's Blog")
Tags
AI, artificial-intelligence, Cloud, Data Drift, development, Fluent Bit, GenAI, Machine Learning, ML, observability, Security, Technology, Tensor Lite, TensorFlow
These days, everywhere you look, there are references to Generative AI, to the point that what have Fluent Bit and GenAI got to do with each other? GenAI has the potential to help with observability, but it also needs observation to measure its performance, whether it is being abused, etc. You may recall a few years back that Microsoft was trailing new AI features for Bing, and after only having it in use for a couple of days, it had been recorded generating abusive comments and so on (Microsoft’s Tay is such an example).
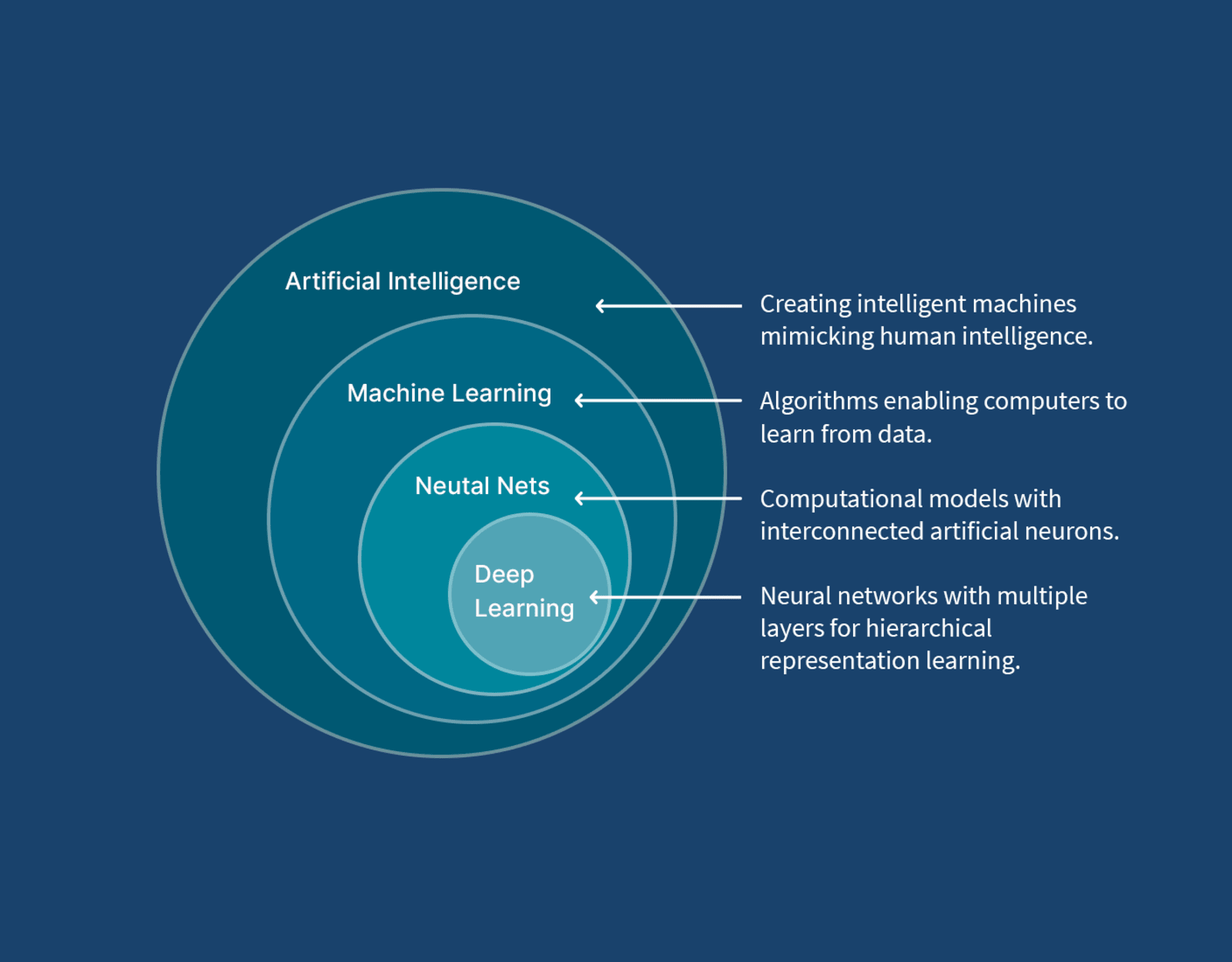
But this isn’t the aspect of GenAI (or the foundations of AI with Machine Learning (ML)) I was thinking about. Fluent Bit can be linked to GenAI through its TensorFlow plugin. Is this genuinely of value or just a bit of ‘me too’?
