Back in 2018, Manning published Chris Richardson‘s Microservices Patterns book. In many respects, this book is the microservices version of the famous Gang of Four patterns book. The exciting news is that Chris is working on a second edition.
One key difference between the GoF book and this is that engaging with patterns like Inversion of Control, Factories, and so on isn’t impacted by considerations around architecture, organization, and culture.
While the foundational ideas of microservices are established, the techniques for designing and deploying have continued to evolve and mature. If you follow Chris through social media, you’ll know he has, in the years since the book’s first edition, worked with numerous organisations, training and helping them engage effectively with microservices. As a result, a lot of processes and techniques that Chris has identified and developed with customers are grounded in real practical experience.
As the book is in its early access phase (MEAP), not all chapters are available yet, so plenty to look forward to.
So even if you have the 1st edition and work with microservice patterns, the updates will, I think, offer insights that could pay dividends.
If you’re starting your software career or considering the adoption of microservices (and Chris will tell you it isn’t always the right answer), I highly recommend getting a copy, as with the 1st edition, the 2nd will become a must-read book.
One of the benefits of being an author with a publisher like Manning is being given early access to books in development and being invited to share my thoughts. Recently, I was asked if I’d have a look at Think Distributed Systems by Dominik Tornow.
Systems have become increasingly distributed for years, but the growth has been accelerating fast, enabled by technologies like CORBA, SOAP, REST frameworks, and microservices. However, some distribution challenges even manifest themselves when using multithreading applications. So, I was very interested in seeing what new perspectives could be offered that may help people, and Dominik has given us a valuable perspective.
I’ve been fortunate enough that my career started with working on large multi-server, multithreaded mission-critical systems. Using Ada and working with a mentor who challenged me to work through such issues. How does this relate to the book? This work and the mentor meant I built some good mental models of distributed development early in my career. Dominik calls out that having good mental models to understand distributed systems and the challenges they can bring is key to success. It’s this understanding that equips you to understand challenges such as resource locking, contending with mutual deadlock, transaction ordering, the pros and cons of optimistic locking, and so on.
As highlighted early on in this book, most technical books come from the perspective of explaining tools, languages, or patterns and to make the examples easy to follow, the examples tend to be fairly simplistic. This is completely understandable; these books aim to teach the features of the language. Not how to bring these things to bear in complex real-world use cases. As a result, we don’t necessarily get the fullest insight and understanding of the problems that can come with optimistic locking.
Given the constraints of explaining through the use of programming features, the book takes a language-agnostic approach to explaining the ideas, and complexities of distributed solutions. Instead, the book favors using examples, analogies, and mathematics to illustrate its points. The mathematics is great at showing the implications of different aspects of distributed systems. But, for readers like me who are more visual and less comfortable with numeric abstraction, this does mean some parts of the book require more effort – but it is worth it. You can’t deny hard numeric proofs can really land a message, and if you know what the variables are that can change a result, you’re well on your way.
For anyone starting to design and implement distributed and multi-threaded applications for the first time, I’d recommend looking at this book. From what I’ve seen so far, the lessons you’ll take away will help keep you from walking into some situations that can be very difficult to overcome later or, worse, only manifest themselves when your system starts to experience a lot of load.
My day job as a technical architect means I spend a lot of time working on and around technical non-functional needs, from observability to APIs. And APIs are everywhere (sometimes we don’t talk about things like the OpenTelemetry Protocol (OTLP) as APIs, but this is what it is). and I’ve written and blogged on the subject many times in the past.
One of the things I tend to do is read books on the subject – always on the lookout for new strategies, ideas, and techniques for handling an API’s number one challenge – security. With a new book on Secure APIs from José Haro Peralto being published by Manning (as a Manning author, I have the perks of looking at books published and in the Early Access Program).
The Early Access Program means that after the first couple of chapters have been written and go through initial review processes, they’re made available. However, the book is still in development and has not gone through a full copy edit process. However, the core ideas and messages are there in the book.
The book so far looks really good. It comes across as very practical and illustrative of the points it needs from the outset, with some nicely presented insights about why API Security is such an important consideration—54% of web traffic is API-driven, organizations see as many as 10 million attacks per day, and a breach typically costs $6.1 million. If you’re trying to make a case for investing in API security – there are some great references here.
