a start, we demo’d what has been developed as part of CNCF Webinar about OpAMP
There has been a lot of feature development, particularly in support of working with Fluent Bit (and to a degree Fluentd).
We started building the Configuration Editor as a standalone capability. The thinking was that we would refactor it into the OpAMP server once we were happy with the functionality and had progressed far enough. But, as we saw this come together, it occurred to me that both deployments are good, as part of the OpAMP server, seeing the configuration being used is handy, but having a freestanding editor (without worrying about the connectivity to communicate with agents) is also a real use case.
So we have created the setup, where if the OpAMP is told to look for the Editor via the definition of Python endpoints in the configuration and it is deployed, it will be incorporated into the server. If the editor isn’t provided (deployed, or not identified in the configuration it isn’t offered in the navigation.
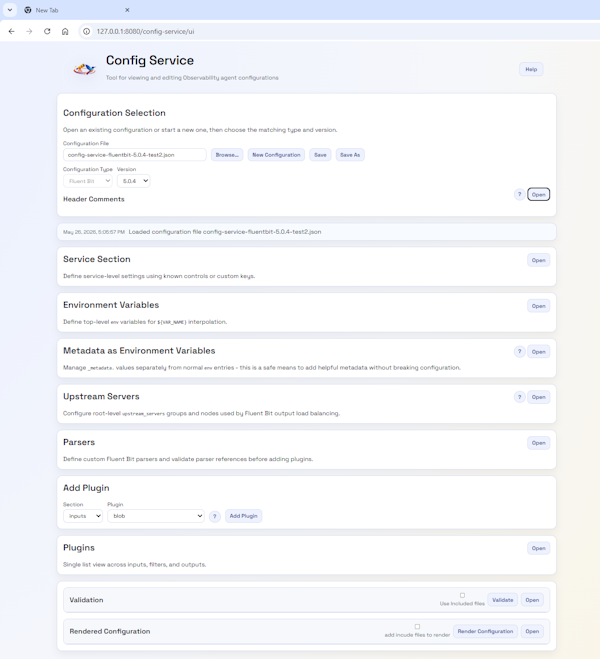
The editor is completely configuration-driven through JSON, so it only requires extending the JSON to support custom plugins or to enhance the validation rules (e.g., adding a REGEX to how a particular parameter is set). This far outweighs the current Dry run checks.
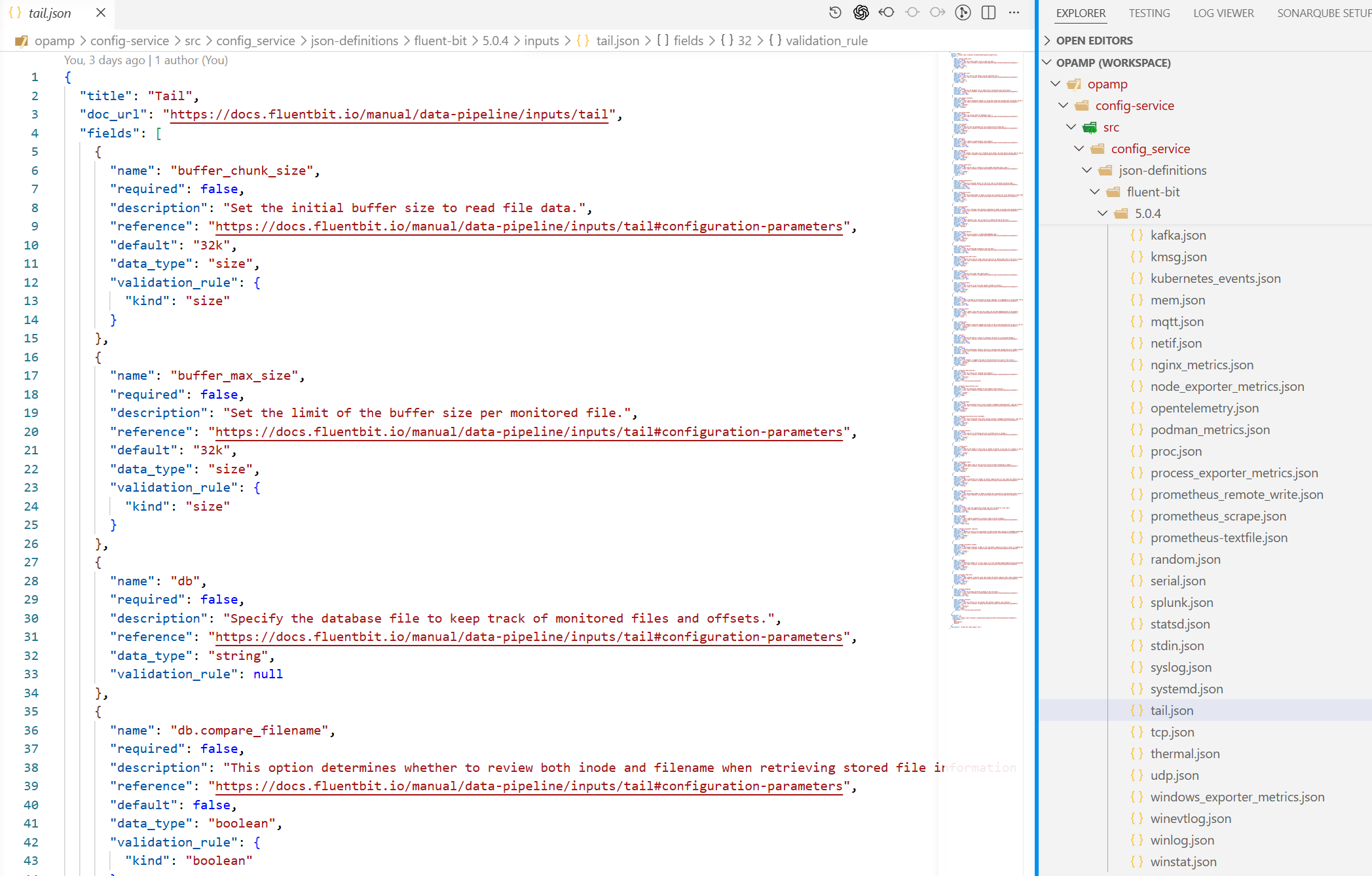
The configuration is considerable, so we refactored the structure to make it far easier to work with, and created some code that can mine Fluent Bit’s GitHub to generate an initial clean set of JSON docs. Of course these need an eyeballing to ensure they’re correct.
The catalogue viewer is a natural extension of the editor and leverages the way we tag configuration files with version details in the editor. The catalogue viewer has a configuration which tells it where to look for candidate files. These are then listed with the metadata.
The catalogue viewer presents all the identified files, which, when selected, if it knows about the config editor, will open the editor with the file. Otherwise, it opens a simple view of the file.
The catalogue viewer works in the same way as the editor in terms of authentication.
A Command Line tool maybe and odd choice of feature, but we found ourselves creating more and more scripts to support Windows and Bash shells with commonality. So we elected to leverage some frameworks to help reduce the ongoing effort required to maintain them. The utility can be used to generate the command, if you wanted embed the process of starting or stopping a process into the host OS.
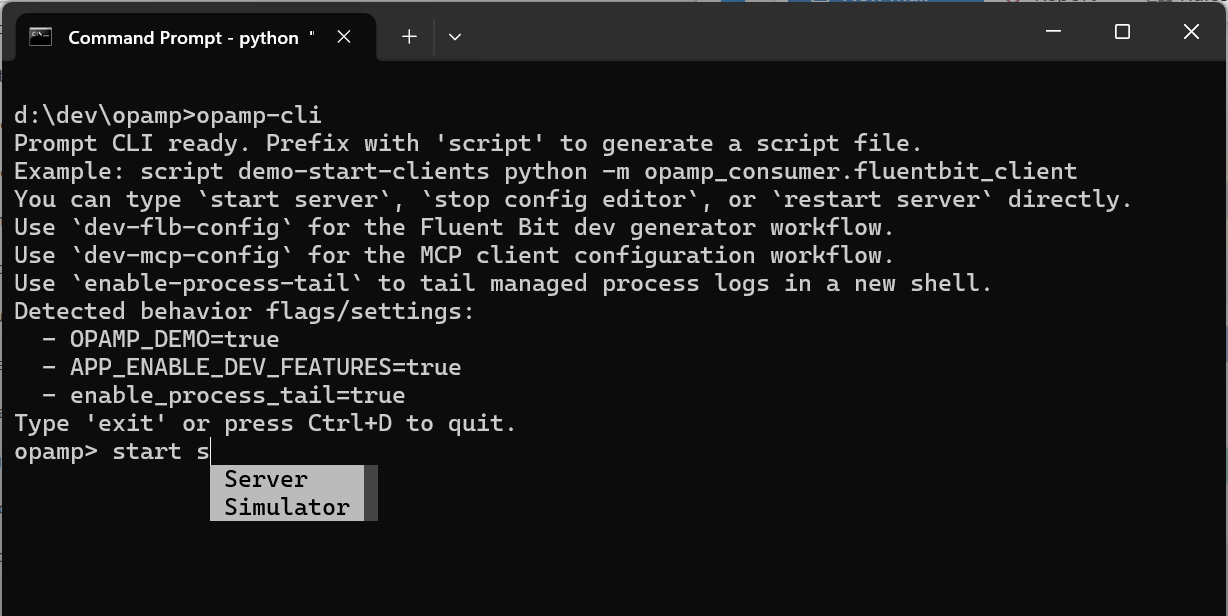
The OpAMP documentation suggests that the agent logic is embedded, or wrapped with a supervisor, with the inference that the agent forks the application process. This means that introducing the OpAMP would be invasive. There is a noninvasive variant of the Supervisor that we’ve called Observer. Here, the agent know how to identify the key process by examining the host’s processes. Then tasks such as restarting require an understanding of how to get the OS to trigger, for example, if the service is known to init.d in Linux, we can use the service command.
