When configuring Fluentd we often need to provide credentials to access event sources, targets, and associated services such as notification tools like Slack and PagerDuty. The challenge is that we don’t want the credentials to be in clear text in the Fluentd configuration.
Using Env Vars
In the Logging In Action with Fluentd book, we illustrated how we can take the sensitive values from environment variables so the values don’t show up in the configuration file. But, we’ve seen regularly the question of how secure is this, can’t the environment variable be seen by everyone on that machine?
The answer to this question comes down to having a deeper understanding of how environment variables work. There is a really good explanation here. The long and short of it is that environment variables can only be seen by the process that creates the variable and any child process will receive a copy of the parent’s variables.
This means that if we create the variable in a shell, only that shell and any processes launched by that shell can see the environment variable. So as long as we don’t set variables up as part of a system-level configuration then we already have a level of security. So we could wrap the start of Fluentd with a script that sets the environment variables needed. Then everything launches that script.
The following isn’t unique to OCIR, as it will hold true for any K8s Deployment YAML configuration that works with an Open Container Initiative compliant registry. To define the containers part of the YAML file we need to provide an attribute that can be used to confirm the legitimacy of the request. To do this we need to supply a token. However, we don’t want this token to be visible in plain sight in our YAML. The solution to this is to set up a secret within Kubernetes.
In the following YAML extract, we can see the secret is named.
This does mean we need to create the secret. As this is a one-off task the easiest step is to create the secret by hand. To do that we use the command:
This naturally leads to the next question where do we get the secret?
This step is straightforward. Navigating using the user icon top right (highlighted in the screenshot below), select the User Settings option to get to the screen shown below. Then use the right-hand menu option highlight (Auth Tokens). This displays a section of the UI showing your current auth tokens and provides a button that will popup a window to guide you through creating a new auth token.
In a previous blog (here) I wrote about the structure and naming of assets to be applied to OCIR. What I didn’t address is the interesting challenge of what if my development machine has a different architecture to my target environment. For example, as a developer, I have a nice shiny Mac Book Pro with the M1 chipset which uses an ARM architecture. However, my target cloud environment has been built and runs with an AMD64 chipset? As we’re creating binary images it does raise some interesting questions.
As we’re creating our containers with Docker, this addresses how to solve the problem with Docker. Other OCI Compliant containers will address the problem differently.
Buildx
Buildx is a development feature in Docker which makes use of a cross-platform build capability. When using buildx we can specify one or more build platform types. These are specified using the –platform parameter. In the code below we use it to define the Linux AMD64 architecture mentioned (linux/amd64). But we can make the parameter a comma-separated list targeting different platform types. When that is done, multiple images will be built. By default, the build will happen in sequence, but it is possible to switch on additional process threads for the Docker build process to get the build process running concurrently.
Unlike the following example (which is only intended for one platform, if you are building for multiple platforms then it would be recommended that the name include the platform type the image will work for. For production builds we would promote that idea regardless, just as we see with installer and package manager-related artifacts.
If you compare this version of the code to the previous blog (here) there are some additional differences. Now I’ve switched to setting the target tag as part of the build. As we’re not interested in hanging onto any images built we’ve included the target repository in the build statement. Immediately push it to OCIR, after all the images won’t work on our machine.
A container registry is as essential as a Kubernetes service as you want to manage the deployable resources. That registry could be the public Docker repository or something else. In most people’s cases, the registry needs to be private as you don’t want to expose your product assets to potential external tampering. As a result, we need a service such as Oracle’s container registry OCIR.
The re of this blog is going to walk through how to push a container you’ve built into OCIR and a gotcha that can trip up users if you make assumptions about how the registry works.
Build container
Let’s assume you’re building your microservices locally or retrieving vetting 3rd party services for use. In both cases, you want to manually push your assets into OCIR manually rather than have an automated build pipeline do it for you.
