's Blog")
Tags
Agentic AI, AI, APIs, artificial-intelligence, chatgpt, LLM, Oracle, SaaS, Technology
There’s a growing narrative that Agentic AI and “vibe coding” (AI-assisted development is probably a better term) signal the end of SaaS, what some are calling ‘SaaS-pocalyse‘, as reflected by share price drops with some SaaS vendors.
The reality is more nuanced. SaaS vendors are being pulled in multiple directions:
- Pressure to invest heavily in AI to accelerate productivity and efficiency
- Fear of disruption from AI-native startups
- Uncertainty over whether AI is a bubble
- Broader economic caution from customers, given the wider economic disruption
Net result: share prices have been dropping rapidly. But importantly, this doesn’t necessarily reflect a collapse in demand—particularly among larger vendors. As Jakob Nielsen has suggested, what we’re more likely to see is commodification (see here) not collapse.
Jakob also pointed out AI is really disrupting approaches to UX, both in how users might approach apps and how user experience is designed.
So what happens to SaaS?
There are a few things emerging I believe …
- Vendors incorporating AI into products as they drive to provide more clear value than vibe coding/home brewing your own solution. A route that Oracle have been taking with the Fusion SaaS products.
- Emphasis on mechanisms to make it easier for customers to add their differentiators to the core product.
- Some vendors are likely to retrench into pure data-platform thinking. But a lot of businesses don’t buy platforms (a platform buy is an act of faith that it can enable you to address a problem); many want to buy a solution to a problem, not a platform, and another 6 months of not knowing if there will be a fix.
So what does this mean for APIs?
Well, APIs are becoming ever more important, but in one of several ways:
Classic API value
Having good APIs with all the support resources will make it easier to bolt on customer differentiators, as a good API (not just well coded) from design to documentation, SDKs, etc., will mean that it will be easier for AI to vibe code, or to use it agentically through MCP, etc.
You’ll need the APIs even more, since they are the means by which you protect data, IP, and/or your data moat, as some have described it.
The other approach, if people retrench SaaS to a more Platform approach, is the risk of just exposing the underlying database. If you’ve worked with an organisation that has an old-school ERP (for example, E-Business Suite) where you’re allowed legitimate access to the schema, you will probably have seen one or more of the following problems:
- Unable to upgrade because the upgrade changes the underlying schema, which might break an extension
- There are so many extensions that trying to prove that nothing will be harmed by an upgrade is a monumental job of testing – not only on a functional level, but also performance etc. what we have also seen as once people are on this slippery slope, the fear to stop and change tack is too much, often too politically challenging, to hard to make the ROI case.
- Feature velocity on the solution slows down because the vendor has to be very careful to ensure changes are unlikely to break a deployment. Completely undermining the SaaS value proposition.

Bottom line, these issues all revolve around the fact that, because someone is using an application schema directly, there is an impediment to change (a few examples are here). As an aside, vendors like Oracle have long provided guidance on tailoring products such as CEMLIs.
There is an argument that some may make here, that making your extensions agentic will solve that, but there are flaws to that argument we’ll come back to.
APIs to ensure data replication
The alternative approach is to provide data replication, batches if you’re old school or streaming for those who want almost immediate data to match data states. In doing so, the SaaS solution now has the freedom (within certain limits) to change its data model. We just have to ensure we can continue to meet the replication contract. This is what Fusion Data Intelligence does, and internally, there are documents that Oracle Fusion applications must adhere to. While this documentation is not a conventional API, it has all the relevant characteristics.
