's Blog")
Tags
development, FluentBit, Grafana, Jaeger, logs, metrics, OpenSearch, Prometheus, Traces
In the Fluent Bit book I touch upon the point that we should be observing the observer. After all, if we don’t monitor our observability stack, then we’ll be operating blind and may never know until things go catastrophically wrong, and we’re getting complaints that production business solutions are down. One of the peer review comments was it would be really good to have a visual representation in the book. While I’d love to incorporate such diagrams, for them to be readable, they do use up a lot of space on the printed page, and very long chapters can also put some readers off. So, given the point wasn’t a key theme, we simply couldn’t incorporate the diagram.
But the suggestion is a good one. So we’ve created the visual representation here.
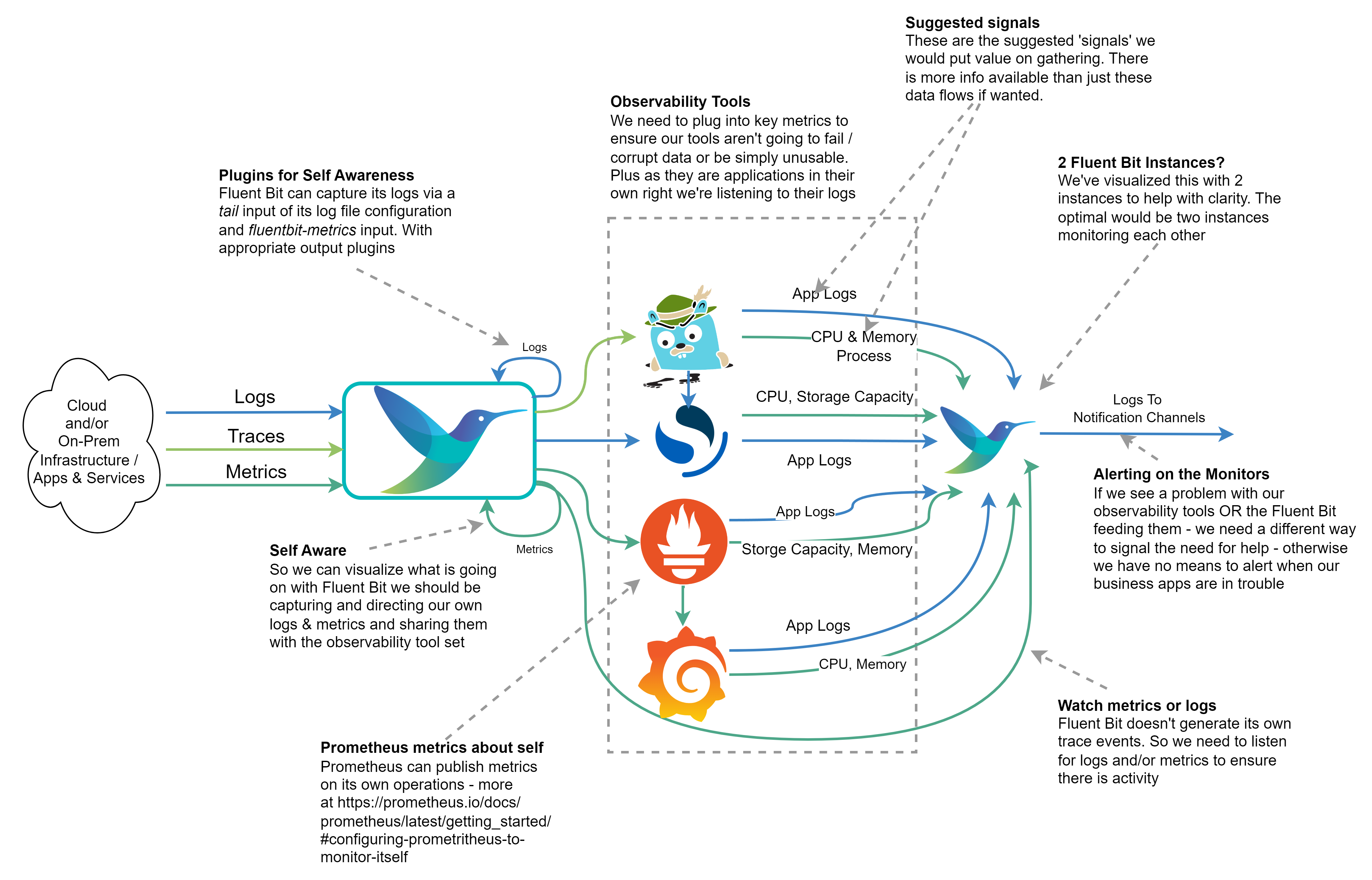
The diagram shows how we can monitor our observation tech stack so we don’t become ‘blind’ without knowing about it. The Outflow from the right of the diagram would send a signal to a notification service, which could be as simple as email or as user-friendly as Slack. We’ve indicated which kinds of metrics, logs, and traces could offer the most value from our observation tech stack.
If we’re running everything within a Kubernetes cluster, it would be easy to say we don’t need such a sophisticated setup as we can use Kubernetes liveness probes if the containers are well configured. While it is true if one of our services starts to fail, a liveness check should pick it up and recycle the container. But such probes only worry about the HTTP response code, not the cause. If we don’t monitor and capture more information we’ll never understand the problem. At worst we could end up seeing Kubernetes starting and then killing our containers in a vicious cycle and struggling to resolve the cause. So collecting the logs and metrics remains just as important.
How to Publish Fluent Bit Metrics and Logs
To publish Fluent Bit’s metrics to Prometheus, we need to configure the fluentbit-metrics input plugin (it does sound odd as an input, but there are reasons that become clearer in the book). We then route the output that supports using Fluent Bit as a Prometheus node exporter or makes use of the remote write API.
The log output for Fluent Bit can be configured via the command line or in the SERVICE blog (using the attributes log_file and log_level in the configuration file. Today this is setting the log threshold and identifying the log file. We can then, of course, configure a tail input plugin against the file if we want to send the logs to OpenSearch. We can also set plugin-specific logging thresholds as overrides to the Fluent Bit wide setting in the SERVICE block of configuration.
Configuring the other monitoring tools
- Grafana‘s configuration will allow it to publish Prometheus scrapable metrics and Traces that are OTLP compliant can be found documented here.
- Prometheus provides metrics on itself (details here) and logging controls as part of its command line and generates logfmt or JSON logs, details here.
- OpenSearch‘s logs can be accessed as documented here. The Logs are created with Log4j2, which means out of the box, it will be easy to parse them. Configuring the output of slow query reports does need to be switched on. OpenSearch also illustrates a pre OpenTelemetry/OpenMetrics approach to sharing internal metrics by writing them as logs. However, there are ways to convert such log events to OTLP Metrics with Fluent Bit.
- Jaeger provides metrics endpoints that are Prometheus-compatible, along with JSON-based logs, and are documented here. There is some support for tracing.


You must be logged in to post a comment.