's Blog")
One of the benefits of using cloud providers is the potential to scale solutions to meet demand by scaling out with additional compute nodes without concern for physical capacity limits (cost considerations are smaller, but still apply). Dynamic scaling is typically driven by monitoring defined groups of nodes for CPU use and when demand hits a threshold an additional node is spun up. Kubernetes can create some more nuanced scaling configurations but this is tends to be used for microservice style solutions.
This is well and fine, but if we need to finesse the configuration to ensure multiple container instances (such as microservices) can be allowed on a single node without compromising the deployment of containers across nodes of a cluster to provide resilience things can get a lot more challenging. We also want to manage the number of active containers – we don’t want to have unnecessary volumes of containers effectively idling. So how do we manage this?
In addition to this, what if we’re using services that demand tens of seconds or even minutes to be spun up to a point of readiness – such as instantiating database servers, adding new nodes to data caches such as Coherence which will need time to clone data, and adjust the demand balancing algorithms? Likewise, for more traditional application servers. Some service calls will impact upstream configuration changes, such as altering load-balancing configurations. Cloud-native Load Balancers typically can understand node groups, but what if your configuration is more nuanced? If you’re running services such as ActiveMQ you need to update all the impacted nodes in a cluster to be aware of the new node. Bottomline is some solutions or solution parts need lead time to handle increased demand?
This points to more advanced, nuanced metrics than simply current CPU load. And possibly the scaling algorithm needs to be aware of lead times of the different types of functionality involved. So how can we advance a more nuanced, and informed scaling logic? You could look at the inbound traffic on firewalls or load balancers. But this will require a fair bit of additional effort to apply application context. For example is the traffic just getting directed to static page content? We do need to derive some context so that the right rules are impacted. Even in simple K8s only hosted solutions a cluster may host services that aren’t related to the changes in demand and need to be scaled as a result.
A use case perspective
Let’s look at this from a hypothetical use case. We’re a music streaming service. Artists can control when their music is made available, but the industry norm is 12:01am on a Friday morning. There is always a demand spike at this time, but the size of the demand spike can vary, with some artists triggering larger spikes (this isn’t directly correlating to an artist’s popularity, some smaller groups can have very enthusiastic fans) – so dynamic scaling is needed, and reactive to demand. Reporting, analytics, and payment services see cyclical bumps around the monthly financial periods. These monthly cyclic activities can also be done during quieter operating hours. So it is clear we may wish to apply logical partitioning, but for maximum cost efficiency keep everything in the same cluster. There are correlations between different service demands. Certain data services see increased demand during the demand spikes and reporting period, but ‘The bottom line is we need to not only address dynamic scaling, but tailor the scaling to different services at different times.
Back to our question – how do we manage the scaling? We could monitor the firewall and load balancer logs and analyze the kinds of requests being received. That would need additional processing logic to determine which services are receiving the traffic. But our API gateway is likely to have that intelligence implicitly in place as we have different API policies for the different types of endpoints. So we can monitor specific endpoints or groups of endpoints very easily – meaning we can infer the types of traffic demand and how to respond. Not only that, we may have API plans in place so we can control priority and prevent the free versions of our service from using APIs to initiate high-quality media streams. So we already have business and specific process meaning. So linking scaling controls such as KEDA (Kubernetes Event-driven Autoscaling) directly to measurements such as plans and specific APIs creates a relatively easy way to control scaling. Further, we may also use the gateways to provide a rate throttle so it’s not possible to crash our backend with an instantaneous spike. This strategy isn’t that different from an approach we’ve demonstrated for scaling message processing backends (see here and here).
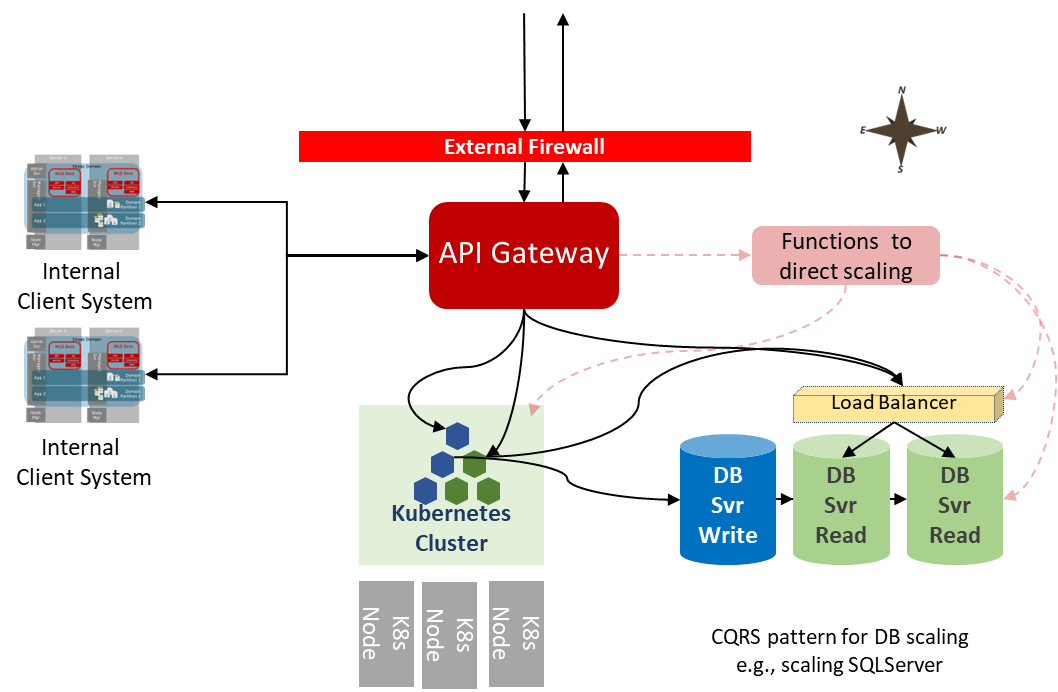
We can also use the data KEDA can see in terms of node readiness to adjust the API Gateway rate limiting dynamically as well. Either as a direct trigger from the number of active container instances or by triggering a more advanced check because we still have to address our services that need more lead time before relaxing the rate limiting.
