's Blog")
Tags
container, development, Docker, Kubernetes, OCIR, OKE, Oracle, registry, Technology
A container registry is as essential as a Kubernetes service as you want to manage the deployable resources. That registry could be the public Docker repository or something else. In most people’s cases, the registry needs to be private as you don’t want to expose your product assets to potential external tampering. As a result, we need a service such as Oracle’s container registry OCIR.
The re of this blog is going to walk through how to push a container you’ve built into OCIR and a gotcha that can trip up users if you make assumptions about how the registry works.
Build container
Let’s assume you’re building your microservices locally or retrieving vetting 3rd party services for use. In both cases, you want to manually push your assets into OCIR manually rather than have an automated build pipeline do it for you.
To make it easier to see what is happening, we can exploit some code from Oracle’s Github repo (such as this piece being developed) or you could use the classic hello world container (https://github.com/whotutorials/docker-busybox-hello-world/blob/master/Dockerfile). For the rest of the post, we’ll assume it is the code developed for the Oracle Architecture Center-provided code.
docker build -t event-data-svc .This creates a container locally, and we can see the container listed using the command:
docker images
Setup of OCIR
We need an OCIR to target so the easiest thing is to manually create an OCIR instance in one of the regions, for the sake of this illustration we’ll use Ashburn (short code is IAD). To help with the visibility we can put the registry in a separate compartment as a child of the root. Let’s assume we’re going to call the registry GraphQL. So before creating your OCIR set up the compartment as necessary.

In the screenshot, you can see I’ve created a registry, which is very quick and easy in the UI (in the menu it’s in the Developer Services section).


