's Blog")
Tags
AI, artificial-intelligence, Cloud, Fluentbit, Fluentd, LLM, observability, OpAMP, Technology
With KubeCon Europe happening this week, it felt like a good moment to break cover on this pet project.
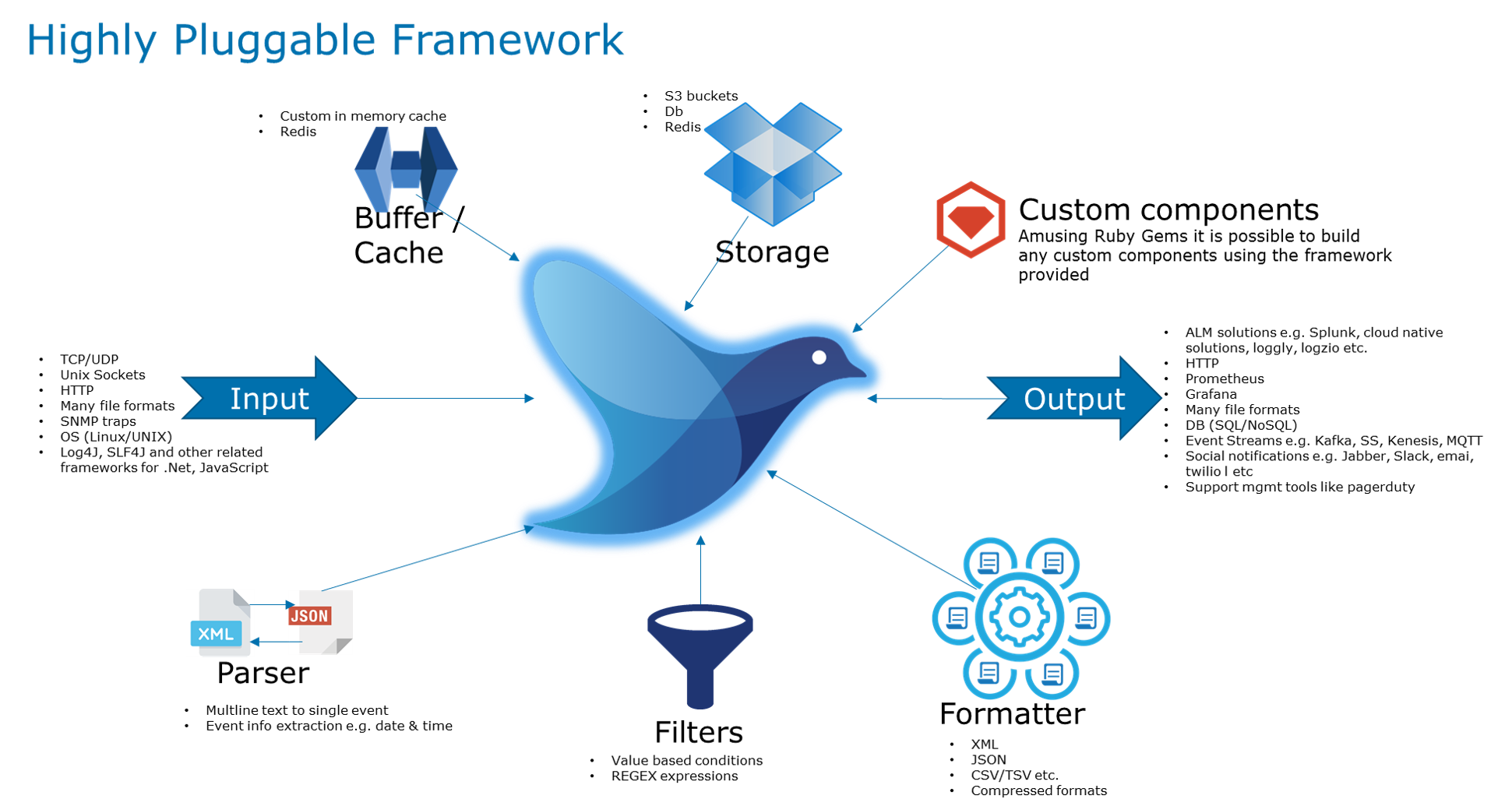
If you are working with Fluent Bit at any scale, one question keeps coming up: how do we consistently control and observe all those edge agents, especially outside a Kubernetes-only world?
