Podcasts come out more frequently than we’d like sometimes, and in 2018, I blogged about some of the more interesting sources (here). Since then, we’ve discovered some new ones that we like and think are worth sharing. Most of the links are to the Podtails tracker website or Podbean, no hunting for the RSS feed. So, here we go …
Rockenteurs with Gary Kemp and Guy Pratt – Rockenteurs has built a tremendous following, its success comes from the fact they personally know have worked with (or revolve in similar circles) many of the guests. This produces an immediate familiarity and a sense you’re part of a casual group conversation and everyone is relaxed and unhurried. For those less in the know Gary Kemp was part of Spandau Ballet, but since those days has performed as guitarist for higher. Guy Pratt, while not such as house hold name, is a highly respected bassist, session musician and essentially Pink Floyd’s bassist since Roger Water’s departure.
Alan Cross gives two for the money with the Ongoing History of New Music and Uncharted crime and mayhem in the music industry – Alan Cross is a Canadian music journalist, radio presenter and pod and videocaster. His primary output is the Ongoing History of New Music, which focusses on the Indie / Rock scene. But he has a second fortnightly podcast with a wider perspective. What really works here, is the depth of his knowledge, and the love of his subject (desire to see musicians do well and share the stories behind and around the music).
Bureau of Lost Culture – I came to Stephen Coates’ podcast as a result of hearing about Bone Music and reading his book, by that title. Stephen’s podcasts tend to gravitate to all aspects of music, but his focus is ‘count culture’. The subjects can look a little academic, but the way the stories are told is very human centered and explorers the impacts his subjects have had.
BBC provides a vast library of podcasts, some are regular, some are more episodic, but all are worth checking out …
This Cultural Life – Best described as a successor to Mastertapes, as the presenter, John Wilson, has moved on to this show. Although the podcast goes beyond music to a broader cultural portfolio of guests/subjects.
Eras – A more mainstream look at big-name artists such as Sting, Abba, Kylie with 4-6 episodes per artist in an episodic release.
Legend – A bit like Eras, but covers artists like Joni Mitchell and Springsteen.
Artist own podcasts can be a bit hit a miss, but these have some great episodes …
Moby Pod – Moby’s self deprecation, and history has resulted in some fascinating podcasts, both looking at music broadly (and personally) as he is as much an interviewee as interviewer on these podcasts. His name and reputation has meant he has also had some more influential names on the podcast, but these tend to be aligned with his animal rights and vegan passions. But these aren’t presented in a preaching manner, as is Moby’s way he recognizes these are his beliefs and not everyone may agree.
Norah Jones is Playing Along – This has been an interesting podcast as Norah talks with a musician and records material with them. After the 1st season (we saw some of those recordings released as an album). There has been a cvouple of years gap between the the first series and the second once started recently (Octob ’25).
James Lavelle (Living In My Headphones) aka Unkle – A monthly slot on Soho Radio, this is very much a DJ mix session, but the diversity of music used is fascinating.
Broken Record – Part of Malcolm Gladwell’s growing Pushkin empire of podcasts. These can be a bit hit and miss, but when they hit – the insightful, interesting and enjoyable to listen to, and among the best there is.
So when you’re not dialed in with your latest vinyl/CD/download I’d recommend checking these out.
MCP (Model Context Protocol) has really taken off as a way to amplify the power of AI, providing tools for utilising data to supplement what a foundation model has already been trained on, and so on.
With the rapid uptake of a standard and technology that has been development/implementation led aspects of governance and security can take time to catch up. While the use of credentials with tools and how they propagate is well covered, there are other attack vectors to consider. On the surface, it may seem superficial until you start looking more closely. A recent paper Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions highlights this well, and I thought (even if for my own benefit) to explain some of the vectors.