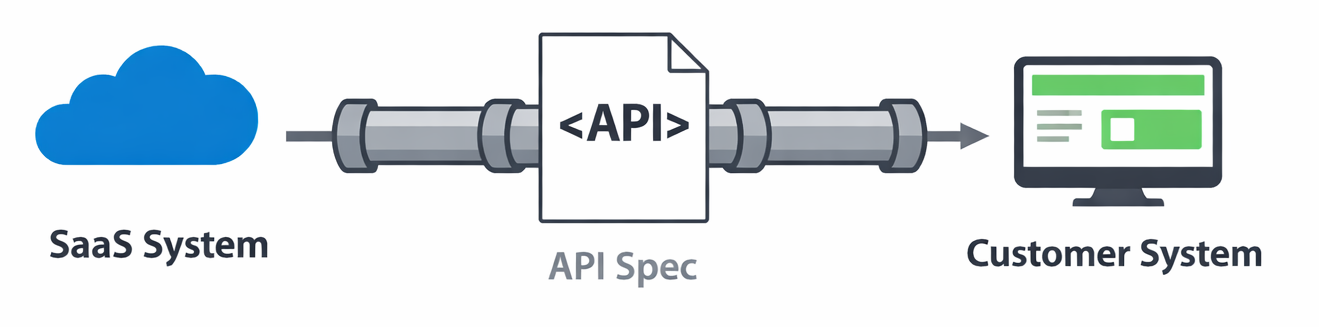
Using APIs for data replication doesn’t always register with people. Which is probably why, despite the popularity of technologies like Kafka, Asynchronous APIs don’t have the impact of the Open API Spec. But the transition of data from one structure to a structure that clients can access and depend upon, not to change, is still a contract.
In the world of Oracle, we would do this using a tool such as GoldenGate (Debezium is an example of an open-source product). Not only are we sharing the data, but we’re also not exposing data that might represent or illustrate how unique IP is achieved, or that is very volatile as a result of ongoing feature development.
There be dragons
Let’s step back for a moment and look at the big picture that is driving things. We want the use of AI and LLMs as they give us speed because we’re able to do things with a greater level of inherent flexibility and speed. That speed essentially comes from entrusting the LLM with the execution details, which means accepting non-determinism as the LLM may not apply the same sequence of steps every time the request is made. At the same time, any system (and particularly software) is only of help if it yields predictable in outcomes. We expect (and have been conditioned) to see consistency, if I give this input, I get this outcome – black box determinism if you like.
So, how can we achieve that deterministic black box? Let’s take a simplistic view of a real-world scenario. A hospital is our system, our deterministic behaviour expectations is sick and hurt people go in, and the system outputs healed and well people. Do we want to know how things work inside the black box? Beyond knowing the process is affordable, painless, caring and quick, then not really.
So how does a hospital do this? We invest heavily in training the tools (medical staff, etc.). We equip them with clearly understood, purposeful services (a theatre, patient monitors, and data on medications with clearly defined characteristics). The better the hospital understands how to use the services and data, the better the output. We can change how a hospital works, through its processes, training and equipment. Executed poorly, and we’ll see an uptick in problems
There is no escaping the fact that providing any API requires thought. Letting your code dictate the API can leave you boxed into a corner with a solution that can’t evolve, and even small changes to the API specification can break your API contract and harm people’s ability to consume it.
It is true that an LLM prompt can be tolerant of certain changes. But, it cuts both ways, poor API changes (e.g attributes and descriptions mismatching, attribute names are too obscure to extract meaning) can result in the LLM failing to interpret the intent from the provider side, or worse the LLM has been producing the expected results, but for unexpected reasons, as a result of small changes this may cause the LLM to start getting it wrong.
This leads to the question of what this means for application APIs? It’s an interesting question, and it’s easy to jump to the assumption that APIs aren’t needed. But, in that direction lie dragons, as the expression goes.
If we approach things from an API first strategy, the API and its definition are less susceptible to change, whether the API definition is implemented using an agent, vibe coded or traditionally developed, the contract will give us some of that determinism.
APIs further benefits
With the challenges and uncertainties mentioned in the world of SaaS, having good APIs can offer additional value, aside from the typical integration value, a good API Gateway setup, and if customers are vibe coding their own UIs from your APIs you’ll be able analyse patterns of usage which will still give some clues as to customer use cases, and which parts of the product are most valuable, just as good UI embedded analytics and trace data can reveal.
Final thought
If there is an existential threat to SaaS, it won’t be solved by abandoning structure. It will be addressed by:
- making data accessible
- enabling extension
- and doubling down on well-designed APIs
In an agentic world, APIs aren’t obsolete. They’re the thing that stops everything from falling apart.

You must be logged in to post a comment.