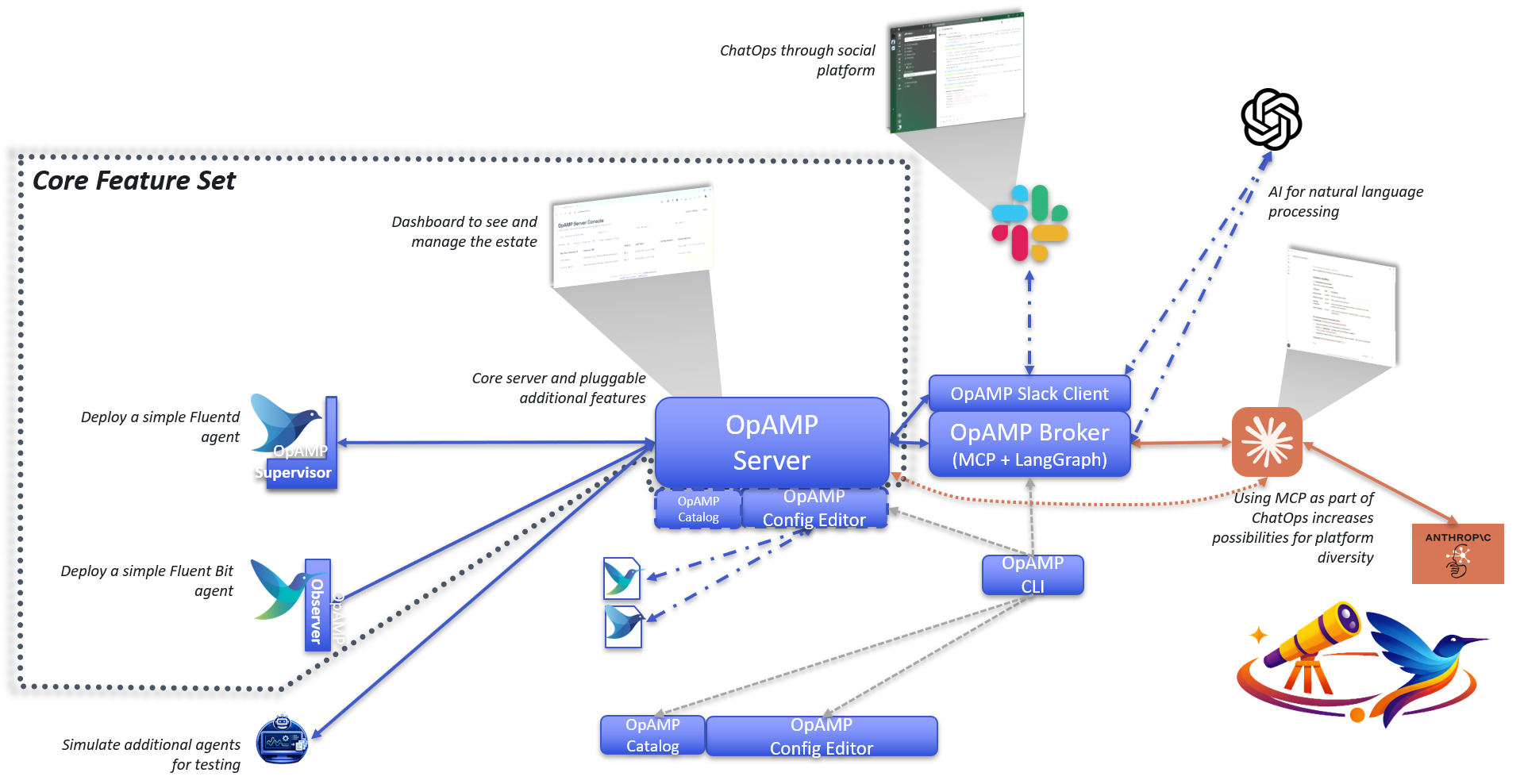
We’ve got the Slack foundations progressed, so we can use natural language VIA langgraph to then work with MCP, which exposes a subset of API capabilities. We’ve developed both the main server and the Broker to support the MCP endpoints, with the Broker acting as a proxy to the regular Server APIs. This means if we want the MCP to be usable from outside our network, then we can separate the Broker and Agent into separate networks so that the wider set of endpoints the server provides aren’t exposed.
But if you don’t want that the MCP endpoint can be switched on.
We have started to address the foundations of managing configuration deployment (for example, if our Catalogue Service is used with the Server, it can be used to select the configuration files to deploy.
Part of config deployment is understanding what is deployed, so we have developed some strategies for versioning Fluent Bit and Fluentd, and I think it will translate to other configuration files (at least into the Observability space).
What we haven’t done is fully implement the process. So we’ll focus on that
There is a lot of functionality here now, including tests with Playwright, but we really need to extend it to provide end-to-end tests in a clean environment that is set up from the various pip and wheel files.
We also want to start making these artefacts easier to retrieve, such as pulling the Wheel or PIP files from GitHub or PyPi.
16 Saturday May 2026
Posted in AI, Books, development, General, Technology
Tags
AI, artificial-intelligence, book, development, LLM, review, Technology, vibe coding, Vibe Engineering
I’ve written a bit about AI in the development process; this has been driven largely by my own experiences, colleagues’ experiences, and blog content from people I trust. So I thought it would be worthwhile to validate my perspectives against those who are more in the know on the subject. So here is my review of the book Vibe Engineering by Tomasz Lelek and Artur Skowroński.
The book opens with a very clear differentiation between vibe coding and vibe engineering (which approximates to what I’ve previously called AI-assisted development). Not only are the key conceptual differences outlined, but the consequences of vibe coding into production are also really driven home …
teams that skip the transition from prototype to engineered artifact consistently report higher defect density, longer incident resolution, and faster architectural decay
The book also shares some real horror stories of blindly trusting LLMs, particularly in operational contexts.
The crucial challenges of vibe coding beyond ideation, PoC, and possibly MVP are brilliantly distilled. Code will do something, but is it right? Is it safe? Will it scale? Can we maintain it?
Tomasz and Artur outline a form of debt called trust debt. Where we have trusted the LLM, and it accumulates issues, particularly with NFRs that are not managed and paid down, it will seriously bite, just as tech debt does. The difference is that tech debt is more readily appreciated and generally easier to understand.
debt is a direct byproduct of the dump-and-review culture. This approach uses AI to generate a large slab of code, opens a pull request, and implicitly offloads responsibility for verification to the reviewer. It’s classic diffusion of responsibility: the presence of the AI (“the model wrote it”) and a reviewer (“someone will check it”) dilutes the author’s ownership of quality
Current approaches to this kind of development can very easily lead to the issues that Human-Machine Interface researchers talk about as automation complacency and the out-of-the-loop problem
The book also highlights interesting parallels, such as those in autonomous vehicle accidents. The consequences may not be as spectacular or as tragic (today), but they can be just as harmful, given that code affects every little aspect of our lives and the decisions we make. It is only a matter of time before it is influenced by vibed code. How long before pressure and a failure to comprehend vibe coding vs vibe engineering creeps into mission-critical development?
Once the consequences and challenges are called out, the book takes us on a journey to illustrate how to better approach vibe development, specifically through defining what a successful outcome should be. The brilliantly simple thing here is that the two approaches are demonstrated with multiple different LLMs using the same prompt.
While the book provides brilliantly illustrated proofs for how to better approach vibing (moving from coding to engineering), Tomasz and Artur point out that this alone is not enough; we need to lean into broader process improvements and leverage good engineering practices.
This first chapter then sets everything up that follows, taking on a journey of re-engineering a solution. Illustrating how to prompt to extract from an existing solution the details that can then be fed as prompts to generate a new solution.
The narrative progresses through considerations such as context compression, then leverages tools to enable the LLM to take on significant tasks, such as UI design, by giving it the information it needs to work out and create React components with a consistent look and feel.
The books reveal some really good ideas that allow things to be developed far more efficiently, for example, rather than expecting the LLM to scan through code, exposing the Language Server, which provides a lot of today’s IDE smarts, such as navigation through the call chain in an application. Exposing the LSP as an MCP tool offers the LLM an efficient and more reliable approach to analysing code.
If you want to follow along and test the points that the book makes, you’re not going to need to fork out masses on LLM tokens; the authors are very clear that the cost to repeat the exercises can be done within free/trial service tiers.
I don’t want to spoil your enjoyment of reading the book by revealing its secrets here. But there is a lot of great content, which means that, with some adjustments to how the LLM is prompted and some setup, it becomes possible to significantly reduce that trust debt.
If you’re heading down the road of vibe-based development, I would highly recommend digging into this book. We’re already making some further refinements to our processes. The changes needed to transition from vibe coding to vibe engineering won’t be shocking to those with a software engineering background. But their adoption is likely to pay back significantly.

08 Friday May 2026
Posted in Cloud Native, development, Fluent Observability, Fluentbit, Fluentd, General, OpAMP, Technology
Tags
AI, artificial-intelligence, configuration, development, ELK, Fluent Bit, Fluentd, LLM, observability, OpAMP, Technology
Something that vendors like Microsoft have been really good at is reducing the friction on getting started – from simplifying installations with MSI files and defaulted options through to very informative error messages in Excel when you’ve got a function slightly wrong. Apple is another good example of this; while no two Android phones are the same, my experience is that setting up an iPhone is just so much easier than setting up an Android phone. It is also the setup/configuration where most friction comes from.
Open-Source Software (OSS), as a generalisation, tend to be a bit weaker at minimising friction – this comes from several factors:
The issue that I have observed is that we often go through cycles of working with a technology. For example, you’re building a microservice. Chances are, you’ll start writing and running it locally, without worrying about containerization. Once you’re pretty happy with things, you’ll Dockerize the service, start testing it locally, and then you’ll be ready to deploy it to a cluster. Now you’ll need your YAML. It may well be weeks since you last looked at Helm charts. You end up cutting and pasting your last configuration. But now you need to use another feature of Helm, can you remember the exact settings for the feature. So now you’re trawling the net for documentation, and then it takes several tries to get it right.
AI may well step in to help developers in this area, where solutions and products are well-documented. But with the wrong model or insufficient detail in the prompt, it’s easy to make a mistake. Personally, I’d turn to AI when it becomes necessary to trawl code to better understand the configuration and its behaviour, and to set options.
Solution – well, that depends upon the configuration syntax. We have been experimenting with RJSF (React JSON Schema Form), which provides a React-based UI that can be dynamically driven by a JSON schema and validate data with AJV (an alternative stack considered would have been around JSON Forms).
{ "type": "object", "title": "Dummy", "properties": { "name": { "type": "string", "const": "dummy", "title": "Plugin" }, "copies": { "type": "integer", "description": "Number of messages to generate each time messages are generated.", "x-doc-reference": "https://docs.fluentbit.io/manual/data-pipeline/inputs/dummy#configuration-parameters", "x-doc-required": false, "x-config-data-type": "integer", "default": 1 }, "dummy": { "type": "string", "description": "Dummy JSON record.", "x-doc-reference": "https://docs.fluentbit.io/manual/data-pipeline/inputs/dummy#configuration-parameters", "x-doc-required": false, "x-config-data-type": "string", "default": "{\"message\":\"dummy\"}" }, "fixed_timestamp": { "type": "boolean", "description": "If enabled, use a fixed timestamp.", "x-doc-reference": "https://docs.fluentbit.io/manual/data-pipeline/inputs/dummy#configuration-parameters", "x-doc-required": false, "x-config-data-type": "boolean", "default": false } }}
The above fragment shows part of the Schema definition for the Dummy plugin for Fluent Bit.