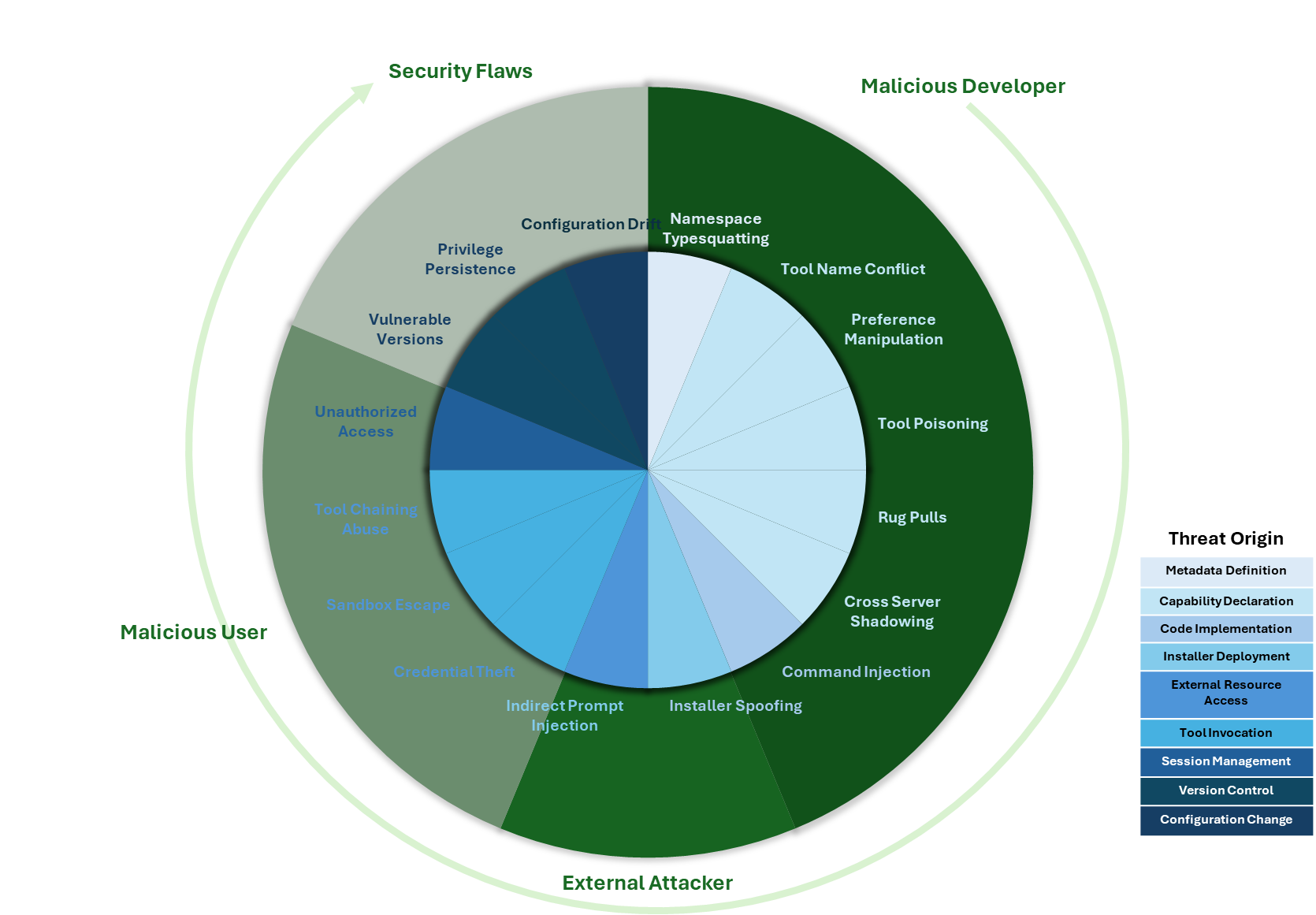
I’ve also created a visual representation based on the paper of the vectors described.
The inner ring represents each threat, with its color denoting the likely origin of the threat. The outer ring groups threats into four categories, reflecting where in the lifecycle of an MCP solution the threat could originate.
I won’t go through all the vectors in detail, though I’ve summarized them below (the paper provides much more detail on each vector). But let’s take a look at one or two to highlight the unusual nature of some of the issues, where the threat in some respects is a hybrid of potential attack vectors we’ve seen elsewhere. It will be easy to view some of the vectors as fairly superficial until you start walking through the consequences of the attack, at which point things look a lot more insidious.
Several of the vectors can be characterised as forms of spoofing, such as namespace typosquatting, where a malicious tool is registered on a portal of MCP services, appearing to be a genuine service — for example, banking.com and bankin.com. Part of the problem here is that there are a number of MCP registries/markets, but the governance they have and use to mitigate abuse varies, and as this report points out, those with stronger governance tend to have smaller numbers of services registered. This isn’t a new problem; we have seen it before with other types of repositories (PyPI, npm, etc.). The difference here is that the attacker could install malicious logic, but also implement identity theft, where a spoofed service mimics the real service’s need for credentials. As the UI is likely to be primarily textual, it is far easier to deceive (compared to, say, a website, where the layout is adrift or we inspect URIs for graphics that might give clues to something being wrong). A similar vector is Tool Name Conflict, where the tool metadata provided makes it difficult for the LLM to distinguish the correct tool from a spoofed one, leading the LLM to trust the spoof rather than the user.
Another vector, which looks a little like search engine gaming (additional text is hidden in web pages to help websites improve their search rankings), is Preference Manipulation Attacks, where the tool description can include additional details to prompt the LLM to select one solution over another.
The last aspect of MCP attacks I wanted to touch upon is that, as an MCP tool can provide prompts or LLM workflows, it is possible for the tool to co-opt other utilities or tools to action the malicious operations. For example, an MCP-provided prompt or tool could ask the LLM to use an approved FTP tool to transfer a file, such as a secure token, to a legitimate service, such as Microsoft OneDrive, but rather than an approved account, it is using a different one for that task. While the MCP spec says that such external connectivity actions should have the tool request approval, if we see a request coming from something we trust, it is very typical for people to just say okay without looking too closely.