This is exactly the problem the OpAMP specification is trying to solve. At its core, OpAMP defines a standard contract between a central server and distributed agents/supervisors, so status, health, commands, and config-related interactions follow one protocol instead of ad-hoc integration per tool.
That is where this project sits. We’re implementing the OpAMP specification to support Fluent Bit (and later Fluentd).
In this implementation, we have:
- a provider (the OpAMP server), and
- a consumer acting as a supervisor to manage Fluent Bit deployments.
Right now, we are focused on Fluent Bit first. That is deliberate: it keeps scope practical while we validate the framework. The same framework is being shaped so it can evolve to support Fluentd as well.
The repository for the implementation can be found at https://github.com/mp3monster/fluent-opamp
Quick summary
The provider/server is the control plane endpoint. It tracks clients, accepts status, queues commands, and returns instructions using OpAMP payloads over HTTP or WebSocket.
The consumer/supervisor handles the local execution and reporting. It launches Fluent Bit, polls local health/status endpoints, sends heartbeat and metadata to the provider, and handles inbound commands (including custom ones). The server and supervisor can be deployed independently, which is important for real-world rollout patterns.
Because they follow the OpAMP protocol model, clients and servers can be interchanged with other OpAMP-compliant implementations (although we’ve not yet tested this aspect of the development).
Together, they give us a manageable, spec-aligned path to coordinating distributed Fluent Bit nodes without hard-coding one-off control logic into every environment.
Deployment options and scripts
There are a few practical ways to get started quickly:
- Deploy just the server/provider using