By then creating a schema that defines the different plugins, attributes, etc., we can drive validation and menu items easily in the UI. Admittedly, the config file is significant given all the plugins and configuration options, but it is a fair price to pay for a UI that validates the data. Establishing the schema to start with, we’ve covered it through scripting the retrieval and scraping of the Fluent Bit pages, which are pretty consistent in structure.
We have added some custom elements into the definition, for example, x-doc-reference, which allows us to extend the React components to provide features such as a link back to the original documentation as you select attributes or plugins.
As a result, we very quickly have a UI that can look like this:
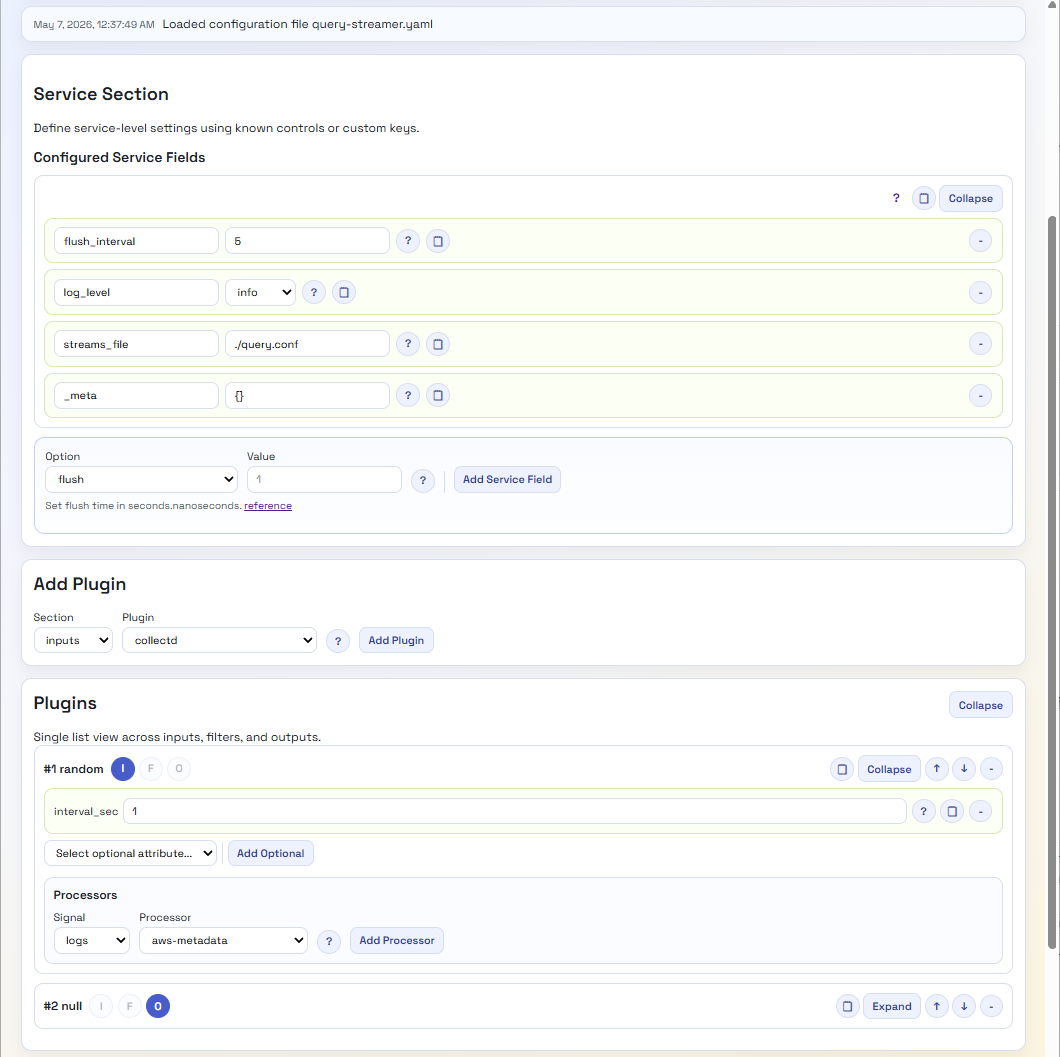
A lot easier to view and tweak, with no need to hunt for valid options. Even if we want more information, we’re just a button click away from the open-source data. Perhaps we should provide a version that hyperlinks to the Manning Live Books on Fluent Bit, etc.
There are a few other factors to consider; for example, Fluent Bit configuration is YAML, not JSON, which can be easily resolved given the relationship between the two standards. Then there are processors that can embed Lua code or a SQL-like syntax. As we’ve chosen to provide a Python backend, we’ve addressed this by providing REST endpoints which can query out of the JSON the code or SQL and perform validation using the Python Lua Parser, and the SQL syntax can be addressed using the Lark library for processing the SQL, as the syntax is simple enough to define and maintain the syntax.
We still need to address several features that Fluent Bit has, specifically:
These issues should be straightforward to overcome, although dynamically including the included elements into the UI view elements can be done. The challenge is: if any changes need to go into something that has been included, how do we push them back to the included file? Particularly if there are multiple layers of inclusion.
Fluentd configuration isn’t JSON-based notation, but it is structured. So, to apply the same mechanism, we’ll need to define a schema and a mapping mechanism. The tricky part of the schema is that Fluentd supports nesting plugins, since the way pipelines are defined for routing differs. While JSON schema will enable this with constructs such as anyOf, oneOf, object nesting, and bounded object arrays, the structure will be more complex.
The second challenge will be the transformer/renderer, so we don’t introduce issues from having to escape and unescape characters, since JSON Schema is stricter about character use.
Well, if we get this going, we’ll probably incorporate the capability into our OpAMP project and maybe create a build that lets the configuration tool run independently. Lastly, perhaps we should look to see if we can make the different layers a little more abstract, so we can plug in editors for other configurations, such as OTel Collectors or the ELK Stack.
As a bonus, perhaps transform the Schema into a quick reference web document?
27 Monday Apr 2026
Posted in AI, General, Technology
Tags
AI, artificial-intelligence, development, LLM, programming, SDD, spec driven development, Technology, TOGAF
Let me start by clarifying some terminology.
an informal noun referring to the mood, atmosphere, or aura produced by a particular person, thing, or place that is sensed or felt
This is deeply at odds with the idea of software engineering, where the OED describes engineering as:
the activity of applying scientific and mathematical knowledge to the design, building, and control of structures, machines, systems, and processes
While there is a place for vibing – to explore and help test ideas, when it comes to enterprise solutions with icy, typically have large footprints, or will grow to have large footprints and high data volumes, therefore need a more disciplined approach to ensure all those non-functional considerations can be addressed, and sustained. Put it another way, would you take an artesian approach to building and maintaining a petrochemical refinery?
This is why I try to separate the idea of vibe coding from a more disciplined AI-assisted development. A name that doesn’t roll off the tongue well, but conveys the idea that the engineer is in control and can impose discipline to drive the NFRs.
Hopefully, this also helps address nuance, which is often missing in discussions about the use of AI in software engineering, which is definitely polarising viewpoints (like many things today).
Spec Driven Development (SDD) is a growing topic in the A.I. assisted development space, and growing as a reflection of the fact that LLMs are improving rapidly, best illustrated at the moment with Mythos. The basis of SDD is to help drive consistency, structure, sustainability and rigour into the AI dev process (back to vibe coding). Consistency and structure allow us to start to easily agentify or tool aspects of development.
Getting a consistent, clear explanation of what constitutes SDD isn’t necessarily straightforward, but the best definition is in an article by Birgitta Böckeler on Martin Fowler’s website. The article dives into not just a basic explanation, but also characterises the differing approaches. The article teased out three versions of the idea, which paraphrasing are:
This evolution, particularly as people move or are pushed by leadership fearing losing a competitive edge through perceived lower development velocity, increasingly towards a spec-only approach, left me thinking about the agile manifesto and its declaration:
‘we value working code over documentation‘.
While this still has to be true, as ultimately, working code delivers the value. But the heading for the documentation has to be clear, concise, and sized for LLMs’ working documentation, as that is how we get to working code. This isn’t just to bash out some instructions and unleash the LLM; it does need to be refined and iterated on (in many ways, just like a book). We should prompt the LLM to seek clarification rather than let it make assumptions. Furthermore, we need the documentation to be accurate because an LLM will exhibit childlike trust, and if it is working with misaligned content, you’re in a 50/50 position. Unleashing an LLM on your codebase may lead to the wrong outcome. Perhaps, we need to extend the Agile manifesto, with a statement like:
we value correct, accurate, clear and concise documentation over any documentation
In other words, when using an LLM in your development context, it is better to get the LLM to reverse engineer the code to create documentation of your current state (even if that is at the price of losing the original context, design ideals, requirements, etc.) than to allow the LLM to see inaccurate and poor documentation. If this new principle is true, then we need to move away from Spec first to atleast Spec anchored approach.