Even with these few illustrations, tooling interaction with an LLM comes with deceptive risks, partially because we are asking the LLM to work on our behalf, but we have not yet trained LLMs to reason about whether an action’s intent is in the user’s best interests. Furthermore, we need to educate users on the risks and telltale signs of malicious use.
Attack Vector Summary
The following list provides a brief summary of the attack vectors. The original paper examines each in greater depth, illustrating many of the vectors and describing possible mitigation strategies. While many technical things can be done. One of the most valuable things is to help potential users understand the risks, use that to guide which MCP solutions are used, and watch for signs that things aren’t as they should be.
Now that details of the product I’ve been involved with for the last 18 months or so are starting to reach the public domain (such as the recent announcement at the UN General Assembly on September 25), I can talk to a bit about what we’ve been doing. Oracle’s Digital Government Global Industry Unit has been working on a solution that can help governments address the questions of food security.
Food security exists when people have access to enough safe and nutritious food for normal growth and development, and an active and healthy life. By contrast, food insecurity refers to when the aforementioned conditions don’t exist. Chronic food insecurity is when a person is unable to consume enough food over an extended period to maintain a normal, active and healthy life. Acute food insecurity is any type that threatens people’s lives or livelihoods.
By referencing the World Food Programme, it would be easy to interpret this as a 3rd world problem. But in reality, it applies to just about every nation. We can see this, with the effect the war in Ukraine has had on crops like Wheat, as reported by organizations such as CGIAR, European Council, and World Development journal. But global commodities aren’t the only driver for every nation to consider food security. Other factors such as Food Miles (an issue that perhaps has been less attention over the last few years) and national farming economics (a subject that comes up if you want to it through a humour filter with Clarkson’s Farm to dry UK government reports and US Department of Agriculture.
Looking at it from another perspective, some countries will have a notable segment of their export revenue coming from the production of certain crops. We know this from simple anecdotes like ‘for all the tea in China’, coffee variants are often referred to by their country of origin (Kenyan, Columbian etc.). For example, Palm Oil is the fourth-largest economic contributor in Malaysia (here).
So, how is Oracle helping countries?
One of the key means of managing food security is understanding food production and measuring the factors that can impact it (both positively and negatively), which range from the obvious—like weather (and its relationship to soil, water management, etc.) —to what crop is being planted and when. All of which can then be overlayed with government policies for land management and farming subsidies (paying farmers to help them diversify crops, periodically allowing fields to go fallow, or subsidizing the cost of fertilizer).
Oracle is a technology company capable of delivering systems that can operate at scale. Technology and the recent progress in using AI to help solve problems are not new to agriculture; in fact, several trailblazing organizations in this space run on Oracle’s Cloud (OCI), such as Agriscout. Before people start assuming that this is another story of a large cloud provider eating their customers’ lunch, far from it, many of these companies operate at the farm or farm cooperative level, often collecting data through aerial imagery from drones and aircraft, along with ground-based sensors. Some companies will also leverage satellite imagery for localized areas to complement these other sources. This is where Oracle starts to differentiate itself – by taking high-resolution imagery (think about the resolution level needed to differentiate Wheat and Maize, or spot rice and carrots, differentiate an orchard from a natural copse of trees). To get an idea, look at Google Earth and try to identify which crops are growing.
We take the satellite multi-spectral images from each ‘satellite over flight’ and break it down, working out what the land is being used for (ruling out roads, tracks, buildings, and other land usage). To put the effort to do this into context, the UK is 24,437,600,000 square meters and is only 78th in the list of countries by area (here). It’s this level of scale that makes it impractical to use more localized data sources (imagine how many people and the number of drones needed to fly over every possible field in a country, even at a monthly frequency).
This only solves the 1st step of the problem, which is to tell us the total crop growing area. It doesn’t tell us whether the crop will actually grow well and produce a good yield. For this, you’re going to need to know about weather (current, forecast, and historic trends), soil chemical composition and structure, and information such as elevation, angle, etc. Combined with an understanding of optimal crop growing needs (water levels, sun light duration, atmospheric moisture, soil types and health) – good crops can be ruined by it simply being too wet to harvest them, or store them dryly. All these factors need to be taken into account for each ‘cell’ we’re detecting, so we can calculate with any degree of confidence what can be produced.
If this isn’t hard enough, we need to account for the fact that some crops may have several growing seasons per year, or succession planting is used, where Carrots may be grown between March and June, followed by Cucumbers through to August, and so on.
Using technology
Hopefully, you can see there are tens of millions of data points being processed every day, and Oracle’s data products can handle that. As a cloud vendor, we’re able to provide the computing scale and, importantly, elasticity, so we can crunch the numbers quickly enough that users benefit from the revised numbers and can work out mitigation actions to communicate to farmers. As mentioned, this could be planning where to best use fertilizer or publishing advice on when to plant which crops for optimal growing conditions. In the worst cases recognizing there is going to be a national shortage of a staple crop and start purchasing crops from elsewhere and ensure when the crops arrive in ports they get moved out to the markets (like all large operations – as we saw with the Covid crises – if you need to react quickly, more mistakes can be made, costs grow massively driven by demand).