scripts/run_opamp_server.sh(orscripts/run_opamp_server.cmdon Windows). - Deploy just the client/supervisor using
scripts/run_supervisor.sh(orscripts/run_supervisor.cmdon Windows). - Run both components either together in a single environment or independently across different hosts.
The scripts will set up a virtual environment and retrieve the necessary dependencies.
If you want an initial MCP client setup as part of your workflow, there are helper scripts for that too:
mcp/configure-codex-fastmcp.shandmcp/configure-codex-fastmcp.ps1mcp/configure-claude-desktop-fastmcp.shandmcp/configure-claude-desktop-fastmcp.ps1
Server screenshots
Here is a first server view we can include in the post:
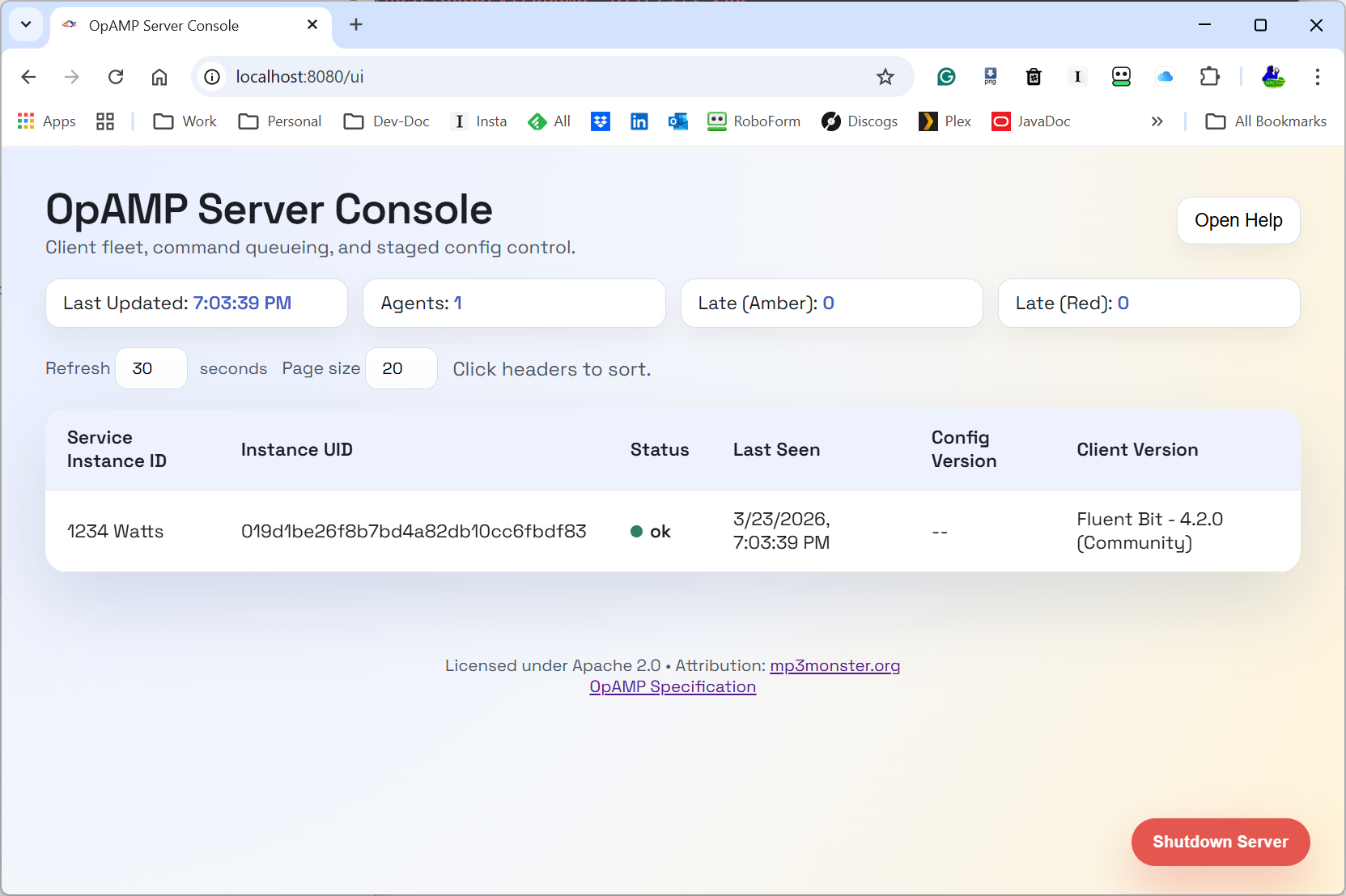
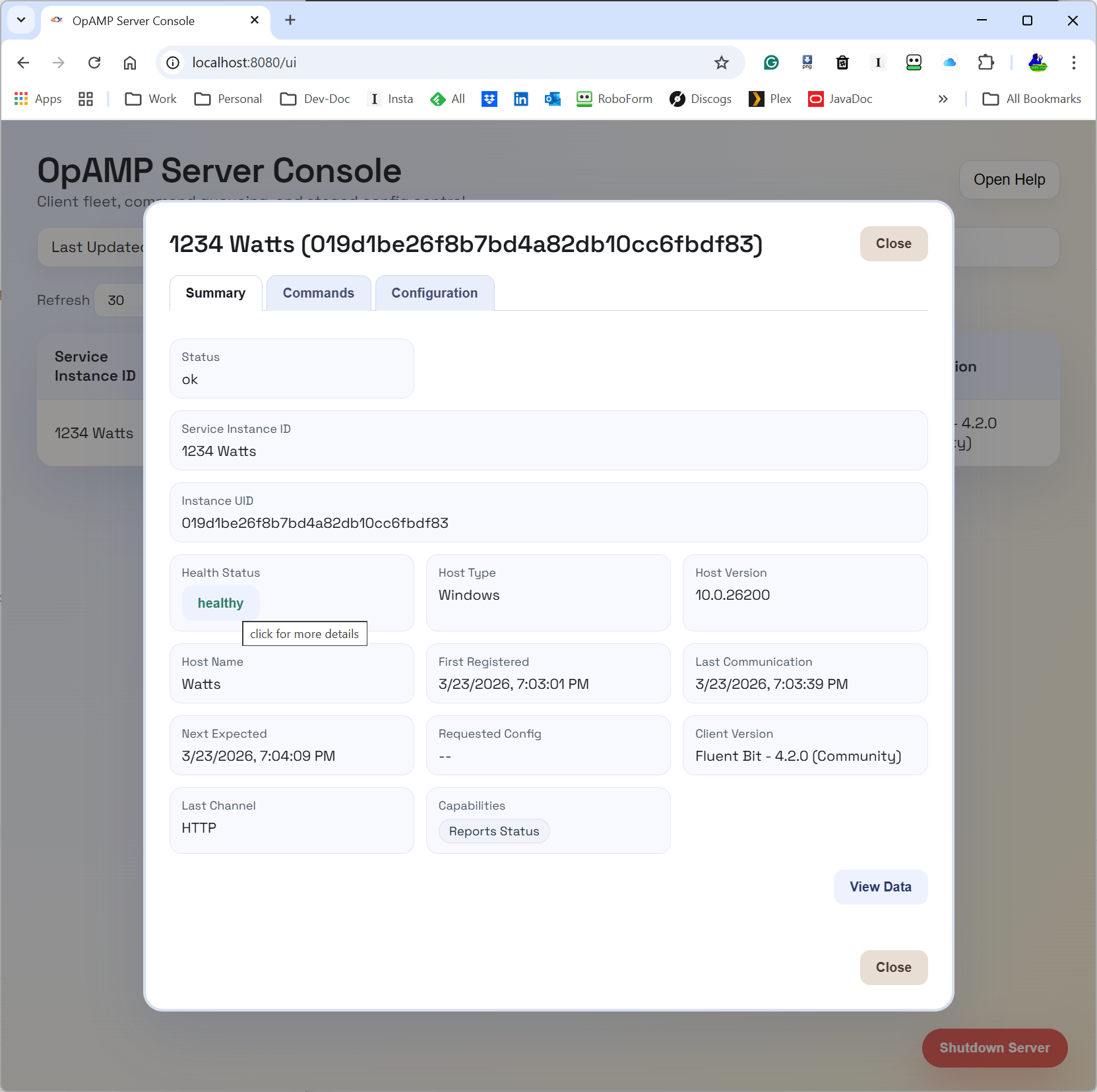
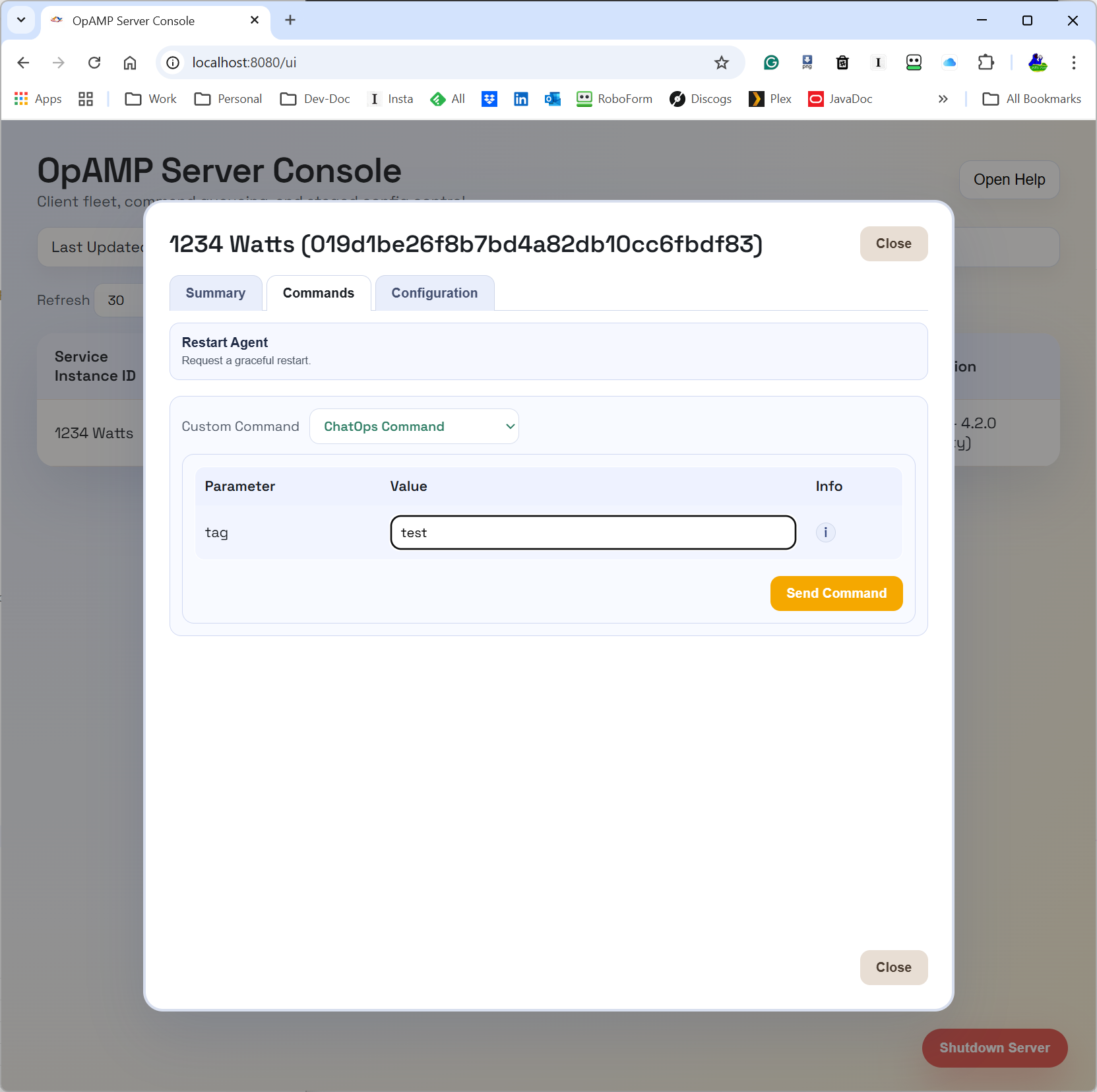
The UI is still evolving, but this gives a concrete picture of the provider side control plane we are discussing.