This creates a container locally, and we can see the container listed using the command:
docker images
Setup of OCIR
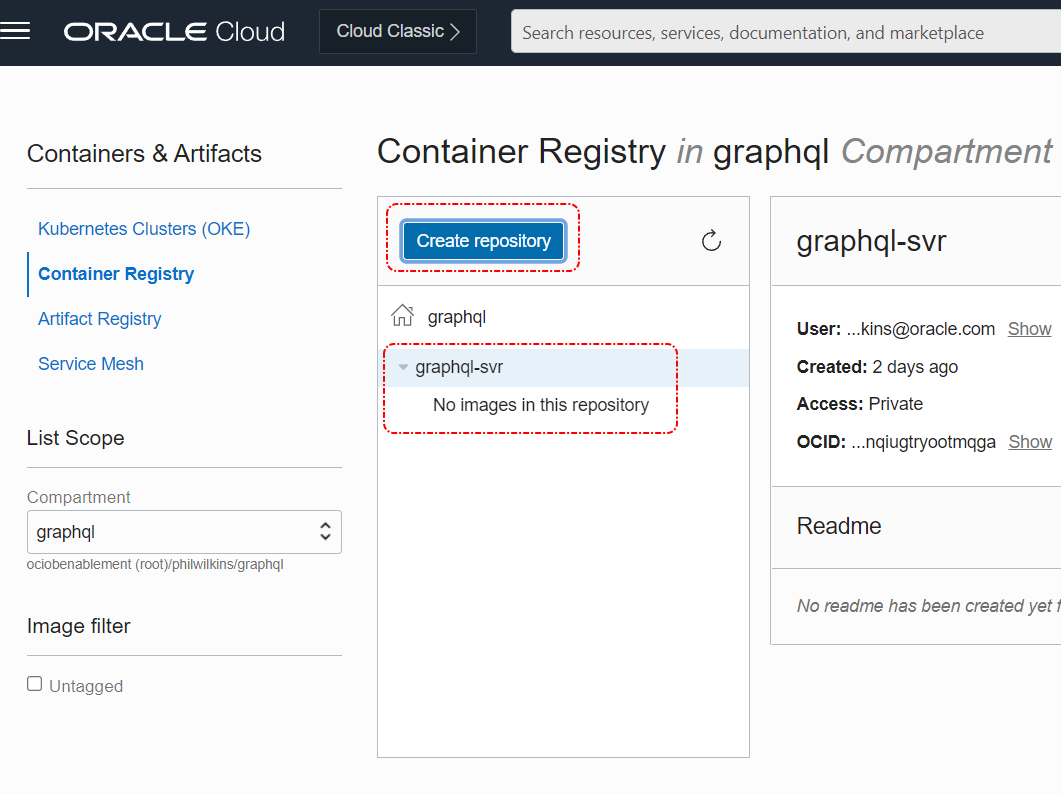
We need an OCIR to target so the easiest thing is to manually create an OCIR instance in one of the regions, for the sake of this illustration we’ll use Ashburn (short code is IAD). To help with the visibility we can put the registry in a separate compartment as a child of the root. Let’s assume we’re going to call the registry GraphQL. So before creating your OCIR set up the compartment as necessary.
fragment of the compartment hierarchy
In the screenshot, you can see I’ve created a registry, which is very quick and easy in the UI (in the menu it’s in the Developer Services section).
The Oracle meu to navigate to the OCIR servicethe UI to create a OCIR
Finally, we click on the button to create the specific OCIR.
Deployment…
Having created the image, and with a repo ready we can start the steps of pushing the container to OCIR.
The next step is to tag the created image. This has to be done carefully as the tag needs to reflect where the image is going using the formula <region name>/<tenancy name/<registry name>:<version>. All the registries will be addressed by <region short code>.ocir.io In our case, it would be iad.ocir.io.
docker tag graph-svr:latest iad.ocir.io/ociobenablement/graphql-svr:v0.1-dev
As you may have realized the tag being applied effectively tells OCI which instance of OCIR to place the container in. Getting this wrong can be the core of the gotcha previously mentioned and we’ll elaborate upon it shortly.