I mentioned AI, if you have more than the most superficial awareness of AI, you will probably be wondering how we use it, and the problems of AI hallucination – the last thing you want is a being asked to evaluate something and hallucinating (injecting data/facts that are not based on the data you have collected) to create a projection. At worst, this would mean providing an indication that everything is going well, when things are about to really go wrong. So, first, most of the AI discussed today is generative, and that is where we see issues like hallucinations. We’re have and are adopting this aspect of AI where it fits best, such as explainability and informing visualization, but Oracle is making heavy use of the more traditional ideas of AI in the form of Machine Learning and Deep Learning which are best suited to heavy numerical computational uses, that is not to say there aren’t challenges to be ddressed with training the AI.
Conclusion
When it comes to Oracle’s expertise in the specialized domains of agriculture and government, Oracle has a strong record of working with governments and government agencies from its inception. But we’ve also worked closely with the Tony Blair Institute for Global Change, which works with many national government agencies, including the agriculture sector.
My role in this has been as an architect, focused primarily on applying integration techniques (enabling scaling and operational resilience, data ingestion, and how our architecture can work as we work with more and more data sources) and on applying AI (in the generative domain). We’re fortunate to be working alongside two other architects who cover other aspects of the product, such as infrastructure needs and the presentation tier. In addition, there is a specialist data science team with more PhDs and related awards than I can count.
Oracle’s Digital Government business is more than just this agriculture use case; we’ve identified other use cases that can benefit from the data and its volume being handled here. This is in addition to bringing versions of its better-known products, such as ERP, Healthcare (digital health records management, vaccine programmes, etc.), national Energy and Water (metering, infrastructure management, etc).
Fluent Bit version 4’s first major release dropped a couple of weeks ago (September 24, 2025). The release’s feature list isn’t as large as 4.0.4 (see my blog here). It would therefore be easy to interpret the change as less profound. But that isn’t the case. There are some new features, which we’ll come to shortly, but there are some significant improvements under the hood.
Under the hood
Fluent Bit v4.1 has introduced significant enhancements to its processing capabilities, particularly in the handling of JSON. This is really important as handling JSON is central to Fluent Bit. As many systems are handling JSON, there is at the lowest levels, continuous work happening in different libraries to make it as fast as possible. Fluent Bit has amended its processing to use a mechanism based on a yyjson, without going into the deep technical details. If you examine the benchmarking of yyjson and other comparable libraries, you’ll see that its throughput is astonishing. So accelerating processing by even a couple of percentage points can have a profound performance enhancement.
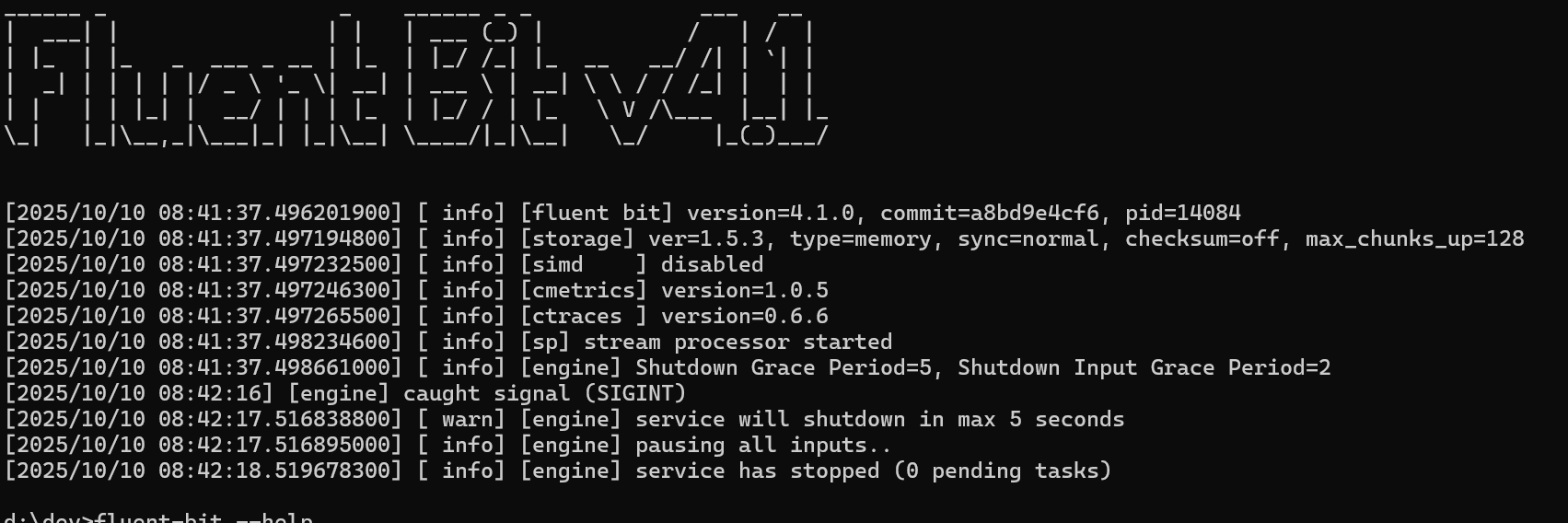
The next improvement in this area is the use of SIMD (Single Instruction, Multiple Data). This is all about how our code can exploit microprocessor architecture to achieve faster processing. As logs often need characters like new line, quotes, and other special characters encoding, and logs often carry these characters (and we tend to overlook this – consider a stack trace, where each step of the stack chain is provided on a new line, or embedding a stringified XML or JSON block in the log, which will hve multiple uses of quotes etc. As a result, any optimization of string encoding will quickly yield performance benefits. As SIMD takes advantage of CPU characteristics, not every build will have the feature. You can check to see if SIMD is being used by checking the output during startup, like tthis:
This build for Windows x86-64 as shown in the 3rd info statement doesn’t have SIMD enabled.
