's Blog")
Tags
Apache, Apache Camel, Async API, Azarro, BPEL, business process orchestration language, GeoJSON, GraphQL, OAI, OAS, Open API, orchestration, Overlays, PolyAPI, SOAP, specifications, standards, Swagger, WS-BPEL
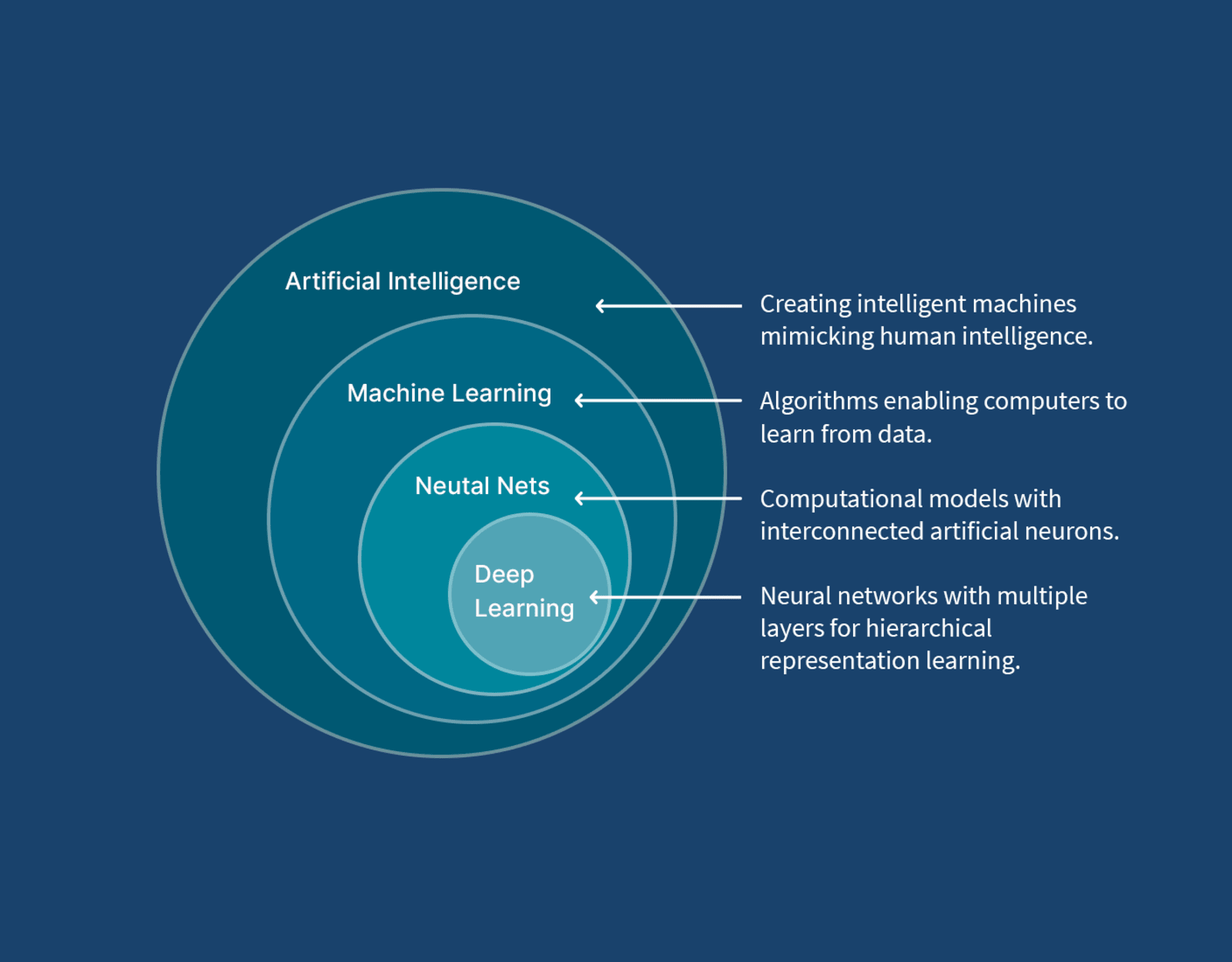
The OpenAPI Specification OAS and its Open API Initiative (OAI)—the governing body—have been around for 10 years, and of course, OAS’s foundation, Swagger, has been around a lot longer. OpenAPI is very much a mature proposition. But the OAI community hasn’t stood still. Two standards have been developed, the first being Overlays and the latter being Arazzo.