To sign in you’ll need an auth token as that is passed as the password. For simplicity, I’ve passed the token in the docker command, which Docker will warn you of as being insecure, and suggest it is passed in as part of a prompt. Note my token will have been changed by the time this is published. The username is built on the structure of <cloud tenancy name>/identitycloudservice/<username>. The identitycloudservice piece only needs to be included for your authentication is managed through IDCS, as is the case here. The final bit is the URI for the appropriate regional OCIR address, as we’ve used previously.
With hopefully a successful authentication response we can push the container. It is worth noting that the Docker authenticated connection will timeout which is why we’ve put everything in place before connecting. The push command is very simple, it is the tag name assigned to the artifact including the version number.
When we deal with repositories from Git to SVN or Apache Archiva to Nexus we work with a repository that holds multiple different assets with multiple versions of those assets. as a result, when we identify an asset uniquely we would expect to name things based on server/location, repository, asset name, and version. However, here each repository is designed for one type of asset but multiple versions. In reality, a Docker repository works in the same manner (but the extended path impact is different).
This means it becomes easy to accidentally define a tag with an extra element. Depending upon your OCI tenancy privileges if you get the path wrong, OCI creates a new root compartment container repository with a name that is a composite of the name elements after the tenancy and puts your artifact in that repository, not the one you expected.
We can address this in several ways, first and probably the best option is to automate the process of loading assets into OCIR, once the process is correct, it will remain correct. Another is to adopt a principle of never holding repositories at the root of a tenancy, which means you can then explicitly remove the permissions to create repositories in that compartment (you’ll need to explicitly grant the permissions elsewhere in the compartment hierarchy because of policy inheritance. This will result in the process of pushing a container to fail because of privileges if the tag is wrong.
Visual representation of structure differences
Repository Structure
Registry Structure
Condensed to a simple script
These steps can be condensed to a simple platform neutral script as follows:
This script would need modifying for each container being built, but you could easily make it parameterized or configuration drive.
A Note on Registry Standards
Oracle’s Container Registry has adopted the Open Registries standard for OCIR. Open Registries come under the Linux Foundation‘s governance. This standard has been adopted by all the major hyperscalers (Google, AWS, Azure, etc). All the technical spec information for the standard is published through GitHub rather than the main website.
I’ve been fortunate enough to appear on a podcast with the excellent Coding Over Cocktails team from Toro Cloud. we got to talk about some of the ideas discussed in my Logging In Action book. You can check the podcast out via their website which includes all the episode details and links to all the platforms that host the podcast. There have been some great previous guests such as Luis Weir (my old boss), Chris Richardson of Microservices.io, Matthew Reinbold from Postman, Sam Newman to name just a few.
Oracle’s product portfolio is significant, from databases (obviously) to GraalVM to a cloud platform capable of competing with GCP, AWS, and Azure. This means locating the Oracle-provided plugins, or community ones can get messy. Depending on your perspective Oracle Developer Plugins could relate to Java and GraalVM or Oracle Database.
As broad as the portfolio, is the Oracle details regarding the plugins. So the following two tables represent what we’ve identified as Oracle-provided tooling, and the second table of plugins we’ve used when working on Oracle-based solutions from the community.
Name / Plugin Search
Description / Additional Details
Related resource links
search:Oracle Labs This will return all the Oracle plugins related to GraalVM
SuiteCloud Extension for Visual Studio Code is part of the SuiteCloud Software Development Kit (SuiteCloud SDK), a set of tools to customize your NetSuite accounts.
Github actions is a means by which actions like commits to github trigger external infrastructure to perform actions such as creating application binaries.
My eldest son is studying computer science at school. As part of that course, like most educational settings they’re using Python to teach programming skills. Having sat with my son to help him get to grips with the coding the different ways of looping, implementing conditions, variable scopes and so on it has been interesting to see that school student level programming books take developers through very very simple steps with the rewards of success immediate but of limited value.
The challenge and concern, with this, is the step from this to delivering something meaningful, that continues to provide a sense of reward, while also something that is closer to real-world work.
