JMESPath is a mature syntax for traversing and manipulating JSON objects. The syntax is also supported with multiple language implementations available through GitHub (and other implementations exist). As a result, it has been very widely adopted; just a few examples include:
Azure CLI
AWS CLI and Lambda
Oracle Cloud WAF
Splunk
As the syntax is very flexible and recursive in its use following the documented notation can be a little tricky to start with. So following the syntax can be rather tricky. The complete definition runs to 97 lines, of which 32 lines focus on the syntactical structure. The others describe the base types such as numbers, characters, accepted escaped characters, and so on. Nothing wrong with this, as the exhaustive definition is necessary to build parsers. But for the majority of the time it is those 32 lines that we need to understand.
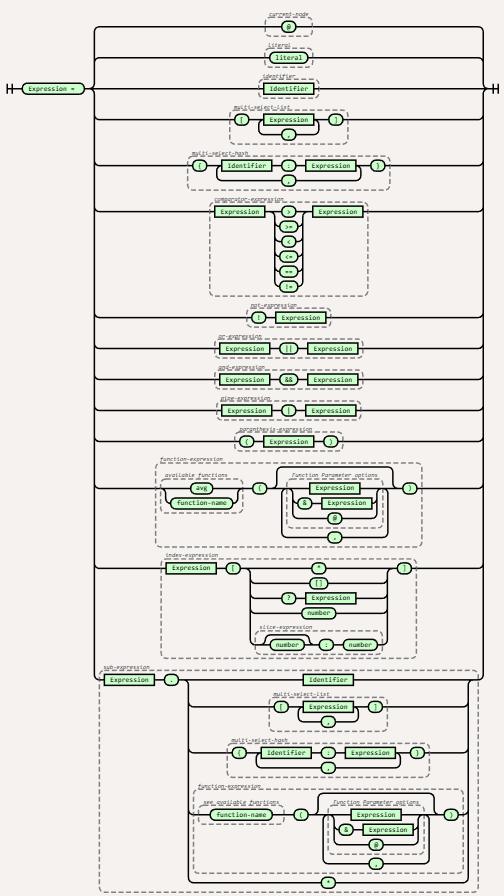
As the expression goes – ‘a picture says a thousand words’, there might not be a thousand words, but there is enough to suggest a visual representation will help. Even if the visual only helps us traverse the use of the detailed syntax. So we’ve use our favoured visual representation – the railroad diagram and the tool produced by Tab Akins to create the representation. We’ve put the code and created images for the syntax in my GitHub repository here, continuing the pattern previously adopted.
Here is the resulting diagram …
To make it easy to trace back to the original syntax document we’ve included groupings on the diagram that have names from the original speciofication.
Parts of the diagram make the expressions look rather simple, but you’ll note that it is possible for the sections to be iterative which allows for the expression to traverse a JSON object of undefined depth. But what can be really challenging is that an in many areas it is possible to nest expressions within expressions. Visually there is no simple way to represent the expression possibilities of this in a linear manner. Other than be clear about where the nesting can take place.
Those who have been using my Logging in Action book will know that to help test the configuration of monitoring tools including Fluentd we have built a LogGenerator that can very easily play and replay logging events into a variety of destinations and formats. all written in Groovy to make the utility easy to run as a script and extend without needing to set up a proper Java development environment.
With the number of different destinations built into the script and the logic to load the source log events and format them the utility is getting rather large for a single file. Rather than letting it continue to grow as we add more destinations to pump log events too, I’ve extended the implementation so you can point to a Groovy file that implements the logic to send the log events. It only requires three simple methods to be implemented.
To demonstrate the feature we have created a custom extension and fully documented it. The extension allows you to send log events to the OCI Logging service. This includes an optional crude aggregation mechanism as sending individual log events is a little inefficient over REST. By doing this we can send synthetic or playback logs as if we’re an application in real-life to ensure that any alerting or routing for the logging works properly before we get anywhere production and do not need to run the application and induce error events.
Beyond this, we’re also thinking about creating a plugin to fire log events at Prometheus so we can send events using the Prometheus pushgateway. As a result, we can tune Prometheus’ configuration.