Other backend improvements have been made with TLS handling. The ability to collect GPU metrics with AMD hardware (significant as GPUs are becoming ever more critical not only in large AI arrays, but also for AI at the edge).
So, how do we as app developers benefit?
If Fluent Bit’s performance improves, we benefit from reduced risk of backpressure-related issues. We can either complete more work with the same compute (assuming we’re at maximum demand all the time), or we can reduce our footprint – saving money either as capital expenditure (capex) or operational expenditure (opex) (not something that most developers are typically seeking until systems are operating at hyperscale). Alternatively, we can further utilize Fluent Bit to make our operational life easier, for example, by reducing sampling slightly, implementing additional filtering/payload load logic, and streaming to detect scenarios as they occur rather than bulk processing on a downstream platform.
Functional Features
In terms of functionality, which as a developer we’re very interested in as it can make our day job easier, we have a few features.
AWS
In terms of features, there are a number of enhancements to support AWS services. This isn’t unusual; as the AWS team appears to have a very active and team of contributors for their plugins. Here the improvement is for supporting Parquet files in S3.
Supervisory Process
As our systems go ever faster, and become more complex, particularly when distributed it becomes harder to observe and intervene if a process appears to fail or worse becomes unresponsive. As a result, we need tools to have some ‘self awareness’. Fluen bit introduces the idea of an optional supervisor process. This is a small, relatively simple process that spawns the core of Fluent Bit and has the means to check the process and act as necessary. To enable the supervisor , we can add to the command line –supervisor. This feature is not available on all platforms, and the logic should report back to you during startup if you can’t use the feature. Unfortunately, the build I’m trying doesn’t appear to have the supervisor correctly wired in (it returns an error message saying it doesn’t recognize the command-line parameter).
If you want to see in detail what the supervisor is doing – you can find its core in /src/flb_supervisor.c with the supervisor_supervise_loop function, specifically.
Conclusion
With the number of differently built and configured systems, we’ll see a 4.1.x releases as these edge case gremlins are found and resolved.
When it comes to REST-based web APIs, I’ve long been an advocate of the work of Arnaud Lauret (better known as the API Handyman) and his book The Design of Web APIs. I have, with Arnaud’s blessing, utilized some of his web resources to help illustrate key points when presenting at conferences and to customers on effective API design. I’m not the only one who thinks highly of Arnaut’s content; other leading authorities, such as Kin Lane (API Evangelist), have also expressed the same sentiment. The news that a 2nd Edition of the book has recently been published is excellent. Given that the 1st edition was translated into multiple languages, it is fair to presume this edition will see the same treatment (as well as having the audio treatment).
Why 2nd Edition?
So, why a second edition, and what makes it good news? While the foundational ideas of REST remain the same, the standard used to describe and bootstrap development has evolved to address practices and offer a more comprehensive view of REST APIs. Understanding the Open API specification in its latest form also helps with working with the Asynchronous API specifications, as there is a significant amount of harmony between these standards in many respects.
The new edition also tackles a raft of new considerations as the industry has matured, from the use of tooling to lint and help consistency as our catalogue of APIs grows, to be able to use linting tools, we need guidelines on how to use the specification, and what we might want to make uniform nd ensure the divergence is addressed. Then there are the questions about how to integrate my API support / fit into an enriched set of documents and resources, such as those often offered by a developer portal.
However, the book isn’t simply a guide to Open API; the chapters delve into the process of API design itself, including what to expose and how to expose it. How to make the APIs consistent, so that a developer understanding one endpoint can apply that understanding to others. For me, the book shows some great visual tools for linking use cases, resources, endpoint definitions, and operations. Then, an area that is often overlooked is the considerations under the Non-Functional Requirements heading, such as those that ensure an API is performant/responsive, secure, supports compatibility (avoiding or managing breaking changes), and clear about how it will respond in ‘unhappy paths’. Not to mention, as we expand our API offerings, the specification content can become substantial, so helping to plot a way through this is excellent.