Given this, we should see the heart of an engineering process looking something like:
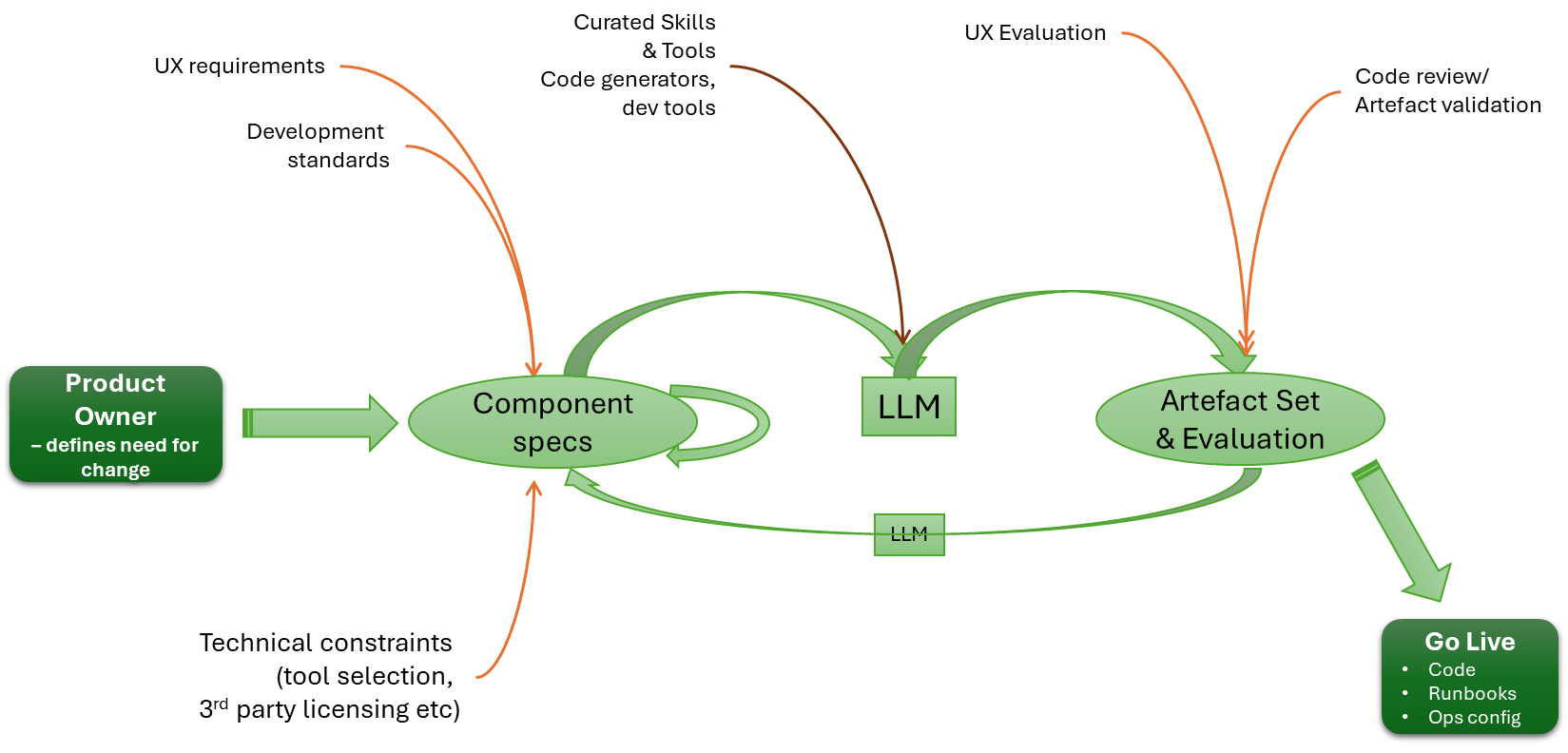
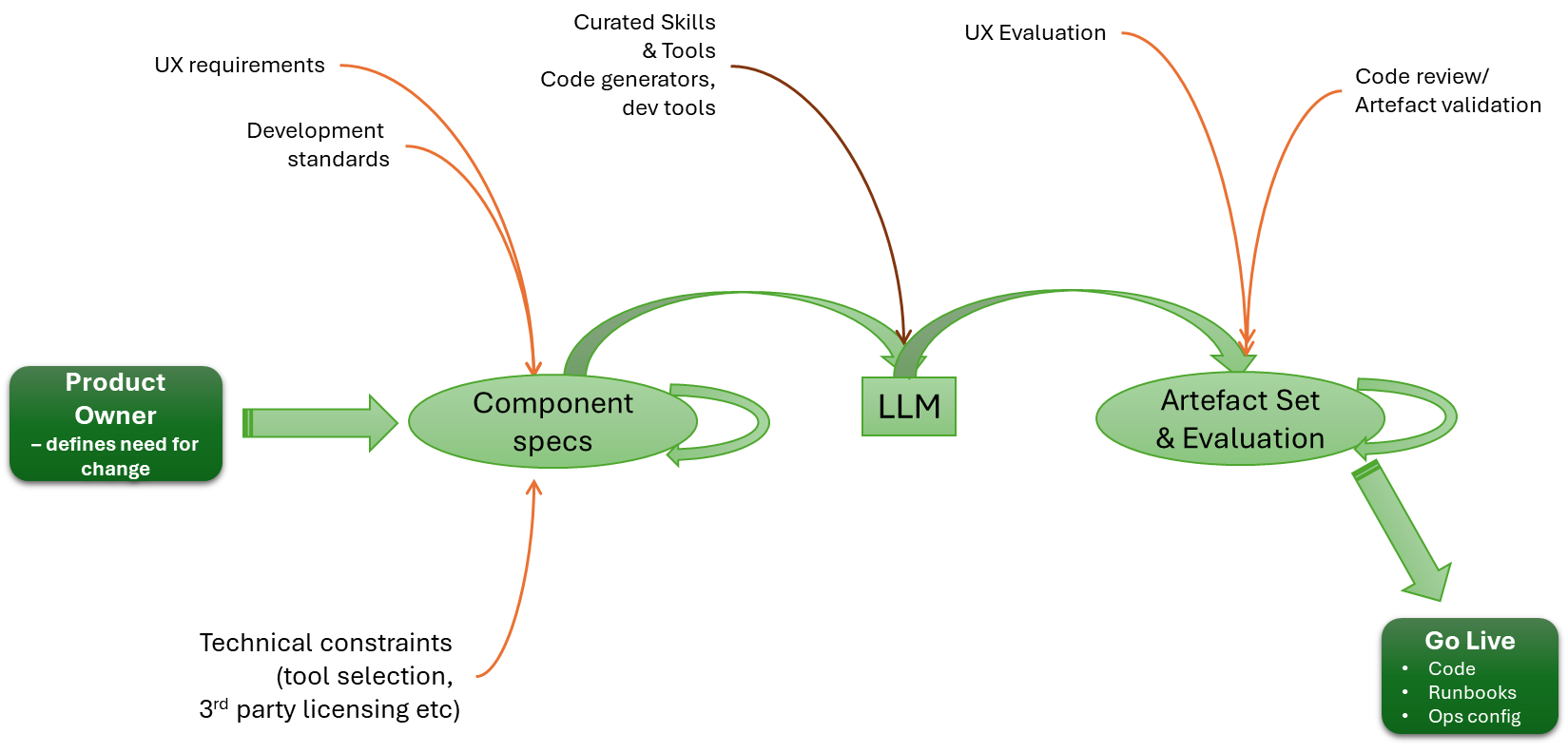
I think one of the challenges with the view of everything is that, as the Spec lead, there is an expectation that, to do it, we go from a very high-level definition straight to code. The reality is that we need the process to be more human-like. We use the LLM to take requirements and drive a high-level design. We then use the LLM to break the HLD into multiple LLDs. Importantly, we iterate on the process, until the decomposition of detail is right. The LLM cycle focuses on just one output at a time. We can certainly then use the LLM to determine consistency and integrity across all the LLDs.
There is a natural extension to this. If we are to swing back to a document-led approach (albeit with a very different journey from document to working code), could we see increased adoption of TOGAF and other architectural frameworks? Many in the past have used such frameworks as part of the argument as to why things should be code first, as often the framework artefacts are seen as the end, rather than the process and techniques as a means to an end (i.e. we do architecture, therefore I must create a large document set, rather than we do architecture to ensure we get the details we need from code correct).
Certainly, using an LLM to help with the creation and maintenance of architectural views, including making it easier to search for and address inconsistencies across different viewpoints, without necessarily needing very prescriptive, complex, and expensive toolsets.
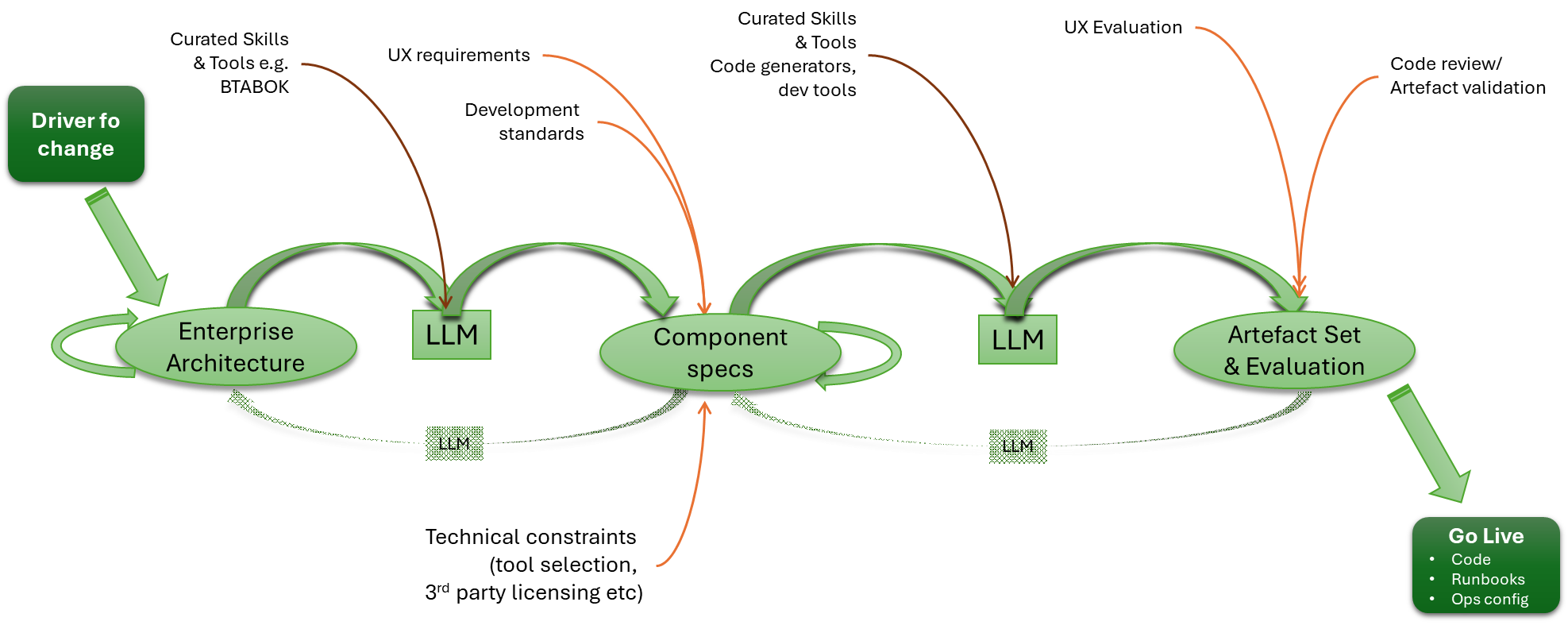
A step in this direction may well be projects such as Common Architecture Language Model (CALM), which is supported by the Fintech Open Source Foundation (FINOS), a child organisation of the Linux Foundation. While I haven’t investigated CALM very deeply, the essence is to define the architectural building blocks in a structured manner, which means that, from the definitions, more detailed diagrams can be generated and AI can be used to analyse the artefacts, etc. This sounds like a potential stepping stone between the organisation/enterprise models of Zachman and TOGAF, which aim to describe how both businesses operate and the underlying technology.
My experience has shown that when a spec has been involved in the process, it has exhibited the characteristics of the Spec First approach, and that the most consistently accurate documents are the user manuals, purely because they have to be created from what the code does. But such documents aren’t meant to tell you about the inner workings of a solution. This is true to the point that organisations have abandoned their architectural models, as they can’t be trusted as an as-is reflection and must start from scratch.