Finally, we click on the button to create the specific OCIR.
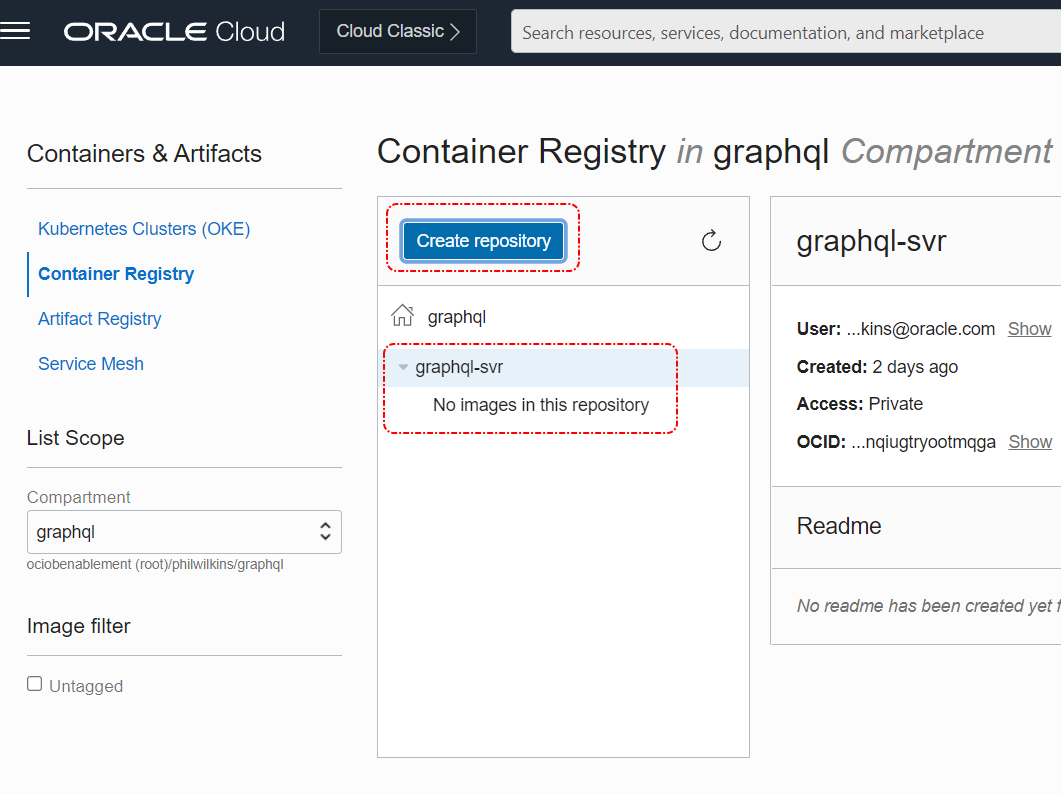
Deployment…
Having created the image, and with a repo ready we can start the steps of pushing the container to OCIR.
The next step is to tag the created image. This has to be done carefully as the tag needs to reflect where the image is going using the formula <region name>/<tenancy name/<registry name>:<version>. All the registries will be addressed by <region short code>.ocir.io In our case, it would be iad.ocir.io.
docker tag graph-svr:latest iad.ocir.io/ociobenablement/graphql-svr:v0.1-devAs you may have realized the tag being applied effectively tells OCI which instance of OCIR to place the container in. Getting this wrong can be the core of the gotcha previously mentioned and we’ll elaborate upon it shortly.
To sign in you’ll need an auth token as that is passed as the password. For simplicity, I’ve passed the token in the docker command, which Docker will warn you of as being insecure, and suggest it is passed in as part of a prompt. Note my token will have been changed by the time this is published. The username is built on the structure of <cloud tenancy name>/identitycloudservice/<username>. The identitycloudservice piece only needs to be included for your authentication is managed through IDCS, as is the case here. The final bit is the URI for the appropriate regional OCIR address, as we’ve used previously.
docker login -u ociobenablement/identitycloudservice/philip.wilkins@oracle.com -p XXXXXXXXXXX iad.ocir.ioWith hopefully a successful authentication response we can push the container. It is worth noting that the Docker authenticated connection will timeout which is why we’ve put everything in place before connecting. The push command is very simple, it is the tag name assigned to the artifact including the version number.
docker push iad.ocir.io/ociobenablement/graphql/graph-svr:v0.1-dev
Avoiding the gotcha
When we deal with repositories from Git to SVN or Apache Archiva to Nexus we work with a repository that holds multiple different assets with multiple versions of those assets. as a result, when we identify an asset uniquely we would expect to name things based on server/location, repository, asset name, and version. However, here each repository is designed for one type of asset but multiple versions. In reality, a Docker repository works in the same manner (but the extended path impact is different).
This means it becomes easy to accidentally define a tag with an extra element. Depending upon your OCI tenancy privileges if you get the path wrong, OCI creates a new root compartment container repository with a name that is a composite of the name elements after the tenancy and puts your artifact in that repository, not the one you expected.
We can address this in several ways, first and probably the best option is to automate the process of loading assets into OCIR, once the process is correct, it will remain correct. Another is to adopt a principle of never holding repositories at the root of a tenancy, which means you can then explicitly remove the permissions to create repositories in that compartment (you’ll need to explicitly grant the permissions elsewhere in the compartment hierarchy because of policy inheritance. This will result in the process of pushing a container to fail because of privileges if the tag is wrong.
Visual representation of structure differences


Condensed to a simple script
These steps can be condensed to a simple platform neutral script as follows:
docker build -t event-data-svc .
docker tag event-data-svc:latest iad.ocir.io/ociobenablement/event-data-svc:latest
docker login -u ociobenablement/identitycloudservice/philip.wilkins@oracle.com -p XXXXX iad.ocir.io
docker push iad.ocir.io/ociobenablement/event-data-svc:latestThis script would need modifying for each container being built, but you could easily make it parameterized or configuration drive.
A Note on Registry Standards
Oracle’s Container Registry has adopted the Open Registries standard for OCIR. Open Registries come under the Linux Foundation‘s governance. This standard has been adopted by all the major hyperscalers (Google, AWS, Azure, etc). All the technical spec information for the standard is published through GitHub rather than the main website.






You must be logged in to post a comment.