Think You Know API Design
There will be some who will think, ‘Hey, I understand the OpenAPI Specification; I don’t need a book to teach me how to design my APIs.’ To those, I challenge you to reconsider and take a look at the book. The spec shows you how to convey your API. The spec won’t guarantee a good API. The importance of good APIs grows from an external perspective – it’s a way to differentiate your service from others. When there is competition, and if your API is complex to work with, developers will fight to avoid using it. Not only that, in a world where AI utilizes protocols like MCP, having a well-designed, well-documented API increases the likelihood of an LLM being able to reason and make calls to it.
Conclusion
If there is anything to find fault with – and I’m trying hard, is it would be it would have been nice if it expanded its coverage a little further to Asynchronous APIs (there is a lot of Kafka and related tech out there which could benefit from good AsyncAPI material) and perhaps venture further into how we can make it easier to achieve natural language to API (NL2API) for use cases like working with MCP (and potentially with A2A).
AI, specifically Generative AI, has been dominating IT for a couple of years now. If you’re a software vendor with services that interact with users, you’ll probably have been considering how to ensure you’re not left behind, or perhaps even how to use AI to differentiate yourself. The answer to this can be light-touch AI to make the existing application a little easier to use (smarter help documentation, auto formatting, and spelling for large text fields). Then, at the other end of the spectrum, is how do we make AI central to our application? This can be pretty radical. Both ends of the spectrum carry risks – light touch use can be seen as ‘AI whitewashing’ – adding something cosmetic so you can add AI enablement to the product marketing. At the other end of the spectrum, rejecting chunks of traditional menus and form-based UI that allow users in a couple of quick clicks or keystrokes to access or create content can result in increasing the product cost (AI consumes more compute cycles, thereby incurring a cost along the way) for at best a limited gain.
While AI whitewashing is harmful and can impact a brand image, at least the features can be ignored by the user. However, the latter requires a significant investment and can easily lead to the perception that he product isn’t as capable as it could/should be.
At the heart of this are a couple of basic considerations that UX design has identified for a long time:
For a user to get the most out of a solution, they need a mental model of the capabilities your product can provide and the data it has. These mental models come from visual hints – those hints come from menus, right-click operations, and other visual clues. UI specialists don’t do eye tracking studies just for the research grant money.
UI best practices provide simple guidance stating that there should be at least three ways to use an application, supporting novice users, the average user, and the power user. We can see this in straightforward things, such as multiple locations for everyday tasks (right-click menus, main menu, ribbon with buttons), not to mention keyboard shortcuts. Think I’m over-stating things? I see very knowledgeable, technically adept users still type and then navigate to the menu ribbon to embolden text (rather than simply use the near-universal Ctrl+B). Next time you’re on a Zoom/Teams call, working with someone on a document, just watch how people are using the tools. On the other end of the spectrum, some tools allow us to configure accelerator key combinations to specific tasks, so power users can complete actions very quickly.
Users are impatient – the technology industry has prided itself on making things quicker, faster, more responsive (we see this with Moore’s law with computer chips to mobile networks … Edge, 3G … 5G (and 6G in development). So if things drop out of those norms, there is an exponential chance of the user abandoning an action (or worse, trying to make it happen again, multiplying the workload). AI is computationally expensive, so by its nature, it is slower.
Switching input devices incurs a time cost when transitioning between devices, such as a keyboard and mouse. Over the years, numerous studies have been conducted on this topic, identifying ways to reduce or eliminate such costs. Therefore, we should minimize such switching. Simple measures, such as being able to table through UI widgets, can help achieve this.
User tolerance to latency has been an ongoing challenge – we’re impatient creatures. There are well-researched guidelines on this topic, and if you take a moment to examine some of the techniques available in UI, particularly web UIs, you will see that they reflect this. For example, prefetching content, particularly images, rendering content as it is received, and infinite scrolling.
All of this could be interpreted as being anti-AI, and even as someone wanting to protect jobs by advocating that we continue the old way. Far from it, AI can really help, and I have been a long-standing advocate of the idea that AI could significantly simplify tasks such as report generation in products that rely heavily on structured data capture. Why, well, using structured form capture processes will help with a mental model of the data held, the relationships, and the terminology in the system, enabling us to formulate queries more effectively.
The point is, we should empower users to use different modes to achieve their goals. In the early days of web search, the search engines supported the paradigm of navigating using cataloguing of websites. Only as the understanding of search truly became a social norm did we see those means to search disappear from Yahoo and Google because the mental models of using search engines established themselves. But even now, if you look, those older models of searching/navigating still exist. Look at Amazon, particularly for books, which still offers navigation to find books by classification. This isn’t because Amazon’s site is aging, anything but. It is a recognition that to maximize sales, you need to support as many ways of achieving a goal as are practical.
Navigation categories for historical books, demonstrating various time periods and regions – Amazon.
If there is a call to arms here, it is this – we should complement traditional UX with AI, not try to replace it. When we look at an AI-driven interaction, we use it to enable users to solve problems faster, solve problems that can’t be easily expressed with existing interactions and paradigms. For example, replacing traditional reporting tools that require an understanding of relational databases or reducing/removing the need to understand how data is distributed across systems.