The book doesn’t just look at implementing the code that powers the API contract but also the tools from firewalls to gateways. It engages in the process of figuring out what risks an API needs to mitigate and the consequences of failing to do so. While the first couple of chapters look at the broader landscape and ideas. We can expect a closer look at things like the OWASP Top 10 (a resource that should be mandatory learning for anyone going to implement APIs or web app development more generally) as the book progresses.
The first couple of chapters read well and are easy to absorb, and we’re looking forward to reading the coming chapters, which will discuss the nuts and bolts of securing APIs.
The only observation to be aware of at this point is that, while not explicitly stated, the illustrations suggest a strong bias to RESTful web services with the appearance of just the Open API Initiative logo. While REST is the most common API approach, gRPC, and GraphQL are continuing to make big inroads and are supported by the Asynchronous API Spec. I suspect this will be addressed given José’ background and expertise. I#m looking forward to the coming chapters.
With the Christmas holidays happening, things slowed down enough to sit and catch up on some reading – which included reading Cloud Observability in Action by Michael Hausenblas from Manning. You could ask – why would I read a book about a domain you’ve written about (Logging In Action with Fluentd) and have an active book in development (Fluent Bit with Kubernetes)? The truth is, it’s good to see what others are saying on the subject, not to mention it is worth confirming I’m not overlapping/duplicating content. So what did I find?
Cloud Observability in Action by Michael Hausenblas
Cloud Observability In Action has been an easygoing and enjoyable read. Tech books can sometimes get a bit heavy going or dry, not the case here. Firstly, Michael went back to first principles, making the difference between Observability and monitoring – something that often gets muddied (and I’ve been guilty of this, as the latter is a subset of the former). Observability doesn’t roll off the tongue as smoothly as monitoring (although I rather like the trend of using O11y). This distinction, while helpful, particularly if you’re still finding your feet in this space, is good. What is more important is stepping back and asking what should we be observing and why we need to observe it. Plus, one of my pet points when presenting on the subject – we all have different observability needs – as a developer, an ops person, security, or auditors.
Next is Michael’s interesting take on how much O11y code is enough. Historically, I’ve taken the perspective – that enough is a factor of code complexity. More complex code – warrants more O11y or logging as this is where bugs are most likely to manifest themselves; secondly, I’ve looked at transaction and service boundaries. The problem is this approach can sometimes generate chatty code. I’ve certainly had to deal with chatty apps, and had to filter out the wheat from the chaff. So Michael’s approach of cost/benefit and measuring this using his B2I ratio (how much code is addressing the business problems over how much is instrumentation) was a really fresh perspective and presented in a very practical manner, with warnings about using such a measure too rigidly. It’s a really good perspective as well if you’re working on hyperscaling solutions where a couple of percentage point improvements can save tens of thousands of dollars. Pretty good going, and we’re only a couple of chapters into the book.
The book gets into the underlying ideas and concepts that inform OpenTelemetry, such as traces and spans, metrics, and how these relate to Observability. Some of the classic mistakes are called out, such as dimensioning metrics with high cardinality and why this will present real headaches for you.
As the data is understood, particularly metrics you can start to think about how to identify what normal is, what is abnormal, or an outlier. That then leads to developing Service Level Objectives (SLOs), such as an acceptable level of latency in the solution or how many errors can be tolerated.
The book isn’t all theory. The ideas are illustrated with small Go applications, which are instrumented, and the generated metrics, traces, and logs. Rather than using a technology such as Fluentd or Fluent Bit, Michael starts by keeping things simple and directly connecting the gathering of the metrics into tools such as Prometheus, Zipkin, Jaeger, and so on. In later chapters, the complexity of agents, aggregators, and collectors is addressed. Then, the choices and considerations for different backend solutions from cloud vendor-provided services such as OpenSearch, ElasticSearch, Splunk, Instana and so on. Then, the front-end visualization of the data is explored with tools such as Grafana, Kibana, cloud-provided tools, and so on.
As the book progresses, the chapters drill down into more detail, such as the differences and approaches for measuring containerized solutions vs. serverless implementations such as Lambda and the kinds of measures you may want. The book isn’t tied to technologies typically associated with modern Cloud Native solutions, but more traditional things like relational databases are taken into account.
The closing chapters address questions such as how to address alerting, incident management, and implementing SLOs. How to use these techniques and tools can help inform the development processes, not just production.