More improvements – refactoring the existing code
We will refactor the existing code to use the same approach which should make the code more maintainable, but the changes won’t stop the utility from working as it always has (so we won’t break out the existing output channels from the core).
We have also started to improve the code commenting – so hopefully it will make the code a bit more navigable.
The 12 Factor App definition is now ten years old. In the world of software that is a long time. So perhaps it’s time to revisit and review what it says. As I have spent a lot of time around Logging – I’ve focussed on Factor 11 – Logging.
I have been fortunate enough to present at the hybrid JAX London conference on this subject. It was great to get out and see people at a conference rather than just with a screen and a chat console of online-only events.
One of the areas I present publicly is the use of Fluentd. including the use of distributed and multiple nodes. As many events have been virtual it has been easy to demo everything from my desktop – everything is set up so I can demo things very easily. While doing this all on one machine does point to how compact and efficient Fluentd is as I can run multiple instances concurrently it does undermine distributed capabilities somewhat.
Add to that I now work for Oracle it makes sense to use OCI resources. With that, I have been developing the scripts to configure Ubuntu VMs to set up the demo environments installing Ruby, Fluentd, and various gems needed and pulling the relevant configurations in. All the assets can be found in the GitHub repository https://github.com/mp3monster/logging-demos. The repository readme includes plenty of information as well.
While I’ve been putting this together using OCI, the fact that everything is based on Ubuntu should mean it can be run locally on VMs, WSL2, and adaptable for MacOS as well. The environment has been configured means you can still run on Ubuntu with a single node if desired.
Additional Log Destinations
As the demo will typically be run on OCI we can not only run the demo with a multinode setup, we have extended the setup with several inclusion files so we can utilize OCI services OpenSearch and OCI Log Analytics. If you don’t want to use these services simply replace the contents of several inclusion files including files with the contents of the dummy_inclusion.conf file provided.
Representation of the Demo setup
The configuration works by each destination having one or two inclusion files. The files with the postfix of label-inclusion.conf contains the configuration to direct traffic to the respective service with a configuration that will push log events at a very high frequency to the destination. The second inclusion file injects the duplication of log events to each service. The inclusion declarations in the main node Fluentd config file references an environment variable that should provide the path to the inclusion file to use. As a result, by changing the environment variable to point to a dummy file it becomes possible o configure out the use of one of the services. The two inclusions mean we can keep the store declarations compact and show multiple labels being used. With the OpenSearch setup, we have a variant of the inclusion file model where the route inclusion can reference the logic that we would use in the label directly within the sore declaration.
The best way to see the use of the inclusions is to experiment with setting the different environment variables to reference the different files and then using the Fluentd dry-run feature (more on this in the book).
Setup script
The setup script performs a number of tasks including:
Pulling from Git all the resources needed in terms of configuration files and folders
Retrieving the necessary plugins against the possibility of their use.
Setting up the various environment variables for:
Slack token
environment variables to reference inclusion files
shortcut environment variables and aliases
network (IP) address for external services such as OpenSearch
Setting up a folder for OCI tokens needed.
Setting up temp folders to be used by OCI Plugins as a file-based cache.
Feeding the log analytics service is a more complex process to set up as the feeds need to have metadata about the events being ingested. The downside is the configuration effort is greater, but the payback is that it becomes easier to extract meaningful information quickly because the service has a greater understanding of the content. For example, attributing the logs to a type of source means the predefined or default log formats are immediately understood, and maximum meaning can be retrieved from the log event.
Going to OCI Log Analytics does cut out the need for the Connections hub, which would allow rules and routing to be defined to different OCI services which functionally can help such as directing log events to PagerDuty.
When building Node solutions, even if you’re not going to publish the code to a public repository you’re likely to be using package.json to declare the dependencies for your app. Doing this makes it easier to build and deploy a utility. But if you’re conversant with several languages there is a tendency to just adapt your existing skills to work with others. The downside of this is small tooling nuances can catch you off guard and consume time while figuring them out. The workings of packages with NPM (as shown below) is one possible case.