But to achieve the value of Spec Anchored or Spec as Source, we have to ensure that the feedback loop is working: the LLM feeds a backup stream with any changes, and downstream inputs, such as the impact of tool selection, can shift the solution. While the feedback loop should be a lot easier, it still requires commitment and effort to ensure that flow happens (certainly, since it is typically not a regularly practised behaviour).
Trying to drive even a Spec Anchored philosophy is going to be difficult if the LLMs aren’t so great at generating quality code, or quality low-level designs that lead to the code generation. These factors are going to be dependent on choice of LLM being used, how the LLM is prompted, and most crucially the target programming languages (A.I. Codex does well with Python and Java, but I doubt it would make a good job of something like Erlang or Lisp).
The second problem is that there is a common error of people wanting to jump in and cut code (or documents), which often comes from:
While it will be easy to blame the LLM for problems coming from these actions, are very much human.
As we’ve worked through much of this picture, the irony is that, in many respects, we’re no further forward. We can still make the same mistakes (failing to work through the NFRs properly, failing to define what should happen when something is wrong – aka ‘unhappy paths’, which make recovery simpler). We just have coding and document writing speed shift from 30-40Hz (the speed of a keyboard warrior) to GHz. The same problems can occur because influential decisions are still human (and remember, LLMs are, at their heart, just a computational representation of common thinking (wisdom of crowds, you might say) and therefore still vulnerable).
Going faster means mistakes happen more quickly, and uncorrected mistakes create more mess. To use an analogy, if you crash a car into a wall at 10mph, you’ll damage the bodywork, but it won’t be catastrophic. For many men, the biggest damage will be to the ego. You have the same crash at 100mph, and the outcome will be fatal. While the ability (or lack of) to absorb the energy is what will be the killer, it is actually the fact that you no longer have the time to think and change direction that is the true cause.
Perhaps what we should be seeking from AI is not to get to the end faster, but to use the acceleration to create time to consider what it is we want to achieve and how we continue building on our long-term, more sustainable achievements. This isn’t anti-agile. But it is anti ‘fail fast, fail frequently’ which has been a conflation of ideas without full understanding, and becoming more regularly challenged (like this Forbes Article)
10 Friday Apr 2026
Posted in AI, General, Technology
The software industry’s current upheavals due to AI are showing signs of unexpected and unintended victims, one of which is open-source software. Open-source foundations run very deep, from Linux to web and app servers, and even to key cryptography technologies.
While there are commercially funded open source efforts, such as chunks of Kubernetes, depending upon which reports you look at, 10-30% of the effort comes from individuals providing their own personal time for free. But we’re seeing a number of threats growing on this…
There is no single or simple solution. But that doesn’t mean there aren’t things we can do to help. Some immediate possibilities include:
There is on thing I am certain of, though, it is the leadership and sponsors of organisations such as CNCF, Linux Foundation, Apache, Open Source Initiative that can influence the situation the most, and it is in everyone’s interest that when open-source components have to be folded that there is atleast an easier off-ramp, than the 6 months given to switch from using something like NGINX Ingress Controller.
02 Thursday Apr 2026
Posted in Fluent Observability, General, Technology
Tags
API, Cloud, development, observability, OpAMP, OTel, Technology
Time to share a short update on our OpAMP project to support Fluent Bit and Fluentd in a supervisor model. We’ve just put a V0.3 label on the GitHub repo (https://github.com/mp3monster/fluent-opamp). The trigger for this has been the refactoring so that the framework on the client side is as reusable as possible for both Fluentd and Fluent Bit (the benefit of implementing Opamp using a supervisor model)
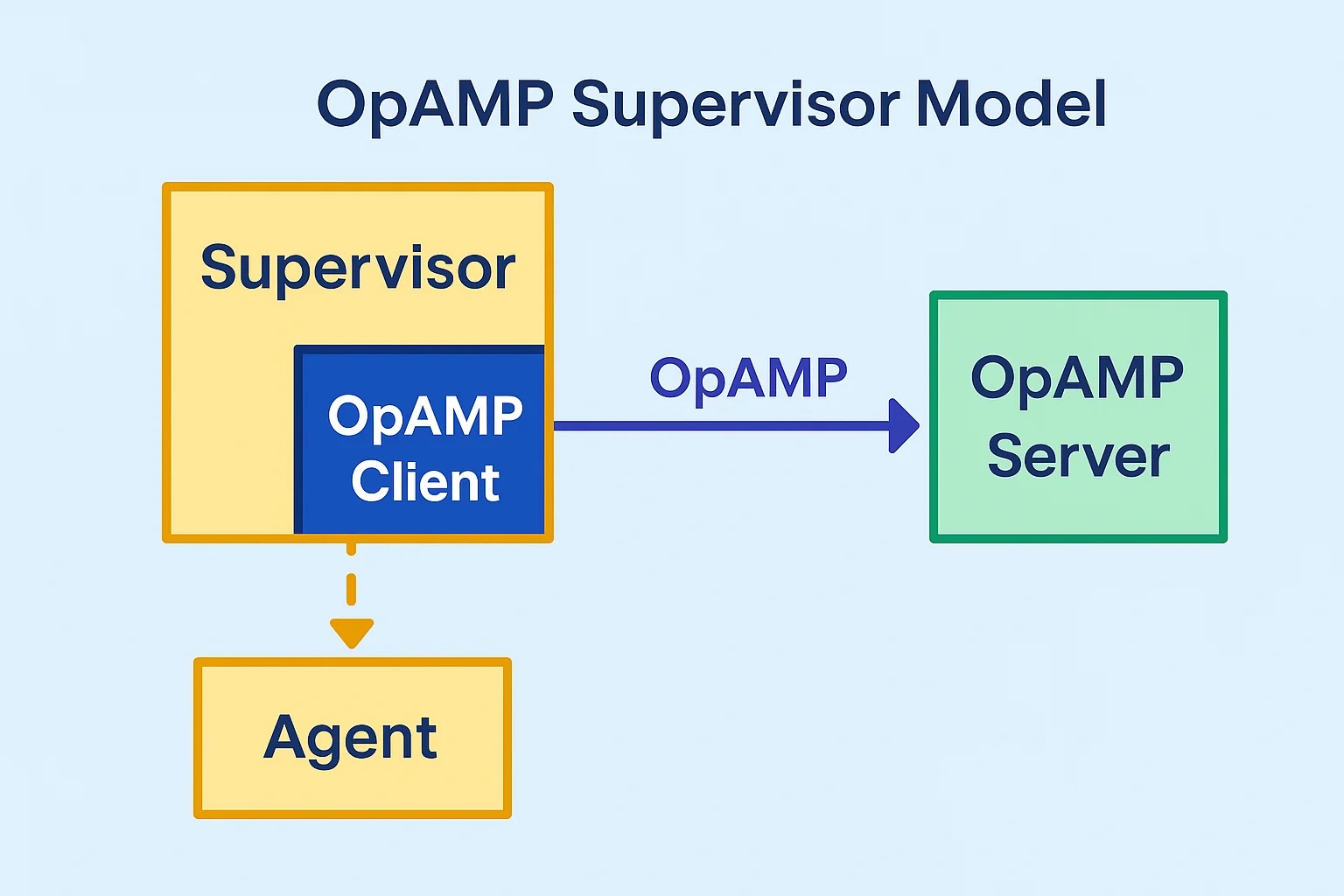
As OpAMP defines what happens between the Client and Server rather than how the client, server and agent must behave as well as the protocol we’ve introduced some features not mandated by the standard but can be delivered using the OpAMP framework. Such as shutting the agent down completely.
The following sections summarize what has recently been incorporated.
Over the last set of releases, we focused on three areas that matter in day-to-day operations:
This post is a walkthrough of what changed and why.
We restructured the consumer so Fluent Bit and Fluentd are now explicit concrete implementations built on a shared abstract client.
Before this work, behavior could drift toward Fluent Bit defaults in places where Fluentd needed different handling. The new structure makes those differences deliberate and visible.
fluentd.conf/YAMLWe’ve created scripts to make it easy to get things started quickly. The startup scripts were standardized:
scripts/run_fluentbit_supervisor.sh|cmdscripts/run_fluentd_supervisor.sh|cmdscripts/run_all_supervisors.sh|cmdWe added optional bearer-token auth for the UI and MCP end points in the server. The OPAMP spec points to different authentication strategies that need to be addressed. For bearer-token-managed endpoints (where you can direct the server to do things that are potentially much more harmful), the design goal is to keep development and unit testing simple, so we have some controllable modes..
Authentication is controlled by environment variables:
disabled (default): no auth checks.static: bearer token checked against a configured shared token.jwt: JWT bearer validation via JWKS (for example with Keycloak).Protection is prefix-based (for example /tool, /sse, /messages, /mcp) and configurable.
This means teams can gradually expand the scope of protection over time by updating path prefixes, rather than doing an all-or-nothing rollout.
Authorisation rejections are logged with mode, method, path, source, and reason, making failed requests easier to troubleshoot.
A major part of OpAMP behavior is deciding when to send compact updates versus a fuller state snapshot. We now fully observe the approach defined by OpAMP, but also have explicit controller-driven rules to provide robustness to the solution.
The client tracks reporting flags for optional outbound sections, such as:
agent_descriptioncapabilitiescustom_capabilitieshealthIf a flag is set, that section is included on send. After inclusion, the flag resets. Controllers determine when those flags are re-enabled for a future full refresh.
We support three controller types:
AlwaysSendre-enable all report flags after each successful send.SentCount: re-enable all report flags after N successful sends (fullResendAfter).TimeSend: re-enable all report flags after a configured elapsed interval.Controller updates happen after a successful send. This means a controller schedules what the next message should include; it does not mutate the already-transmitted message.
If the server sets ReportFullState in ServerToAgent.flags, the client immediately re-enables all reporting flags so the next outbound message contains full reportable state.
This gives operators a direct way to request state re-synchronization when needed.
A recurring theme in this work was avoiding “security vs usability” tradeoffs:
That same principle guided client behavior:
This foundation makes the next iterations easier:
If you’re running both Fluent Bit and Fluentd, this release should make the platform easier to operate, easier to secure, and easier to reason about under change.