What the OpAMP server (provider) does
The provider is responsible for the shared view of fleet state and intent.
Today it provides:
- OpAMP transport endpoints (
/v1/opamp) over HTTP and WebSocket. - API and UI endpoints to inspect clients and queue actions.
- In-memory command queueing per client.
- Emission of standard command payloads (for example, restart).
- Emission of custom message payloads for custom capabilities.
- Discovery and publication of custom capabilities supported by the server side command framework.
Operationally, this means we can queue intent once at the server and let the next client poll/connection cycle deliver that action in protocol-native form.
What the supervisor (consumer) does for Fluent Bit
The supervisor is the practical glue between OpAMP and Fluent Bit:
- Starts Fluent Bit as a local child process.
- Parses Fluent Bit config details needed for status polling.
- Polls Fluent Bit local endpoints on a heartbeat loop.
- Builds and sends
AgentToServermessages (identity, capabilities, health/status context). - Receives
ServerToAgentresponses and dispatches commands. - Handles custom capabilities and custom messages through a handler registry.
So for Fluent Bit specifically, the supervisor gives us a way to participate in OpAMP now, even before native in-agent OpAMP support is universal.
And to be explicit: this is the current target. Fluentd support is a planned evolution of this same model, not a separate rewrite.
Where ChatOps fits
ChatOps is where this gets interesting for day-2 operations.
In this implementation, ChatOps commands are carried as OpAMP custom messages (custom capability org.mp3monster.opamp_provider.chatopcommand). The provider queues the custom command, and the supervisor’s ChatOps handler executes it by calling a local HTTP endpoint on the configured chat_ops_port.
That gives us a cleaner control path:
- Chat/user intent can go to the central server/API.
- The server routes to the right node through OpAMP.
- The supervisor performs the local action and can return failure context when local execution fails.
This is a stronger pattern than directly letting chat tooling call every node individually, and it opens the door to better auditability and policy controls around who can trigger what.
Reality check: we are still testing
This is important: we are still actively testing functionality.
Current status is intentionally mixed:
- Core identity, sequencing, capabilities, disconnect handling, and heartbeat/status pathways are in place.
- Some protocol fields are partial, todo, or long-term backlog.
- Custom capabilities/message pathways are implemented as a practical extension point and are still being hardened with test coverage and real-world runs.
So treat this as a working framework with proven pieces, not a finished all-capabilities implementation.
What is coming next (based on docs/features.md)
Near-term priorities include:
- stricter header/channel validation,
- heartbeat validation hardening,
- payload validation against declared capabilities,
- server-side duplicate websocket connection control behaviour.
Broader roadmap themes include:
- authentication/security model for APIs and UI,
- persistence in the provider,
- richer UI controls for node/global polling and multi-node config push,
- certificate and signing workflows,
- packaging improvements.
And yes, a key strategic direction is evolving the framework abstraction so it can support Fluentd in due course, not only Fluent Bit. Some feature areas (like package/status richness) make even more sense in that broader collector ecosystem.
Why this matters
OpAMP gives us a standard envelope for control-plane interactions; the server/supervisor split gives us pragmatic deployment flexibility; and ChatOps provides a human-friendly control surface.
Put together, this becomes a useful pattern for managing telemetry agents in real environments where fleets are mixed, rollout velocity matters, and “just redeploy everything” is not always an option.
If you are evaluating this right now, the right mindset is: useful today, promising for tomorrow, and still under active verification as we close feature gaps.

You must be logged in to post a comment.