If you create the package.json using npm init to create the initial version of the file, it is fairly common to set values to default. In the case of the license, this is an ISC license. This is easily forgotten. The problem here is twofold:
Does the license set reflect the constraints of the dependencies and their licenses
Does the default license reflect the position you want?
Looking at the latter point first, This is important as organizations have matured (and tooling greatly improved) when it comes to understanding how open source licensing can impact. This is particularly important for any organizations leveraging open source as part of their revenue generating activities either ‘as a service’ but also selling software solutions. If you put the wrong license here the license checking tools often protecting code repositories may reject your code, even in internal only use cases (yes this tripped me up).
To help overcome this issue you can install a tool that will analyze the dependencies and optionally their dependencies and report back on your license exposure. This tool is called license-report. Once installed (npm install -g license-report) we just need to point the tool to the package.json file. e.g. license-report package.json. We can make the results a lot more consumable by outputting the content in a number of formats. For example a simple text value:
From this, you could set your license declaration in package.json or validate that your preferred license won’t conflict,
I’ve designed a variety of GraphQL schemas and developed microservice backends. But not done much with configuring the Apollo implementation of a GraphQL server until recently. This may reflect the fact my understanding of JavaScript doesn’t extend into the world of Node.JS as much as I’d like (the problem with being a multi-language developer is you’re likely to find your way around many languages but never be a master of one). Anyway, the following content is about the implementation within a GraphQL server part of a solution. It may be these pointers are just for my benefit you might find them helpful as well.
To make it easy to reference the code, we’ve added entries (n) into the code, where n is a number. This is not part of the code. But there to make the different lines referenceable. Where code should go but is not relevant to the point being made I’ve added ellipsis (…)
Dynamic loading and server configuration
import { ApolloServer } from 'apollo-server';
import { loadFilesSync } from '@graphql-tools/load-files';
import { resolvers } from './resolvers.js'; (1)
import ProviderInternalAPI from './ProviderInternalAPI.js'; (1)
import EventsInternalAPI from './EventsInternalAPI.js'; (1)
const server = new ApolloServer({
debug : true, (2)
typeDefs: loadFilesSync('./schema.graphql'), (3)
resolvers,
dataSources: () => {
return {
eventsInternalAPI: new EventsInternalAPI(), (4)
providerInternalAPI: new ProviderInternalAPI() (4)
pro
};
}});
There is the potential to dynamically load the resolvers rather than importing each JavaScript file as we see on lines (1). The mechanics to do this is documented here. It would be cool if an opinionated implementation was provided. As shown by (3) we can take a independent schema file being loaded. The Apollo example approach for this didn’t seem to work for us, although both approaches make use of graphql-tools in a synchronous manner.
We can switch on debugging (2) for the GraphQL server, although the level of information published doesn’t appear to be significant. Ideally this setting is changed for production.
Defining the resolvers
The prefix for each resolver (1) must correlate to the name in the schema of the mutator or query (not the type as you would expect with Java). Often we don’t need all the parameters for the resolver. The documentation describes replacing each unused parameter with one or more underscores (i.e _, __ ). The underscore denoting the field not in use. However we can satisfy the indication of not being used, but keep the meaning of each position by using the underscore then a name (i.e. _parent, _args ) as shown in (2).
By taking the response into a variable (3) we can optionally log it. Trying to return using invocation line would result in the handler object rather than the payload itself. By taking the result into a variable we can log the content if desired and return the content.
The use of the backward quote is a node feature. It allows us to incorporate variables into a string by referencing it within ${}(4).
We need to supply the GraphQL server with instances with a layer of code that will interact with the resolvers. We can instantiate the instances in the declaration. The naming of the object is important (4) to the resolver.js (declarations).
import { useLogger } from "@graphql-yoga/node";
...
latestEvent (1): async (_parent, _args, { dataSources }, _info) (2) => {
if (log) { console.log("resolvers - get latest event"); }
let responseValue = await dataSources.eventsInternalAPI.getLatestEvent(); (3)
if (log) { console.log(`(4) Resolver response for latest event:\n ${responseValue}`); }
return responseValue;
},
To handle the use of resolvers within a larger resolver we need to declare the resolution outside of the Query and Mutator blocks (but inside the whole declaration block)(1). The name provided needs to match the parent entity that the query resolver contributes to.