03 Tuesday Mar 2026
Posted in chatbots, Fluent Observability, Fluentbit, Fluentd, General, OpAMP, Technology
Tags
AI, chatops, development, Fluent Bit, IncidentFox, innovation, LLM, OpAMP, OTel, runbooks, SRE
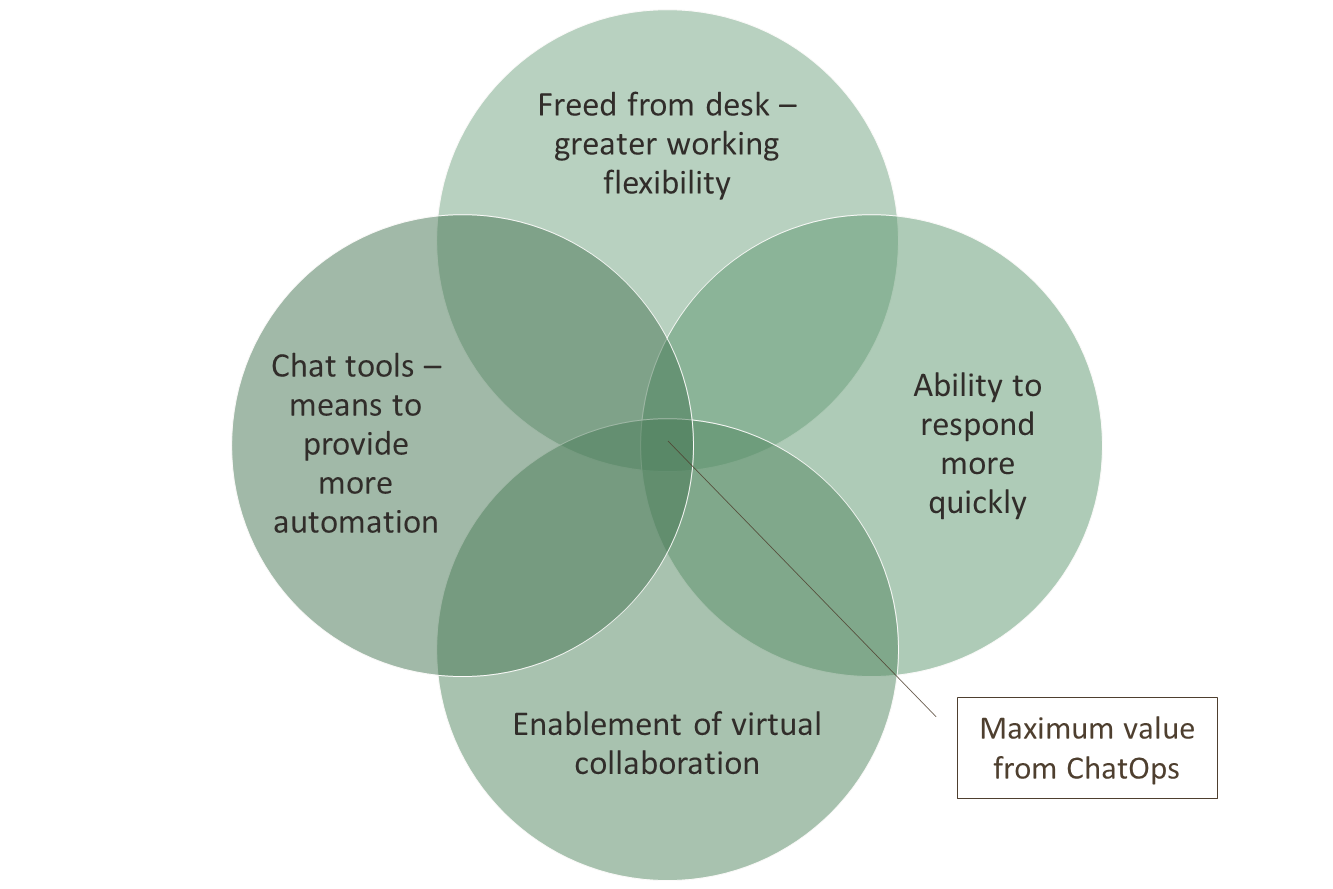
A couple of years ago, we wrote about the idea of Chat Ops, why the idea is valuable and interesting (see Fluent Bit – Powering Chat Ops, Fluent Bit with Chat Ops, for example). The essence of the idea was:
We illustrated it this way:
The ChatOps deployment looked like:
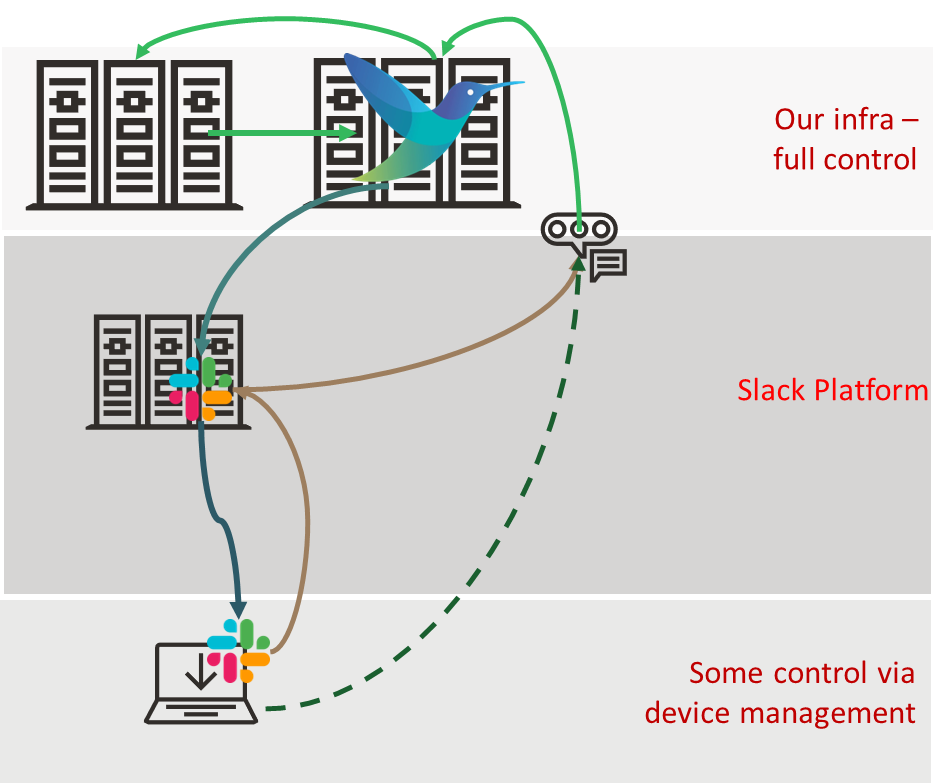
The demo was very light-touch to illustrate an idea, but we’ve since heard people pursuing the concept. So the question becomes: what has happened in the observability space that could make it easier to industrialize (e.g., scale, resilience, security, manageability)? One of the key advances being driven by the OpenTelemetry working groups within the CNCF is OpAMP. OpAMP provides a protocol for standardizing the management and control of agents and collectors such as Fluent Bit. I won’t go into the details of OpAMP here, as we covered that in a separate blog (here). But what it means is that we can either tap into the OpAMP protocol more directly as it provides a means to deliver custom commands to agents, or better still simplify by extending the management service so that we can talk to that, and it is responsible to sending on the command to the relevant agents and talk back to us if its knowledge about agent capabilities tells us its not possible.
This improves security (our bot only needs to talk to a single point in our infrastructure). Our agents, like Fluent Bit, can have a trust relationship with a central point. Effectively, we have introduced a better multifaceted trust layer into the answer. Not only that, as the OpAMP server has visibility into more of the agent deployment, we can also leverage its information and ask it to deploy our custom Fluent Bit configurations that help us observe and execute remediation processes.
While industrialization is good, it occurs to me that there is more to collaboration and conversational (or chat) interfaces than we first envisaged.
Collaboration, to a large extent, is not about bringing multiple ideas to the table and choosing the best one; it is actually about knowledge mining. Our ideas and insights are built from individual knowledge banks, or as we might put it, experience. Conversational interfaces also allow us to see what has gone before (in effect, harvesting information to improve our knowledge). So perhaps we should be asking, within the context of a platform that allows us to easily access, share, and interpret knowledge for a specific context (i.e., our current problem), what can we do?
Knowledge is unstructured or semistructured information, and information is a semistructured composition of context and data. So how do we find and leverage information if not knowledge, particularly at 2am when we’re the only person on call? The answer is to facilitate enhanced information retrieval, which could be more Slack bots that we can use to provide structured commands to retrieve relevant data from our metrics tooling, traces, etc. Organizations that follow more ITIL-guided processes will most likely have runbooks, a knowledge base with error-code information, and previous incident logs documenting resolutions. All of which can bring together a wealth of information. Doing this in a collaborative conversational tool like Slack and MS Teams will save time and effort, as you will not have to sign in to different portals to track down the details.
But we can go better, with the rise of LLMs (large language models, Gen AI if you prefer), combined with techniques such as RAG (Retrieval Augmented Generation), MCP (Model Context Protocol), and further accelerate things as we no longer have to make our Slack bot requests use what structured commands. We use natural language, we can easily paste parts of the information we’re given as part of the request – all of which means that while a single LLM may take longer to execute a single request, it is more likely to surface the details faster because we’re not having to worry about getting the notation for the bot request correct, we’re not going to have to repeat requests to narrow data immediately. With agentic techniques, you can have the LLM pull data from multiple systems in a single go.
All of which is very achievable; many vendors (and open-source teams) have been seeking a competitive edge and exposing their APIs through MCP tools. There is the possibility that some of this is ‘AI washing’, but the frameworks to support MCP development are well progressed, so you can always refine or create your own MCP server. Here are just a few examples:
In addition to these, which align with widely used open-source solutions, there are MCP servers for vendor-specific offerings, such as Honeycomb and Chronosphere.
The use of MCP raises an interesting possibility – as it becomes very possible to have a universal MCP client, which can be easily interfaced into any conversational tool – after all, we just need to send the text that is addressed to the client, i.e., the adaptor to Slack, MS Teams, etc. is pretty simple. This means we can start to consider things like the same tooling, supporting tools like Claude Desktop, and its mobile equivalent.