So I would recommend the book, if you’re trying to understand Observability (regardless of a cloud solution or not). If you’re trying to advance from the more traditional logging to a fuller capability, then this book is a great guide, showing what, why, and how to evaluate the value of doing so.
To come back to my opening question. The books have small points of overlap, but this is no bad thing, as it helps show how the different viewpoints intersect. I would actually say that the Observability in Action shows how the wider landscape fits together, the underlying value propositions that can help make the case for implementing a full observability solution. Then, Logging in Action and the new book, Fluent Bit with Kubernetes, give you some of the common context, and we drill into the details of how and what can be done with Fluent Bit and Fluentd. All Manning needs now is content to deep dive into Prometheus, Grafana, Jaeger, and OpenSearch to provide an end-to-end coverage of first principles to the art of the possible in Observability.
I also have to thank Michael for pointing his readers and sections of Logging in Action that directly relate and provide further depth into an area.
One of the benefits of being a Manning author is that we get access to the Manning book catalog, including those currently in the MEAP early access programme (MEAP). The Road to Kubernetes title was bought to my attention. The book has just become available as a MEAP title; this means that the book has just completed its first major review milestone, and about a third of the book has been written. It does mean our review only covers the first 3 chapters at the moment.
What got my attention with this book is that unlike other titles about Kubernetes \9of which there are a number of great titles in the Manning portfolio already) is that it has adopted a different approach.
Most books focus on one technology and deep dive into that technology and dig into the more advanced features of that specific area. For an experienced IT person, that is great. But, when it comes to Kubernetes, if you’re skills are largely just focused on largely coding with languages like Java, Python, and JavaScript – not unusual for a graduate or junior developers it means the amount of reading and learning curve to get to grips with developing and deploying containers to Kubernetes is considerable. Here, Justin has taken the approach of assuming basic development skills and then taking you on a journey of focussing on the basics of containers, deployment automation, and then Kubernetes with just enough to be able to deploy a simple solution using good practices. This makes the learning path to gaining the skills that allow you to work within a team and building containerized solutions a lot easier.
I imagine once the book is complete and you’ve followed it through, you’ll be in a position to focus on learning new, more advanced aspects of containers and Kubernetes in a focused manner to meet the needs of a day-to-day job.
Having coached and mentored junior developers and graduates, this is a book I’d recommend to help them along, and if my experience with the Manning book development process is anything to go by, as Justin goes through the major milestones, this book will go from good to great.
My only word of caution is that this book will take the reader on a journey of building and deploying microservices to Kubernetes. Don’t be fooled into thinking Kubernetes and microservices are easy – there is a lot of technologies that I don’t think the book will go into (but then not all developers need to understand details such the differences in network fabric (Calico, Flannel) or container engines cri-o, Docker Engine, deploying support tooling for things like observability). Without good design and, depending upon your solution, a handle in a variety of more specialized areas, it is still possible to get yourself into a mess, even for the most experienced of teams.
The Phoenix Project by Gene Kim has been recommended reading for the IT industry for a long time now. It’s been on my to-read list for a good while, but to be candid, it never made the top of my reading list, as I had some reservations. Who wants to read a novel about IT if you already work and live it every day.
Recently IT Revolution, to celebrate its 10th anniversary, offered the book through Amazon for free for a limited period (even now, as a Kindle ebook, it isn’t that expensive anymore). Given I had determined I should read it at some point, I took the opportunity to get a copy. As it happens, through the Christmas break, I got into a run of reading books, and with it being at the top of my ebook list, I bit the bullet.
First of all, the story was engaging and very readable, characters are likable, human, and relatable. It isn’t a huge book either (perhaps I’ve been looking at too many 500+ page novels), making it a fairly quick read. As a pure novel, some of the devices to keep the narrative moving along were perhaps a little obvious, but then given the goal of the story, that isn’t really an issue. It didn’t break the reading flow, which did keep the pages turning with a plausible story; plausible enough to wonder how much of the story was based on a real-life experience of Gene or one of his writing collaborators.
