Updated reflecting changes discussed in blog post:
Making Scripts Work with IDCS Deployed PaaS
Oracle’s API Platform (API-P) product avoids the use of external configuration management. If you want to better understand why, then checkout our forthcoming book as it goes into detail about why this is the case (it can be pre-release version of the book can be obtained here). In a previous blog I wrote about and illustrated the use of the API-P’s own APIs so that it was possible to see what API iterations had been deployed to API Gateways.
In this blog I want to explore the issues of version management a bit further. API-P provides internal version management through the idea of iterations as previously explored (Understanding API Deployment State on API Platform). In addition to this there are API policy attributes called version, status etc. This information whilst having some impact on behaviour reflects the version of the ‘contract’ that the API represents between the consumer and provider, and requires a manual change.

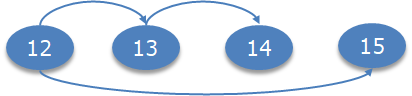
The API policies themselves are version tracked through the iteration identifiers. Each time a policy is saved the iteration is is incremented. What the API-P doesn’t support is the concept of branching. In relatively simple API Policy branching is unlikely to ever be an issue.
Why is a reversion capability needed?
Let’s take a more complex scenario. In our book API Platform we introduced the some APIs that would allow the retrieval of meta data about artists in the record companies’ catalog. It has however come to light that the API has been targeted with malicious calls, firstly through trying to attack using injection attacks and secondly trying to overload the back end by creating data requests that make the back-end work hard in retrieving data.
To defend against this, the API Policy has been enhanced to include some custom groovy policies to inspect the values provided. Strictly speaking following the principles of Semantic Versioning the API version should go from 1.0.0 to 1.0.1. However seeing that the ‘contract’ as presented to the consumer hasn’t really changed – the data models are the same, the URI goes unaltered resulting in the implementation team not changing the version.
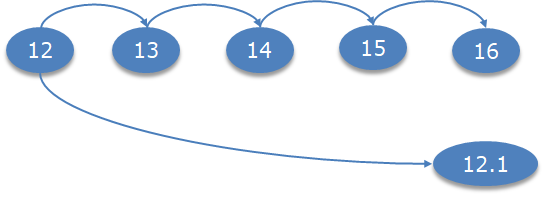
During development processes, it is not unusual to be developing existing logic, and decide that approach being used isn’t right or not going to perform as well. So you abandon your changes and revert back to the last approved version. However, this isn’t possible as any save will result in a new iteration. The API-P will be getting some enhanced version management features. But today to be able to undo the changes we need a means to ‘revert forward‘ (hence the tool name) that is to take an older iteration and make it the latest, as illustrated in the next diagram.

Today the API-P doesn’t provide a means to perform this process within the User interface. However when looking at a gateway you can review the API policy deployed. As we established previously that you may have different gateways deployed with different iterations. Given this, as API-P has been built true to the principles of separating the UI from the back-end through the use of APIs we can deduce there should be a means to get the details of an API with a specific iteration.
To this end we have built on the pattern previously illustrated to provide the means to ‘Revert Forward’ by creating a Groovy script that will use the APIs provided by API-P to retrieve an iteration and push it back at the latest version. When the policy is pushed back it also modifies the description to show which iteration has been pushed.
You may ask, why not use the conventional developer approach of branching as suggested in the following diagram. However API-P’s iteration framework doesn’t extend to support this.

The next with this is pretty predictable – how do I know which iteration to revert to. You have two options here, firstly either revert in order so you can see the prior version in turn – which whilst visually good, is not necessarily the most practical option. So in the tool we have a parameter that will allow you to display on the console the configuration of each iteration. This does mean you are going to see the policies in a JSON presentation. To make life easier we would recommend good practise and recording in the policy description information that helps determine the policy’s characteristics – and this can be used to better determine iteration behaviour.
If we are able to take an earlier iteration and make it the latest one by pushing it back then it is a short step to actually target a different management cloud in effect migrating the policies. Whilst possible it comes with some serious cautions …
- You risk undermining your version management, which management cloud has the master, and the iteration numbers will NOT migrate so it’s not like this info can be used to distinguish the laster version
- The logic included doesn’t accommodate handling differences in policy versions – so if trying move between instances of the API Platform they need to be the same version otherwise your configuration could make a mess of thing
- This issue is further compounded if you are deploying custom Java policies.
- Environment specific policies simply won’t work for example gateway based routing.
Oracle does not recommend that the policies be stored anywhere outside of the platform, whilst it this utility makes that a possibility, it deliberately avoids writing any of the information to the file, the policies only reside outside of the platform for the duration of the process execution.
The Tools Commands
All the parameters assume the values will not contain any space characters. Each command is preceded by a dash eg. revertForward.groovy -inpassword mypass -inSvr https://a.b.com
- -h or -help – provides this information
-inName – user name to access the source management cloud-inPass – password for the source management cloud-inSvr – The server address without any attributes e.g. https://1.2.3.4-policy – numeric identifier for the policy of interest-iter – iteration number of interest for the policy – optional-outName – optional, the target management cloud username, only needed for migrations-outPass – optional, the target management cloud password, only needed for migrations-outSvr – optional, the target management cloud server address – same formatting as inSvr, only needed for migrations-override – optional, if migrating to another management, tells the script to replace the existing policy of the same name if found-view – optional, separate command to allow viewing of the policy – requires one of the following values:
display – displays all the details of the policy, if no iteration is provided this will be the latest iterationsummary – provides the headline information of the policy including name, change date etcsummary-all – summarizes all the iterations from the current one back to the 1st
-debug – optional, will get script to report more information about what is happening
The code can be obtained from my GitHub repository here.
's Blog")
 I’ve started to subscribe to the APISecurity.io newsletter. The newsletter includes the analysis of recent API based security breaches along with other useful API related news. Some of the details of the breaches make for interesting reading and provide some good examples of what not to do. It is rather surprising how regularly the lack of the application of good practises is, including:
I’ve started to subscribe to the APISecurity.io newsletter. The newsletter includes the analysis of recent API based security breaches along with other useful API related news. Some of the details of the breaches make for interesting reading and provide some good examples of what not to do. It is rather surprising how regularly the lack of the application of good practises is, including: Ensuring the API has mitigation’s against the classic OWASP Top 10 – SQL Injection, poor authentication implementation.
Ensuring the API has mitigation’s against the classic OWASP Top 10 – SQL Injection, poor authentication implementation. When it comes to payload checks etc, products like Oracle’s API Platform make it easy to realise or provide out of the box checks for factors such as size limits, implementing payload checks, so better to use them.
When it comes to payload checks etc, products like Oracle’s API Platform make it easy to realise or provide out of the box checks for factors such as size limits, implementing payload checks, so better to use them.









You must be logged in to post a comment.