If we bring AI into the equation, consider ML and small models as well, we can start looking at exploiting pattern recognition in the occurrences of issues. This would mean the value diagram becomes more like:
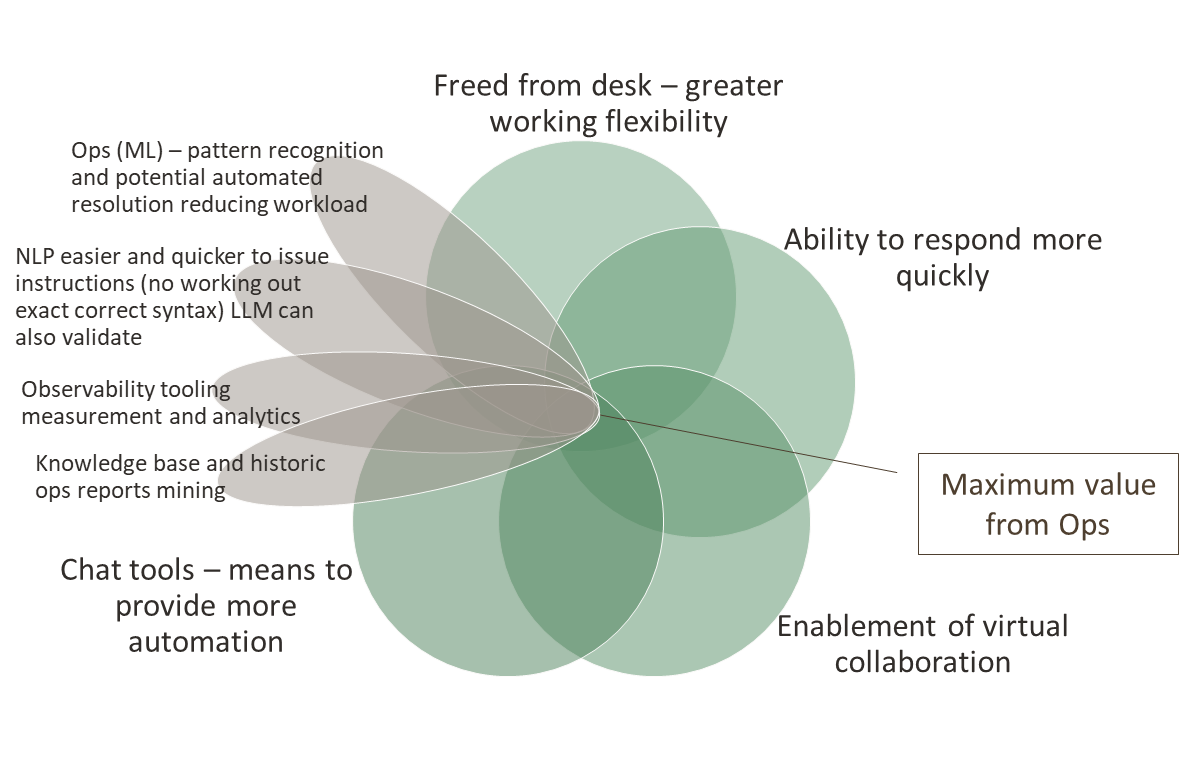
We should also keep in mind the development of the new OpAMP spec from the CNCF OpenTelemetry project that provides a mechanism to centrally track and interact with all our agents, such as Fluent Bit (not to mention Fluentd, OTel Collectors, and others).
Bringing all of this together isn’t a small task, and what of these ideas already exist? Are there building blocks we can lean on to show that the ideas expressed here are achievable? This brought us to IncidentFox.ai (GitHub link – IncidentFox). IncidentFox already exploits MCP servers from several products, such as Grafana, and supports a knowledge base geared towards intelligent searching that can also tap into common sources of operational knowledge, such as Confluence.
But IncidentFox has taken the use of LLMs further with its agentic approach, recommending actions, and once it has access to source code, LLMs can be used to start looking for root causes. To do this, IncidentFox has harnessed the improvements in Gen AI reasoning and the selection and use of the MCP-enabled tools we mentioned, which enable the extraction of data and information from mainstream observability tools.
IncidentFox isn’t the only organization heading in this direction (Resolve.ai, Randoli, and Kloudfuse are building AI SRE tools, but with a fully proprietary business model), but it is supporting an open-source core. All of these solutions come under the banner of AI SRE. Interestingly, a new LLM benchmark has emerged called SRESkillsBench, in addition to the models such as Bird and Spider, which specifically evaluate LLMs against SRE tasks. This kind of information certainly is going to create some interesting debates – do you use the best LLM for specific tasks, or the LLM the vendor has worked with and optimized their prompting to get the best from it?
A lot of these tools focus on detection and diagnostics, and steer you to the relevant runbooks, there seems to be less said about how runbooks can be translated into remediation actions that can be executed. The ability to translate runbooks into executable steps will require either tooling via MCP or custom models with suitable embedded functions. Whichever approach is adopted, having a well-understood control plane, such as Kubernetes, will make it easier. But not everything is native K8s. Lots of organizations still use just virtualization, or even bare metal. We also see this with cloud vendors that offer bare-metal services due to the need for maximum compute horsepower. To address these scenarios from a centralized control, either needs to allow remote access (ssh tunnels) to all the nodes, or a means to work with a distributed tooling mechanism, which is what we had with our original chatops idea and the possibilities offered through OpAMP.
Of course, introducing LLMs opens up another set of challenges in the observability space, which OpenLLMetry (driven by TraceLoop) and LangFuse are working to address. But that’s for another blog.
Sticking with an open-source/standards-based approach means there is a clear direction of enabling AI Agents to be part of the OTLP (Open Telemetry Protocol) pipeline and leverage the MCP tooling of backend observability platforms. IncidentFox doesn’t yet provide an inline OTLP capability (although some of the proprietary options have gone this way), but that is less of a concern, as Fluent Bit provides a lot of capability to help identify issues (such as timeseries/frequency measurement, error identification, etc.), which can be combined with IncidentFox’ means to instruct it to initiate an incident. We could do this with direct API calls, but what would be more interesting and flexible is that, when our Fluent Bit process notifies the Ops team in Slack of an issue, it also ensures that the IncidentFox Slack agent picks up the message, allowing it to start its own analysis. In effect, a collaboration platform can be as impactful as an integration platform.
Furthermore, now that we have early warning of an issue via Fluent Bit, we can interact with IncidentFox through its tooling to start interrogating the diverse range of tools well before the new problem’s details have been fully ingested into the backend tooling and been detected as an issue. So we can now get a jump start by prompting IncidentFox, which can mine for information and recommendations. This is where, at 2am, we can still work collaboratively, albeit with a collaborator that is not another person but an LLM.
As I’ve mentioned, the challenge is making the runbook executable in environments that don’t provide a strong control plane, such as K8s. Here, we can further develop our ChatOps concept. By providing a set of MCP tools for Fluent Bit (IncidentFox supports providing your own tools), the runbook can describe remediation steps, and the use of the LLM ensures the Fluent Bit tool is invoked appropriately.
This would still mean that the central point of Incident Fox would need to talk with each Fluent Bit deployment, better than just opening up SSH directly. But we could be smarter. OpAMP provides a central coordination point, and through its Supervisor or embedded logic in an observability client, the protocol’s support for custom commands could be exploited. So we expose the way we interact with Fluent Bit via the custom command mechanism, and we have a robust, controlled mechanism. Furthermore, the concept could be extended to exploit the aggregated knowledge of agents and their configuration (or pushing out new configurations to solve operational problems as OpAMP has been designed to enable), we can automate the determination of whether the remediation action needs to be executed across operational nodes.
Let’s walk through a hypothetical (but plausible) scenario. We have manually deployed systems across a load-balanced set of servers in a pre-production environment used for load testing, each with TLS certificates. As it is a pre-production environment, we use self-signed certificates. We are starting to see errors because the certificates have expired, and someone forgot to recycle them. Fluent Bit has been forwarding the various error log messages to Loki, but the high frequency of the errors causes it to send details to Slack for the Ops team. This, in turn, nudges IncidentFox to act, determines the root issue, and finds remediation in a runbook that points to running a script on the host to provide a fresh self-signed certificate. As we have a Fluent Bit ops pipeline that can trigger that script, and it is deemed low risk, we allow IncidentFox to execute the runbook unsupervised. To execute the run book, it uses the OpAMP server to send the custom command to Fluent Bit. But the runbook says other nodes should be checked. As a result, IncidentFox works with the OpAMP server via its MCP tooling to identify which other Fluent Bit deployments are monitoring other nodes and to direct the custom command to those nodes as well.
To achieve this, we need an architecture along the following lines, in addition to IncidentFox and the associated MCP tools, we would need to have the OpAMP server, either the OpAMP client embeddable into Fluent Bit or an OpAMP supervisor that understands how to pass custom commands, something it perhaps could do by using another MCP interface to Fluent Bit directly.
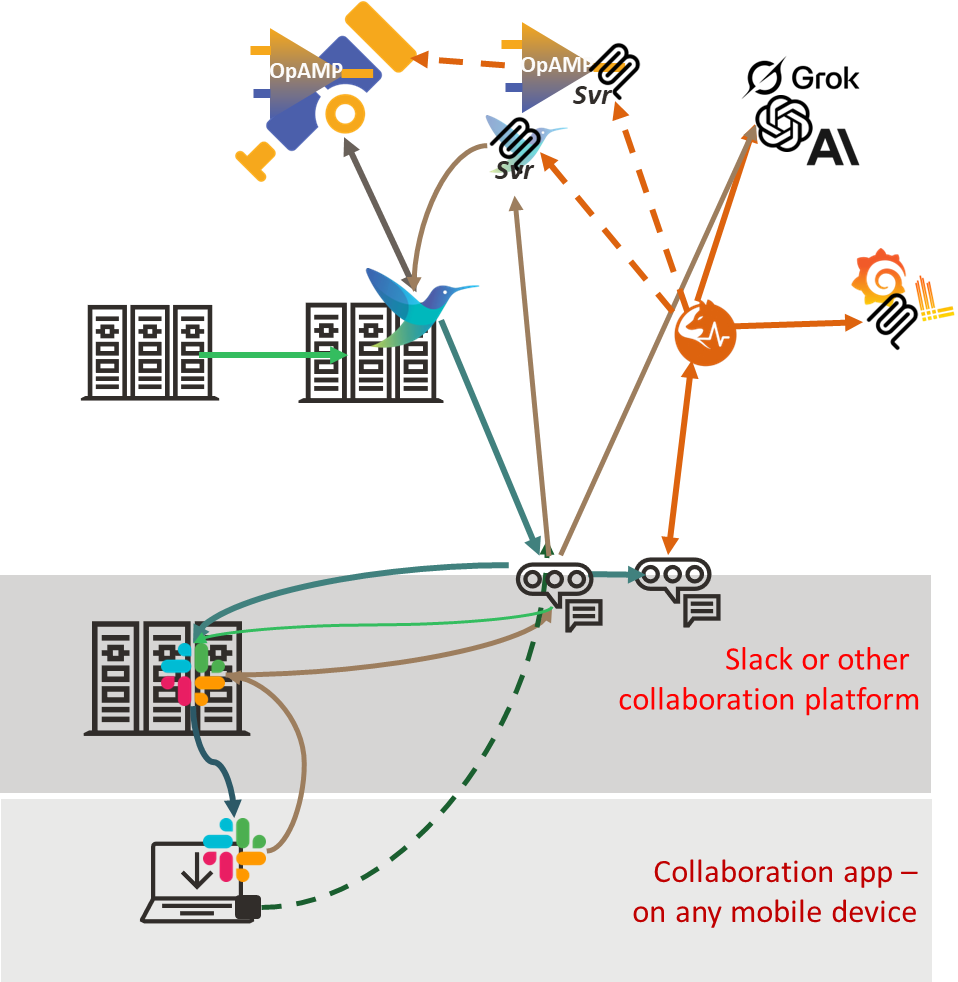
As you can see, there has been significant advancement in how LLMs and MCP tooling can be used to enable operational support activities. To turn this into a reality, the core Fluent Bit committers need to ideally press on with supporting OpAMP. A standardized MCP tooling arrangement for an open-source OpAMP server will also make a significant advancement. Although we could get things working directly with MCP using Fluent Bit.