There are plenty of backend use cases once the telemetry has been incorporated into an analytics platform, for example:
- Making it easy to query and mine the observability data, such as natural language searching – to simplify expressing what is being looked for.
- Outlier / Anomaly detection – when signals, particularly metrics, diverge from the normal patterns of behavior, we have the first signs of a problem. This is more Machine Learning than generative AI.
- Using AI agents to tune monitoring thresholds and alerting scenarios
But these are all backend, big data style use cases and do not center on Fluent Bit’s core value of getting data sources to appropriate destination systems for such analysis or visualization.
To incorporate AI into Fluent Bit pipelines, we need to overcome a key issue – AI tends to be computationally heavy – making it potentially too slow for streams of signals being generated by our applications and too expensive given that most logs reflecting ‘business as usual’ are, in effect, low value.
There are some genuine use cases where lightweight AI can deliver value. First, we should be a little more precise. The TensorFlow plugin is the TensorFlow Lite version, also known as LiteRT. The name comes from the fact that it is a lite-weight solution intended to be deployable using small devices (by AI standards). This fits the Fluent Bit model of having a small footprint.
So, where can we put such a use case:
- Translating stack traces into actionable information can be challenging. A trained ML or AI model can help classify and characterize the cause of a stack trace. As a result, we can move from the log to triggering appropriate actions.
- Targeted use cases where we’ve filtered out most signal data to help analyze specific events – for example, we want to prevent the propagation of PII data downstream. Some PII data can be easily isolated through patterns using REGEX. For example, credit card IDs are a pattern of 4 digits in 4 groups. Phone numbers and email addresses can also be easily identified. However, postal addresses aren’t easy, particularly when handling multinational addresses, where the postal code/zip code can’t be used as an indicative pattern. Using AI to help with such checks means we must filter out signals to only examine messages that could accidentally carry such information.
When adopting AI into such scenarios, we have to be aware of the problems that can impact the use of ML and AI. These use cases are less high profile than the issues of hallucinations but just as important. As we’re observing software, which will change over time. As a result, payloads or data shifts (technically referred to as data drift) and the detection rate can drop. So, we need to measure the efficacy of the model. However, issues such as data drift need to be taken into account, as the scenario being detected may change in volume, reflecting changes in software usage and/or changes in how the solution works.

There are ways to help address such considerations, such as tracking false positive outcomes, and if the model can provide confidence scoring, is there a trend in the score?
Conclusion
There are good use cases for using Machine Learning (and, to an extent, Artificial Intelligence) within an observability pipeline – but we have to be selective in its application as:
- The cost of the computation can outweigh the benefits
- The execution time for such computation can be notably slower than our pipeline, leading to risks of back pressure if applied to every event in the pipeline.
- The effectiveness and how much data drift might occur (we might initially see very good results, but then things can fall off).
Possibly, the most useful application is when the AI/ML engine has been trained to recognize patterns of events that preceded a serious operational issue (strictly, this is the use of ML).
Forward-looking
The true potential for Gen AI is when we move beyond isolating potential faults based on pattern recognition to using AI to help recommend or even trigger remediation processes.

You must be logged in to post a comment.