Some of the better uses of AI as part of UX are subtle – for example, the use of Grammarly, Google’s introduction to search looks a lot like an oversized search result. But we can, and should consider the use of AI, not just as a different way to drive change into traditional UX, but to open up other interaction models – enabling their use in new ways, for example rather than watching or reading how to do something, we can use AI to translate to audio, and talk us through a task as we complete it. For example, a mechanical engineering task requires both hands to work with the necessary tools. Burt is also using different interaction models to help overcome disabilities.
Don’t take my word for it; here are some useful resources:
Back in 2018, Manning published Chris Richardson‘s Microservices Patterns book. In many respects, this book is the microservices version of the famous Gang of Four patterns book. The exciting news is that Chris is working on a second edition.
One key difference between the GoF book and this is that engaging with patterns like Inversion of Control, Factories, and so on isn’t impacted by considerations around architecture, organization, and culture.
While the foundational ideas of microservices are established, the techniques for designing and deploying have continued to evolve and mature. If you follow Chris through social media, you’ll know he has, in the years since the book’s first edition, worked with numerous organisations, training and helping them engage effectively with microservices. As a result, a lot of processes and techniques that Chris has identified and developed with customers are grounded in real practical experience.
As the book is in its early access phase (MEAP), not all chapters are available yet, so plenty to look forward to.
So even if you have the 1st edition and work with microservice patterns, the updates will, I think, offer insights that could pay dividends.
If you’re starting your software career or considering the adoption of microservices (and Chris will tell you it isn’t always the right answer), I highly recommend getting a copy, as with the 1st edition, the 2nd will become a must-read book.
So, there is a new book title published with me as the author (Logging Best Practices) published by Manning, and yes, the core content has been written by me. But was I involved with the book? Sadly, not. So what has happened?
Background
To introduce the book, I need to share some background. A tech author’s relationship with their publisher can be a little odd and potentially challenging (the editors are looking at the commerciality – what will ensure people will consider your book, as well as readability; as an author, you’re looking at what you think is important from a technical practitioner).
It is becoming increasingly common for software vendors to sponsor books. Book sponsorship involves the sponsor’s name on the cover and the option to give away ebook copies of the book for a period of time, typically during the development phase, and for 6-12 months afterwards.
This, of course, comes with a price tag for the sponsor and guarantees the publisher an immediate return. Of course, there is a gamble for the publisher as you’re risking possible sales revenue against an upfront guaranteed fee. However, for a title that isn’t guaranteed to be a best seller, as it focuses on a more specialized area, a sponsor is effectively taking the majority investment risk from the publisher (yes, the publisher still has some risk, but it is a lot smaller).
When I started on the Fluent Bit book (Logs and Telemetry), I introduced friends at Calyptia to Manning, and they struck a deal. Subsequently, Calyptia was acquired by Chronosphere (Chronosphere acquires Calyptia), so they inherited the sponsorship. An agreement I had no issue with, as I’ve written before, I write as it is a means to share what I know with the broader community. It meant my advance would be immediately settled (the advance, which comes pretty late in the process, is a payment that the publisher recovers by keeping the author’s share of a book sale).
The new book…
How does this relate to the new book? Well, the sponsorship of Logs and Telemetry is coming to an end. As a result, it appears that the commercial marketing relationship between Chronosphere and Manning has reached an agreement. Unfortunately, in this case, the agreement over publishing content wasn’t shared with the author or me, or the commissioning editor at Manning I have worked with. So we had no input on the content, who would contribute a foreword (usually someone the author knows).
Manning is allowed to do this; it is the most extreme application of the agreement with me as an author. But that isn’t the issue. The disappointing aspect is the lack of communication – discovering a new title while looking at the Chronosphere website (and then on Manning’s own website) and having to contact the commissioning editor to clarify the situation isn’t ideal.
Reading between the lines (and possibly coming to 2 + 2 = 5), Chronosphere’s new log management product launch, and presumably being interested in sponsoring content that ties in. My first book with Manning (Logging in Action), which focused on Fluentd, includes chapters on logging best practices and using logging frameworks. As a result, a decision was made to combine chapters from both books to create the new title.
Had we been in the loop during the discussion, we could have looked at tweaking the content to make it more cohesive and perhaps incorporated some new content – a missed opportunity.
If you already have the Logging in Action and Logs and Telemetry titles, then you already have all the material in Logging Best Practices. While the book is on the Manning site, if you follow the link or search for it, you’ll see it isn’t available. Today, the only way to get a copy is to go to Chronosphere and give them your details. Of course, suppose you only have one of the books. In that case, I’d recommend considering buying the other one (yes, I’ll get a small single-digit percentage of the money you spend), but more importantly, you’ll have details relating to the entire Fluent ecosystem, and plenty of insights that will help even if you’re currently only focused on one of the Fluent tools.