What struck me the most is that most industry writing I have read doesn’t address all the points the book makes. So, DevOps, as is typically presented by a lot (most ?) content, uses some variation of a diagram like the infinite cycle, as shown here:
Not only that, it is common to view DevOps as focusing on either :
Automation, particularly around CI/CD and IaC (Infrastructure as Code)
The development team also owns the operations tasks
But the book portrayed DevOps as both and neither of these. I say this as these approaches can help with the goal, but they should be subservient to the larger objective. Unfortunately, we do get caught up with the mechanics and tools and not the wider goal. The story is about how to deliver business value and needs in a streamlined manner, so we aren’t tying up the investment (time or spend) any longer than necessary. Yes, that does mean IaC and CI/CD style automation but only in service of the goal, which is the business need, not IaC.
The book also highlights the point of continuously working on improvement and paying down against debt, as removing debt is part of the way we remove the blockages to the streamlining (in the story, we actually see the release pipeline being temporarily stopped so that time could be invested in paying down the debt). Yet, this aspect is rarely discussed in a lot of the industry content on the subject. Maybe we are, in part, our own enemy here, as debit work is not greenfield. It is going back over old ground and making it better. We all love breaking new ground and leaving the past behind. Not to mention many organizations measure progress on the number of features rather than how well a feature serves the business goals. I have to admit to that mistake, which in our world of microservices is a bit of a mistake. After all, aren’t microservices about doing one thing and doing it well?
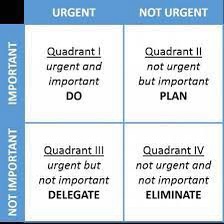
Another interesting view that the book put a lot of emphasis on was a variant of what is sometimes called the Eisenhower matrix. Anyone who has done any leadership training will most likely recognize it (see below).
However, the quadrants of work are as the book describes them are:
Quadrant 1 – Project work (i.e., planned activities central to the business)
Quadrant II – IT work (work that is planned and needed but doesn’t originate from the business, such as building new infrastructure)
Quadrant III – Updates and changes (e.g., system patching)
Quadrant IV – Unplanned (e.g., outage recovery work, demands on the team that has bypassed scheduling / divert individuals from the agreed goals, etc.)
The key difference between this representation and that of the book’s work definition is the words on each of the columns and rows. For example, Quadrant IV isn’t ‘Not Important’ and ‘Not Urgent’ – but it would be fair to say ‘Not Wanted’ and ‘Not Productive’. Unplanned work is the killer and roughly aligns with quadrant IV. This comes from the issues of not dealing with technical debt and solution facilities etc.
My last observation is that in the last couple of years, we have seen the rise of DevSecOps, which recognizes the need that security should be as much of the delivery process as Dev and Ops. The book (written 10 years ago) showed that security should be part of the DevOps process. Like other areas, the story seeks to address the point that security focussing on just the development and operational processes while necessary for things like catching OWASP Top 10 also needs to see the bigger picture otherwise, you could easily add additional needs that are already handled by controls elsewhere in the end-to-end business processes. That doesn’t mean to say security controls can5 be in software, but are they part o& improvement and pushing actions left vs. getting out of the starting blocks?
More reading
The book provides references, but for my own personal benefit, a number of particularly interesting and useful references are made, which may interest:
The Goal by Eliyahu M. Goldratt (a novel addressing his Theory of Constraints in the same way as The Phoenix Project is a novel around the DevOps handbook)
Christian Posta and Rinor Maloku’s book with Manning, Istio In Action has just been published. I’ve previously said it’s a good book, and that’s not surprising given Christian’s role at solo.io. When the final chapters became available I started to go through it in more detail and built a mind map (As with the recent review of Kubernetes best practices). The map can be seen below.
As you can see the map is very substantial reflecting on the depth and value of the book. For those who look at the maps, may notice there are a couple of chapters not fully mapped. I will update the map to fill those gaps in, but given they focus on monitoring and observability, I was less concerned about those areas given my own writing. The book’s exercises are very much built around using Docker Desktop making it very easy to spin up the examples and exercises. If you want to know about Istio Service Mesh on K8s then I’d recommend it.
Reading through the book, I’ve learned details that I was not entirely aware of, for example the integration of non K8s workloads into the mesh. The tuning of Istio to keep it highly performant with a lot of workloads.
I’ve had some time to catch up on books I’d like to read, including Kubernetes Best Practises in the last few weeks. While I think I have a fair handle on Kubernetes, the development of my understanding has been a bit ad-hoc as I’ve dug into different areas as I’ve needed to know more. This meant reading a Dummies/Introduction to entry style guide would, to an extent, likely prove to be a frustrating read. Given this, I went for the best practises book because if I don’t understand the practises, then there are gaps in my understanding still, and I can look at more foundation resources.