To then provide values from the outer resolution we need to prover to the chained resolution use the naming as represented in the GraphQL schema as shown by (2). The GraphQL engine will resolve the mapping values.
Web resolver URL
// GET
async getProvider(code) {
console.log("getProvider (%s) directing to %s",code,this.baseURL);
return this.get(`provider?code=${code} (1)`);
}
The URL parameters need to be appended to the base URL path for the parent class to use in the invocation as shown by (1). The Apollo examples showed a setter option but we didn’t see the URI being addressed properly. This approach produces the relevant requirement.
When configuring Fluentd we often need to provide credentials to access event sources, targets, and associated services such as notification tools like Slack and PagerDuty. The challenge is that we don’t want the credentials to be in clear text in the Fluentd configuration.
Using Env Vars
In the Logging In Action with Fluentd book, we illustrated how we can take the sensitive values from environment variables so the values don’t show up in the configuration file. But, we’ve seen regularly the question of how secure is this, can’t the environment variable be seen by everyone on that machine?
The answer to this question comes down to having a deeper understanding of how environment variables work. There is a really good explanation here. The long and short of it is that environment variables can only be seen by the process that creates the variable and any child process will receive a copy of the parent’s variables.
This means that if we create the variable in a shell, only that shell and any processes launched by that shell can see the environment variable. So as long as we don’t set variables up as part of a system-level configuration then we already have a level of security. So we could wrap the start of Fluentd with a script that sets the environment variables needed. Then everything launches that script.
In a previous blog (here) I wrote about the structure and naming of assets to be applied to OCIR. What I didn’t address is the interesting challenge of what if my development machine has a different architecture to my target environment. For example, as a developer, I have a nice shiny Mac Book Pro with the M1 chipset which uses an ARM architecture. However, my target cloud environment has been built and runs with an AMD64 chipset? As we’re creating binary images it does raise some interesting questions.
As we’re creating our containers with Docker, this addresses how to solve the problem with Docker. Other OCI Compliant containers will address the problem differently.
Buildx
Buildx is a development feature in Docker which makes use of a cross-platform build capability. When using buildx we can specify one or more build platform types. These are specified using the –platform parameter. In the code below we use it to define the Linux AMD64 architecture mentioned (linux/amd64). But we can make the parameter a comma-separated list targeting different platform types. When that is done, multiple images will be built. By default, the build will happen in sequence, but it is possible to switch on additional process threads for the Docker build process to get the build process running concurrently.
Unlike the following example (which is only intended for one platform, if you are building for multiple platforms then it would be recommended that the name include the platform type the image will work for. For production builds we would promote that idea regardless, just as we see with installer and package manager-related artifacts.
If you compare this version of the code to the previous blog (here) there are some additional differences. Now I’ve switched to setting the target tag as part of the build. As we’re not interested in hanging onto any images built we’ve included the target repository in the build statement. Immediately push it to OCIR, after all the images won’t work on our machine.
Oracle’s product portfolio is significant, from databases (obviously) to GraalVM to a cloud platform capable of competing with GCP, AWS, and Azure. This means locating the Oracle-provided plugins, or community ones can get messy. Depending on your perspective Oracle Developer Plugins could relate to Java and GraalVM or Oracle Database.
As broad as the portfolio, is the Oracle details regarding the plugins. So the following two tables represent what we’ve identified as Oracle-provided tooling, and the second table of plugins we’ve used when working on Oracle-based solutions from the community.
Name / Plugin Search
Description / Additional Details
Related resource links
search:Oracle Labs This will return all the Oracle plugins related to GraalVM
SuiteCloud Extension for Visual Studio Code is part of the SuiteCloud Software Development Kit (SuiteCloud SDK), a set of tools to customize your NetSuite accounts.
Github actions is a means by which actions like commits to github trigger external infrastructure to perform actions such as creating application binaries.
's Blog")






You must be logged in to post a comment.