
Example Ansible playbook
So having had a significant introduction to Ansible and its capabilities, chapter 2 gets into developing Ansible Playbooks. To do this the book confronts development practises of environment creation and management scripts, or the tendency for ops teams not to apply development like rigour. It is refreshing to read things like ….
… seen these practices at close quarters, we firmly believe that these are more or less similar to voodoo practices that need to be done away with.
Excerpt From: “Learning Ansible.” Packt Publishing.
The book does there for dig into the basics of using Git, and illustrating it using the configuration files from an earlier example. The next step would be if you follow development practises to use a Continuous Integration (CI). The book is surprisingly brief on this subject, compared to say Git.
In a development lifecycle the next step is to test, which elegantly introduces Ansible and Vagrant for instantiating virtual machines that the Ansible playbook can be tested against.
This creates the environment by which several additional capabilities provided by Ansible can aide testing activities particularly the ability to tag activities and then run the Ansible script targeting the specifically tagged activities. The additional ability that allows Ansible Playbooks to be executed in a way that allows it only tell what would be changed, rather than perform the change.
The book takes you on from there to introducing how Serverspec could be used. Things for me gain a little too much velocity, perhaps it doesn’t help that I am not familiar with Ruby.
The final part of the chapter and we’re back on solid ground with options on configuring SCM solutions such as Git to support deployment and how Ansible can support the same playbook in different environments such production, preproduction where the playbook is the same but you will be working with different server ids and credentials.
Even if you weren’t to use Ansible there are some thought provoking and good principles for config management and system scripting here.
So by having completed the first two chapters all the principle of Ansible are covered along a range of guiding practises that reflect good development practises in the context of producing environment management. There are limits and the next chapters then go into how to build upon the basics for so it is easy to create more advanced Playbooks for real world environments with capabilities like playbook iteration, including Playbooks within Playbooks and conditionals for example.
The chapter builds upon the simple examples used on the first chapters showing how the Playbooks can be made to be a lot smarter. For example rather than a task to install each individual application required you can build a table of configuration values and get the task to iterate through the set of RPMs and versions for example. The structures to iterate over can be multi dimensional so you can define some advanced configuration and keep the tasks simple. By building on the earlier examples it helps highlight the benefits of the feature being explained which really helps.
Other features explained here include handlers, so you can trigger one or more activities to be performed once the playbook tasks have completed – so restarting processes can be executed only when all tasks are completed for example. Other development like features like including other Playbooks are introduced (inline with the idea of DRY – Don’t Repeat Yourself). This leads into using roles, where than identifying your target servers by name or IP you can bring everything together by assigning the server roles e.g. DBTier, AppTier etc. The final two elements are the approach to templating using the Python Jinga2 framework and most crucially given that you will be handling configuration data and passwords Security.
Another couple of well written chapters that embody both insight into Ansible but also hung on the good development ideas so even if you choose not to use Ansible, some of the thinking here could be applied or at-least used to formulate questions as to how the ideas might translate to chef or puppet for example.

's Blog")
 I’ve been reading Chris Richardson’s new book Mixroservice Patterns published by Manning (here or here). Whilst I haven’t finished the book yet, I have read enough to feel I can provide worthwhile observation.
I’ve been reading Chris Richardson’s new book Mixroservice Patterns published by Manning (here or here). Whilst I haven’t finished the book yet, I have read enough to feel I can provide worthwhile observation.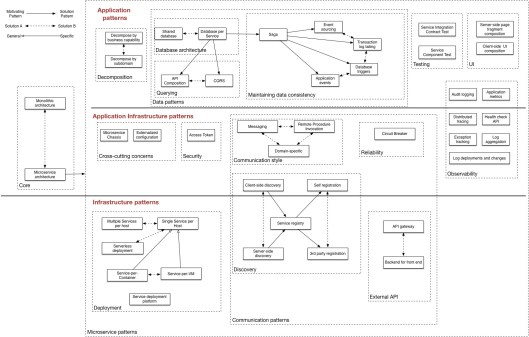

.jpg) I have just been told that the 2nd Edition of Java EE Development with Eclipse has now been published. This is another book that I have supported as a technical reviewer. Looking forward to receiving my print copy so I can see how my suggestions and feedback have carried through to the final copy.
I have just been told that the 2nd Edition of Java EE Development with Eclipse has now been published. This is another book that I have supported as a technical reviewer. Looking forward to receiving my print copy so I can see how my suggestions and feedback have carried through to the final copy.

 The first chapter takes you through a series of simple examples derived from a classic variant of IT’s classic Hello World solution. This does make for a sizeable first chapter (about 1/5th of the book) but does introduce all the core principles, ideas and capabilities that are embodied and provided by Ansible. If you want to know whether Ansible is likely to meet what you want to do then reading just this chapter will probably give you a view on whether you’re likely to be able to do what you want.
The first chapter takes you through a series of simple examples derived from a classic variant of IT’s classic Hello World solution. This does make for a sizeable first chapter (about 1/5th of the book) but does introduce all the core principles, ideas and capabilities that are embodied and provided by Ansible. If you want to know whether Ansible is likely to meet what you want to do then reading just this chapter will probably give you a view on whether you’re likely to be able to do what you want.

You must be logged in to post a comment.