Overlays
Overlays support the Arazzo specification. So let’s start there. It is a simple specification that describes how an OpenAPI definition can be extended, particularly for providing additional information about the API. While we don’t strictly need such a specification, as the OpenAPI spec provides the means to incorporate additional information, it doesn’t say how to best use the extension points to support use cases such as elaborating on the application.
This means an organisation could use an overlay to describe how internally particular APIs from mainly 3rd party APIs or standards can or should best be used. For example, if we built an API using GeoJSON for passing data describing no-fly zones (sometimes called prohibited airspace), the zone’s shape is easily expressed as a polygon or circle. However, no-fly zones can often have ceilings or base altitudes (consider the use of airspace for military low-altitude air training, which shouldn’t impact airliners at cruising altitude). GeoJSON can support this by attaching attributes to the shapes. What GeoJSON doesn’t describe is the name of the additional attributes. We can document this attribute using the overlay without refining the GeoJSON specification.
Simply put, an Overlay describes a structured way to add detail to an API without changing the original specification. Hopefully, we’ll see tooling to take the overlay detail, merge that content into the original specification, and generate enhanced API documentation.
This presents some interesting possibilities. With the rise of AI, we could potentially use it to provide a structured explanation to an LLM that can then take the additional information to generate the code needed to build functionality using a selected API, which could then be reused when an API is updated. While asking an LLM to generate code will not guarantee the same result (the result of reranking, ongoing training, etc), it is unlikely things will drift radically. This means any breaking changes in the API should be more easily absorbed.
Arazzo
Arazzo, takes the ability to define overlays to APIs a step further, as it leverages the OpenAPI overlay concept to define workflows that can be used to show how APIs can be orchestrated. This is hardly a new idea. Before RESTful APIs became dominant, we saw various standards complementary to WSDL, such as WS-BPEL (bringing BPEL together with WSDL). After open source solutions, which may have closer alignment to languages such as Apache Camel, they also provide the means to define orchestration of APIs that can be used in a language-agnostic manner.
Unlike OAS and Overlays, this standard is not being presented a contract, which will always need a specific way of being written to minimize ambiguity as it is effectively a contract between two or more parties (we even see this in the way contracts are drawn up, from NDAs to T&Cs and Liability disclaimers). It is being presented as a means to be illustrative of API use, where ambiguity can be tolerated (by being stateless, we have to accept some ambiguity in how people will use APIs and eliminate ambiguity through contractual clarity.
While Arrazo’s structure and schema are much easier to work with than BPEL, particularly if you’re comfortable with AOS, as the schema has a similar style and weaves OAS specifications as first-class citizens. My concern is that BPEL, and the more domain-specific orchestration definitions, while adopted by some more prominent organisations in the search for standardisation and consistency, never had a profound impact; most organizations ended up extending, tailoring it, or using the notation as a means to apply effective configuration management. Only time will tell whether Arazzo will make a profound impact. There are certainly some headwinds for Arazzo to overcome. Consider these …
- The LLM domain is evolving so quickly that we aren’t too far away from mainstream tool vendors that have built or acquired companies like Poly API, which can document and integrate APIs using LLMs. We can also look at LangGraph’s work on developing AI agents’ ability to orchestrate tools such as APIs to solve complex problems. Remember that LangGraph was launched in January 2023, whereas the Arazzo committee was formed mid-2021.
- If we can’t reach a point where natural language will be sufficient to see APIs orchestrated in a predictable manner, is it possible to describe sufficient information using structured English (language)? PlantUML and Mermaid diagrams provide sufficient structured English to achieve the goal, which is less sensitive to things like positioning and white space, such as YAML.
Personal wish
While I applaud Overlays as they allow me to add qualification to an existing API (contract), I would be happier if the OAI worked to find a way for the core OAS syntax to bring OAS and Async API (very possible as Async API makes use of a similar schema structure) without needing the additional complexity of the orchestration concepts in Arazzo. The North Star ideal would be a means to weave GraphQL capabilities into the notation without complexity, although, to be honest, this is a lot further apart, maybe too far apart today.
Today, we must use more advanced (often commercial) tools that combine the notations in a single tool or multiple plugins sourced from different places. These tools are not aligned and don’t offer a seamless experience, e.g., defining JSON structures that could work across multiple APIs.










You must be logged in to post a comment.