As it goes, this book was perfect. It quickly covered the basics of the different aspects of Kubernetes helping to give context to the more advanced aspects, and the best practices become almost a formulated summary in each section. The depth of coverage and detail is certainly very comprehensive, explaining the background of CNI (Container Network Interface) to network-level security within Kubernetes.
The book touched upon Service Meshes such as Istio and Linkerd2 but didn’t go into great depth, but again this is probably down to the fact that Service Mesh ideas are still maturing, and you have initiatives like SMI (Service Mesh Interface still in the CNCF’s sandbox).
In terms of best practices, that really stood out for me:
Use of Taints and Tolerations for refined control of pod deployment (Allowing affinity to be controlled to optimise resilience, or direct types of pod deployment to nodes with specialist capabilities such as GPU).
There are a lot more differences and options then you might realize in terms of ingress controller capabilities, so take time to identify what you may need from an ingress controller.
Don’t forget pods can be scaled vertically with the VPA (Vertical Pod Autoscaler)as well as horizontally through the HPA.
While using a managed persistence service will make statement storage a lot easier, stateful sets will give you a very portable solution.
As with a lot of technical books I read. As I go through the book I build up a mind map of what I think are the key points. Doing so leaves me with a resource I can use as a quick reference, but creating the mind map helps reinforce the learning. So here is the mind map …
I have been working my way through Building Evolutionary Architectures by Neal Forward, Rebecca Parsons and Patrick Kua. Three senior and respected members of Thoughtworks (also the home of Martin Fowler). Having read and listened to Neal and Rebecca’s presentations and writing I had expected a deeply thought-provoking read, but have to admit to being disappointed. There are some good points without a doubt, but the book pretty much focuses on one idea, the application of fitness functions. But I’m not convinced it warrants several hundred pages of a book as a result the point does at times feel laboured.
There are some arguments made, that leaves me thinking that there is a view that the only answer is microservices in the conventional model of Kubernetes, Docker etc, which I agree is a powerful paradigm to allow solutions to evolve, but it isn’t a silver bullet and not always right in every case (if you have a team lacking the underlying appreciation of the goals, or put in to place in an ad-hoc manner (see Chris Richardson‘s work) it isn’t going to help.
Alongside this, there is little said about the interface definition for microservices (typically APIs of one form or another). Whilst mention of leaky abstractions are made, the material illustrations such as code lead API definitions are omitted (risk being, code changes, the API changes and the impact cascades).
What surprised me the most is the on more than one occasion the books points to ERPs not being sufficiently customisable. Yet, anyone working with ERPs will tell you that ERPs are at their best when you use them to leverage industry best practices rather than crowbar them to fit unconventional ways of operating. If you’re a manufacturer, is fiscal reporting part of your differentiator; probably not, so why not take best practice OOTB.
As usual, I have mind mapped things as I read through the book. The dynamic/interactive version is here, the image (but not in full detail) is below.
I’ve been reading Chris Richardson’s new book Mixroservice Patterns published by Manning (here or here). Whilst I haven’t finished the book yet, I have read enough to feel I can provide worthwhile observation.
The book is supported by Chris’ website microservices.io which provides the patterns and related content in summarised form – great for a memory jogger and quick reference, but doesn’t make a substitute for the book.
When it comes to the book, Chris’ writing is extremly engaging whilst economic with its language – no long passages when a short sentence can convey everything necessary (unlike this one for example 🙂 ). For example, in three short paragraphs is an explination as to why there is a tendancy for IT people to point at particular technologies or techniques as silver bullets. As a result is incredibly informative and points to sources that inform the thinking – such references can be as diverse as Sam Newman’s Building Microservices to the (real) architect Christopher Alexander and Jonathan Haidt (The Righteous Mind).
The book is grounded in honest real world thinking being upfront and clearly pointing to when Microservices aren’t the right answer, to talking about the difficulties that can be expected in working with microservices. This won’t surprise anyone who has heard Chris speaking (here for example).
's Blog")













 I’ve been reading Chris Richardson’s new book Mixroservice Patterns published by Manning (
I’ve been reading Chris Richardson’s new book Mixroservice Patterns published by Manning (

You must be logged in to post a comment.