IncidentFox being able to function as an OpAMP server itself would really enable it shift the narrative, particularly if it provided a means to plug into a supervisor to handle custom actions.
Looking at all of this, one dimension of operational issues is the ability to correlate an issue with environmental changes. That means understanding not only software versions, but also the live configuration. Again, not too difficult when your control plane is K8s. But trickier outside of that ecosystem. You need to identify when the change was defined and when it was applied. Is it time for some functionality that understands when details such as file stamps for configurations or certain binary files change? Perhaps a proxy service that can spot API calls to configuration endpoints and file system changes to configuration files? Then have that information logged centrally so that problems can be correlated to a system configuration or deployment problem.
Since writing this, we came across Mezmo, which, like Resolve.ai, is developing a proprietary solution but is looking to make an open-source offering. As part of that journey, they have sponsored an O’Reilly Report on Context Engineering for Observability.
17 Friday Oct 2025
Posted in General, Oracle, Technology
Now that details of the product I’ve been involved with for the last 18 months or so are starting to reach the public domain (such as the recent announcement at the UN General Assembly on September 25), I can talk to a bit about what we’ve been doing. Oracle’s Digital Government Global Industry Unit has been working on a solution that can help governments address the questions of food security.
So what is food security? The World Food Programme describes it as:
Food security exists when people have access to enough safe and nutritious food for normal growth and development, and an active and healthy life. By contrast, food insecurity refers to when the aforementioned conditions don’t exist. Chronic food insecurity is when a person is unable to consume enough food over an extended period to maintain a normal, active and healthy life. Acute food insecurity is any type that threatens people’s lives or livelihoods.
World Food Programme
By referencing the World Food Programme, it would be easy to interpret this as a 3rd world problem. But in reality, it applies to just about every nation. We can see this, with the effect the war in Ukraine has had on crops like Wheat, as reported by organizations such as CGIAR, European Council, and World Development journal. But global commodities aren’t the only driver for every nation to consider food security. Other factors such as Food Miles (an issue that perhaps has been less attention over the last few years) and national farming economics (a subject that comes up if you want to it through a humour filter with Clarkson’s Farm to dry UK government reports and US Department of Agriculture.
Looking at it from another perspective, some countries will have a notable segment of their export revenue coming from the production of certain crops. We know this from simple anecdotes like ‘for all the tea in China’, coffee variants are often referred to by their country of origin (Kenyan, Columbian etc.). For example, Palm Oil is the fourth-largest economic contributor in Malaysia (here).
One of the key means of managing food security is understanding food production and measuring the factors that can impact it (both positively and negatively), which range from the obvious—like weather (and its relationship to soil, water management, etc.) —to what crop is being planted and when. All of which can then be overlayed with government policies for land management and farming subsidies (paying farmers to help them diversify crops, periodically allowing fields to go fallow, or subsidizing the cost of fertilizer).
Oracle is a technology company capable of delivering systems that can operate at scale. Technology and the recent progress in using AI to help solve problems are not new to agriculture; in fact, several trailblazing organizations in this space run on Oracle’s Cloud (OCI), such as Agriscout. Before people start assuming that this is another story of a large cloud provider eating their customers’ lunch, far from it, many of these companies operate at the farm or farm cooperative level, often collecting data through aerial imagery from drones and aircraft, along with ground-based sensors. Some companies will also leverage satellite imagery for localized areas to complement these other sources. This is where Oracle starts to differentiate itself – by taking high-resolution imagery (think about the resolution level needed to differentiate Wheat and Maize, or spot rice and carrots, differentiate an orchard from a natural copse of trees). To get an idea, look at Google Earth and try to identify which crops are growing.
We take the satellite multi-spectral images from each ‘satellite over flight’ and break it down, working out what the land is being used for (ruling out roads, tracks, buildings, and other land usage). To put the effort to do this into context, the UK is 24,437,600,000 square meters and is only 78th in the list of countries by area (here). It’s this level of scale that makes it impractical to use more localized data sources (imagine how many people and the number of drones needed to fly over every possible field in a country, even at a monthly frequency).
This only solves the 1st step of the problem, which is to tell us the total crop growing area. It doesn’t tell us whether the crop will actually grow well and produce a good yield. For this, you’re going to need to know about weather (current, forecast, and historic trends), soil chemical composition and structure, and information such as elevation, angle, etc. Combined with an understanding of optimal crop growing needs (water levels, sun light duration, atmospheric moisture, soil types and health) – good crops can be ruined by it simply being too wet to harvest them, or store them dryly. All these factors need to be taken into account for each ‘cell’ we’re detecting, so we can calculate with any degree of confidence what can be produced.
If this isn’t hard enough, we need to account for the fact that some crops may have several growing seasons per year, or succession planting is used, where Carrots may be grown between March and June, followed by Cucumbers through to August, and so on.
Hopefully, you can see there are tens of millions of data points being processed every day, and Oracle’s data products can handle that. As a cloud vendor, we’re able to provide the computing scale and, importantly, elasticity, so we can crunch the numbers quickly enough that users benefit from the revised numbers and can work out mitigation actions to communicate to farmers. As mentioned, this could be planning where to best use fertilizer or publishing advice on when to plant which crops for optimal growing conditions. In the worst cases recognizing there is going to be a national shortage of a staple crop and start purchasing crops from elsewhere and ensure when the crops arrive in ports they get moved out to the markets (like all large operations – as we saw with the Covid crises – if you need to react quickly, more mistakes can be made, costs grow massively driven by demand).
I mentioned AI, if you have more than the most superficial awareness of AI, you will probably be wondering how we use it, and the problems of AI hallucination – the last thing you want is a being asked to evaluate something and hallucinating (injecting data/facts that are not based on the data you have collected) to create a projection. At worst, this would mean providing an indication that everything is going well, when things are about to really go wrong. So, first, most of the AI discussed today is generative, and that is where we see issues like hallucinations. We’re have and are adopting this aspect of AI where it fits best, such as explainability and informing visualization, but Oracle is making heavy use of the more traditional ideas of AI in the form of Machine Learning and Deep Learning which are best suited to heavy numerical computational uses, that is not to say there aren’t challenges to be ddressed with training the AI.
When it comes to Oracle’s expertise in the specialized domains of agriculture and government, Oracle has a strong record of working with governments and government agencies from its inception. But we’ve also worked closely with the Tony Blair Institute for Global Change, which works with many national government agencies, including the agriculture sector.
My role in this has been as an architect, focused primarily on applying integration techniques (enabling scaling and operational resilience, data ingestion, and how our architecture can work as we work with more and more data sources) and on applying AI (in the generative domain). We’re fortunate to be working alongside two other architects who cover other aspects of the product, such as infrastructure needs and the presentation tier. In addition, there is a specialist data science team with more PhDs and related awards than I can count.
Oracle’s Digital Government business is more than just this agriculture use case; we’ve identified other use cases that can benefit from the data and its volume being handled here. This is in addition to bringing versions of its better-known products, such as ERP, Healthcare (digital health records management, vaccine programmes, etc.), national Energy and Water (metering, infrastructure management, etc).
For more on the agricultural product:
06 Monday Oct 2025
Posted in APIs & microservices, Books, General, Technology
Tags
API, API Evangelist, APIHandyman, AsyncAPI, book, development, OAS, Open API, practises, review, Swagger
When it comes to REST-based web APIs, I’ve long been an advocate of the work of Arnaud Lauret (better known as the API Handyman) and his book The Design of Web APIs. I have, with Arnaud’s blessing, utilized some of his web resources to help illustrate key points when presenting at conferences and to customers on effective API design. I’m not the only one who thinks highly of Arnaut’s content; other leading authorities, such as Kin Lane (API Evangelist), have also expressed the same sentiment. The news that a 2nd Edition of the book has recently been published is excellent. Given that the 1st edition was translated into multiple languages, it is fair to presume this edition will see the same treatment (as well as having the audio treatment).
So, why a second edition, and what makes it good news? While the foundational ideas of REST remain the same, the standard used to describe and bootstrap development has evolved to address practices and offer a more comprehensive view of REST APIs. Understanding the Open API specification in its latest form also helps with working with the Asynchronous API specifications, as there is a significant amount of harmony between these standards in many respects.
The new edition also tackles a raft of new considerations as the industry has matured, from the use of tooling to lint and help consistency as our catalogue of APIs grows, to be able to use linting tools, we need guidelines on how to use the specification, and what we might want to make uniform nd ensure the divergence is addressed. Then there are the questions about how to integrate my API support / fit into an enriched set of documents and resources, such as those often offered by a developer portal.

However, the book isn’t simply a guide to Open API; the chapters delve into the process of API design itself, including what to expose and how to expose it. How to make the APIs consistent, so that a developer understanding one endpoint can apply that understanding to others. For me, the book shows some great visual tools for linking use cases, resources, endpoint definitions, and operations. Then, an area that is often overlooked is the considerations under the Non-Functional Requirements heading, such as those that ensure an API is performant/responsive, secure, supports compatibility (avoiding or managing breaking changes), and clear about how it will respond in ‘unhappy paths’. Not to mention, as we expand our API offerings, the specification content can become substantial, so helping to plot a way through this is excellent.
There will be some who will think, ‘Hey, I understand the OpenAPI Specification; I don’t need a book to teach me how to design my APIs.’ To those, I challenge you to reconsider and take a look at the book. The spec shows you how to convey your API. The spec won’t guarantee a good API. The importance of good APIs grows from an external perspective – it’s a way to differentiate your service from others. When there is competition, and if your API is complex to work with, developers will fight to avoid using it. Not only that, in a world where AI utilizes protocols like MCP, having a well-designed, well-documented API increases the likelihood of an LLM being able to reason and make calls to it.
If there is anything to find fault with – and I’m trying hard, is it would be it would have been nice if it expanded its coverage a little further to Asynchronous APIs (there is a lot of Kafka and related tech out there which could benefit from good AsyncAPI material) and perhaps venture further into how we can make it easier to achieve natural language to API (NL2API) for use cases like working with MCP (and potentially with A2A).

You must be logged in to post a comment.