Going forward
While I’m disappointed by how this played out, it doesn’t mean I won’t work with Manning again. But we’ll probably approach things a little differently. At the end of the day, the relationship with Manning extends beyond commercial marketing.
Manning has a tremendous group of authors, and aside from writing, the relationship allows me to see new titles in development.
Working with the development team is an enriching experience.
It is a brand with a recognized quality.
The social/online marketing team(s) are great to interact with – not just to help with my book, but with opportunities to help other authors.
As to another book, if there was an ask or need for an update on the original books, we’d certainly consider it. If we identify an area that warrants a book and I possess the necessary knowledge to write it, then maybe. However, I tend to focus on more specialized domains, so the books won’t be best-selling titles. It is this sort of content that is most at risk of being disrupted by AI, and things like vibe coding will have the most significant impact, making it the riskiest area for publishers. Oh, and this has to be worked around the day job and family.
The latest release of Fluent Bit is only considered a patch release (based on SemVer naming). But given the enhancements included it would be reasonable to have called it a minor change. There are some really good enhancements here.
Character Encoding
As all mainstream programming languages have syntaxes that lend themselves to English or Western-based languages, it is easy to forget that a lot of the global population use languages that don’t have this heritage, and therefore can’t be encoded using UTF-8. For example, according to the World Factbook, 13.8% speak Mandarin Chinese. While this doesn’t immediately translate into written communication or language use with computers, it is a clear indicator that when logging, we need to support log files that can be encoded to support idiomatic languages, such as Simplified Chinese, and recognized extensions, such as GSK and BIG5. However, internally, Fluent Bit transmits the payload as JSON, so the encoding needs to be handled. This means log file ingestion with the Tail plugin ideally needs to support such encodings. To achieve this, the plugin features a native character encoding engine that can be directed using a new attribute called generic. encoding, which is used to specify the encoding the file is using.
The Win**** encodings are Windows-based formats that predate the adoption of UTF-8 by Microsoft.
Log Rotation handling
The Tail plugin, has also seen another improvement. Working with remote file mounts has been challenging, as it is necessary to ensure that file rotation is properly recognized. To improve the file rotation recognition, Fluent Bit has been modified to take full advantage of fstat. From a configuration perspective, we’ll not see any changes, but from the viewpoint of handling edge cases the plugin is far more robust.
Lua scripting for OpenTelemetry
In my opinion, the Lua plugin has been an underappreciated filter. It provides the means to create customized filtering and transformers with minimal overhead and effort. Until now, Lua has been limited in its ability to interact with OpenTelemetry payloads. This has been rectified by introducing a new callback signature with an additional parameter, which allows access to the OLTP attributes, enabling examination and, if necessary, return of a modified set. The new signature does not invalidate existing Lua scripts with the older three or four parameters. So backward compatibility is retained.
The most challenging aspect of using Lua scripts with OpenTelemetry is understanding the attribute values. Given this, let’s just see an example of the updated Lua callback. We’ll explore this feature further in future blogs.
function cb(tag, ts, group, metadata, record)
if group['resource']['attributes']['service.name'] then
record['service_name'] = group['resource']['attributes']['service.name']
end
if metadata['otlp']['severity_number'] == 9 then
metadata['otlp']['severity_number'] = 13
metadata['otlp']['severity_text'] = 'WARN'
end
return 1, ts, metadata, record
end
Other enhancements
With nearly every release of Fluent Bit, you can find plugin enhancements to improve performance (e.g., OpenTelemetry) or leverage the latest platform enhancements, such as AWS services.
Just about any web-based application will have cookies, even if they are being used as part of session management. Then, if you’re in the business-to-consumer space, you’ll likely use tracking cookies to help understand your users.
Understanding what is required depends on which part of the world your application is being used in. For the European Union (EU) and the broader European Economic Area (EEA), this is easy as all the countries have ratified the GDPR and several related laws like the ePrivacy Directive.
For North America (USA and Canada), the issue is a bit more complex as it is a network of federal and state/province law. But the strictest state legislation, such as California, aligns closely with European demands, so as a rule of thumb, meet EU legislation, and you should be in pretty good shape in North America (from a non-lawyer’s perspective).
The problem is that the EEA accounts for 30 countries (see here), plus the USA and Canada, and we have 32 of the UN’s recognized 195 states (note there is a difference between UN membership and UN recognition). So, how do we understand what the rules are for the remaining 163 countries?
I’m fortunate to work for a large multinational company with a legal team that provides guidelines for us to follow. However, I obviously can’t share that information or use it personally. Not to mention, I was a little curious to see how hard it is to get a picture of the global landscape and its needs.
It turns out that getting a picture of things is a lot harder than I’d expected. I’d assumed that finding aggregated guidance would be easy (after all, there are great sites like DLA Piper’s and the UN Trade & Development that cover the more general data protection law). But, far from it. I can only attribute this to the fact that there is a strong business in managing cookie consents.
The resources that I did find, which looked comprehensive on the subject:
's Blog")







You must be logged in to post a comment.