's Blog")
Tags
AI, artificial-intelligence, attack, attacks, cybersecurity, MCP, model context protocol, Paper, Security, Technology, vectors
MCP (Model Context Protocol) has really taken off as a way to amplify the power of AI, providing tools for utilising data to supplement what a foundation model has already been trained on, and so on.
With the rapid uptake of a standard and technology that has been development/implementation led aspects of governance and security can take time to catch up. While the use of credentials with tools and how they propagate is well covered, there are other attack vectors to consider. On the surface, it may seem superficial until you start looking more closely. A recent paper Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions highlights this well, and I thought (even if for my own benefit) to explain some of the vectors.
I’ve also created a visual representation based on the paper of the vectors described.
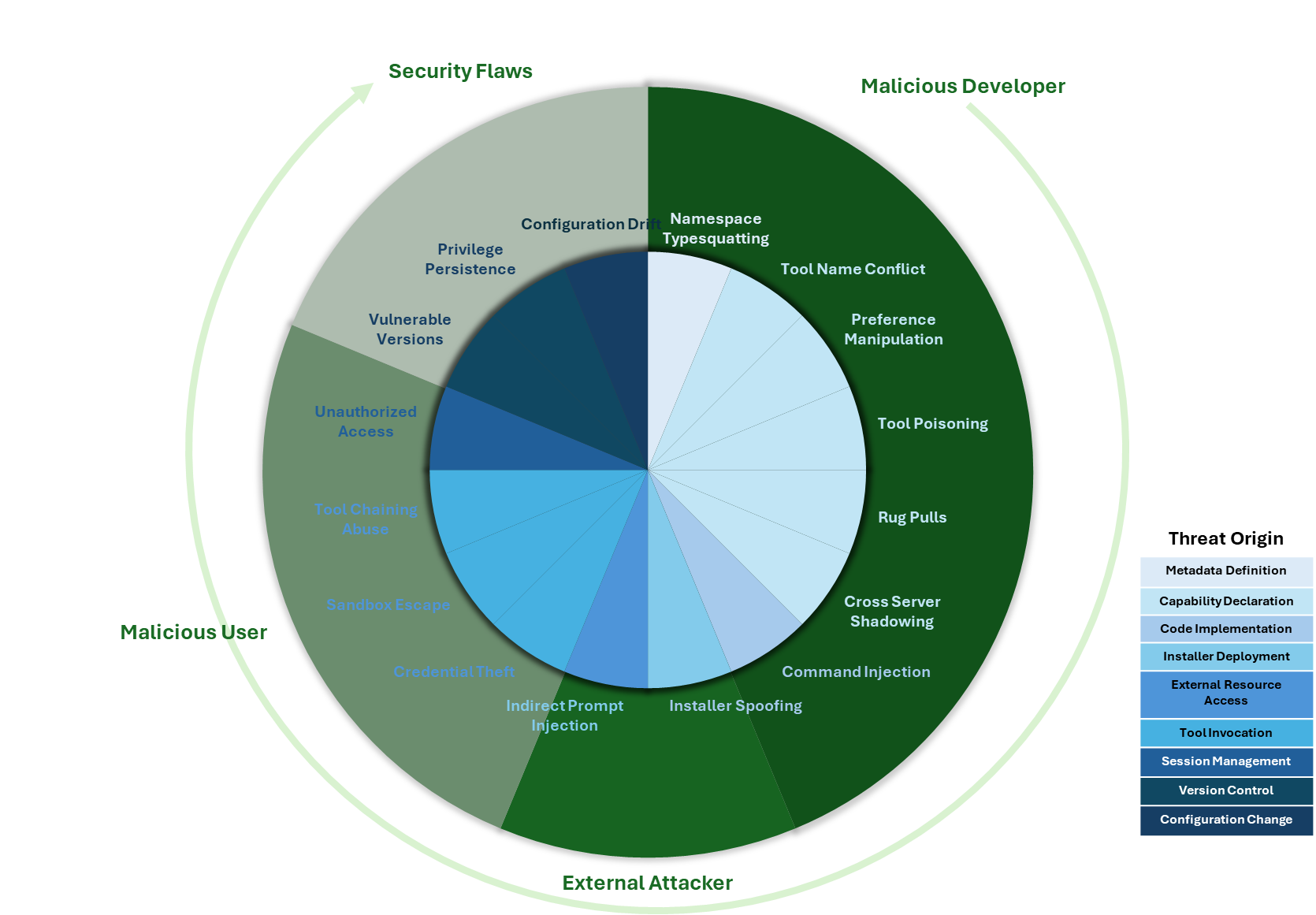
The inner ring represents each threat, with its color denoting the likely origin of the threat. The outer ring groups threats into four categories, reflecting where in the lifecycle of an MCP solution the threat could originate.
I won’t go through all the vectors in detail, though I’ve summarized them below (the paper provides much more detail on each vector). But let’s take a look at one or two to highlight the unusual nature of some of the issues, where the threat in some respects is a hybrid of potential attack vectors we’ve seen elsewhere. It will be easy to view some of the vectors as fairly superficial until you start walking through the consequences of the attack, at which point things look a lot more insidious.
Several of the vectors can be characterised as forms of spoofing, such as namespace typosquatting, where a malicious tool is registered on a portal of MCP services, appearing to be a genuine service — for example, banking.com and bankin.com. Part of the problem here is that there are a number of MCP registries/markets, but the governance they have and use to mitigate abuse varies, and as this report points out, those with stronger governance tend to have smaller numbers of services registered. This isn’t a new problem; we have seen it before with other types of repositories (PyPI, npm, etc.). The difference here is that the attacker could install malicious logic, but also implement identity theft, where a spoofed service mimics the real service’s need for credentials. As the UI is likely to be primarily textual, it is far easier to deceive (compared to, say, a website, where the layout is adrift or we inspect URIs for graphics that might give clues to something being wrong). A similar vector is Tool Name Conflict, where the tool metadata provided makes it difficult for the LLM to distinguish the correct tool from a spoofed one, leading the LLM to trust the spoof rather than the user.
Another vector, which looks a little like search engine gaming (additional text is hidden in web pages to help websites improve their search rankings), is Preference Manipulation Attacks, where the tool description can include additional details to prompt the LLM to select one solution over another.
The last aspect of MCP attacks I wanted to touch upon is that, as an MCP tool can provide prompts or LLM workflows, it is possible for the tool to co-opt other utilities or tools to action the malicious operations. For example, an MCP-provided prompt or tool could ask the LLM to use an approved FTP tool to transfer a file, such as a secure token, to a legitimate service, such as Microsoft OneDrive, but rather than an approved account, it is using a different one for that task. While the MCP spec says that such external connectivity actions should have the tool request approval, if we see a request coming from something we trust, it is very typical for people to just say okay without looking too closely.
Even with these few illustrations, tooling interaction with an LLM comes with deceptive risks, partially because we are asking the LLM to work on our behalf, but we have not yet trained LLMs to reason about whether an action’s intent is in the user’s best interests. Furthermore, we need to educate users on the risks and telltale signs of malicious use.
Attack Vector Summary
The following list provides a brief summary of the attack vectors. The original paper examines each in greater depth, illustrating many of the vectors and describing possible mitigation strategies. While many technical things can be done. One of the most valuable things is to help potential users understand the risks, use that to guide which MCP solutions are used, and watch for signs that things aren’t as they should be.
Continue reading


You must be logged in to post a comment.