Handling slow scaling services
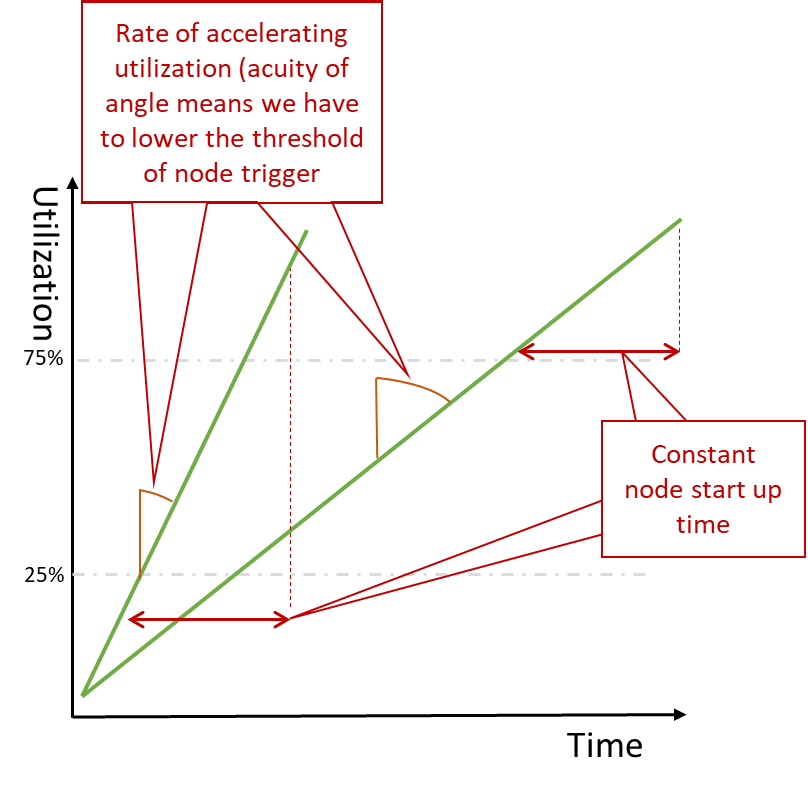
So we’ve got a way of targeting the scaling of services. But what do we do to address the slower scaling services we described? With the data dimensioned, we can do a couple of things. Firstly we can use the rate of change to determine how many nodes to add. A very sudden increase in demand and adding a node at a time will create the effect of the service performance stuttering as it scales, and all additional capacity is suddenly consumed and then scales again. Factoring in the rate of change to the workload threshold and the context of which services could generate the increased workload can be used to not only determine which databases may need scaling but also be used to adjust the threshold of workload that actually triggers the node introduction. So a sudden increase in demand on services that are known to create a lot of DB activity is then met with dropping the threshold that triggers new nodes from, say, 75% to 25% so we effectively start the nodes on a lower threshold, means the process is effectively started sooner.
For this to be fully effective we do need the Gateway tracking traffic both internally (East-West) and inbound (North-South). Using the gateway with East-West traffic means that we can establish an anti corruption layer.
Conclusion
Not all parts of a solution will be instantaneous in scaling – regardless of how fast the code startup cycle might be, some services have to address the need to move large chunks of data before becoming ready, e.g., in-memory databases. Some services may not have been built for the latest business demands and the ability to exploit cloud scale and dynamic scaling. Some services need time to adjust configurations.
We may also need to adjust our protection mechanisms if we’re protecting against service overloading.
Scaling capabilities that have response latency to the scaling process can be addressed by achieving earlier, more intelligent recognition of need than warning simply by CPU loads hitting a threshold. The intelligence that can be derived from implicit service context simplifies the effort in creating such intelligence and makes it easier to recognize the change. API Gateways, message queues, message streams, and shared data storage are all means that, by their nature, have implicit context.
Pushing the recognition towards the front of the process creates milliseconds or possibly seconds more warning of the demand than waiting for the impacted nodes to see compute spikes.
 The news about Oracle offering some
The news about Oracle offering some 
You must be logged in to post a comment.