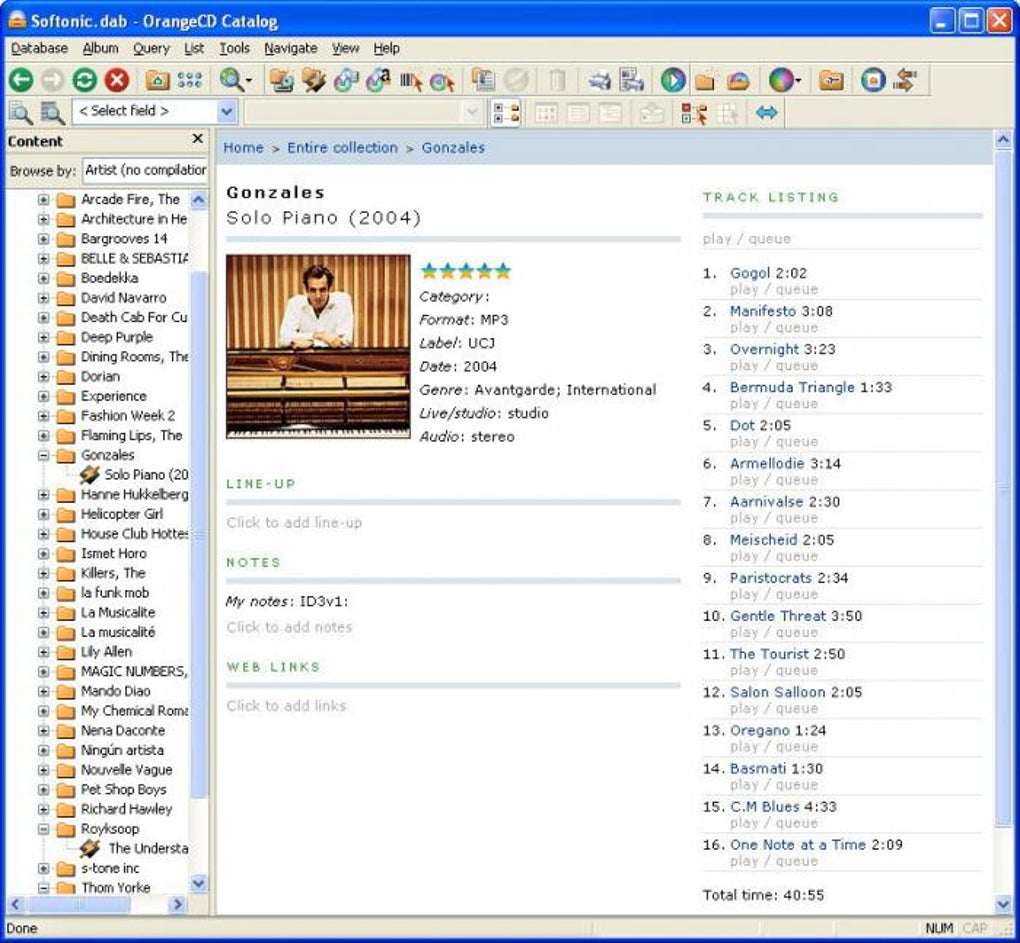
This is where a small project I had comes into play. I have for many years been using an app called Orange CD catalog to record all the details of my music collection. The only problem is that it is a thick desktop app and the web solution called Racks and Tags hasn’t seen much development from what I can see for a long time and by current user experience looks archaic. As you may have guessed our pet project is to provide a web interface for the exported data from the Orange CD catalog. You can see the code in my GitHub repo here). I’ve carefully structured the code so the logic of processing the data (i.e. loops and conditions using data structures – using Python’s XMLTree library, which behaves a lot like lists – helping with basic learning). The web serving tier is implemented with Flask using simple annotations. This provides a nice opportunity to talk about the use of HTTP. The Jinja templates are also kept separate, so we don’t get bogged down with HTML, which can be a bit messy (IMHO).
Orange CD Catalogue
We’ll deploy the solution to our little Raspberry Pi, so it can be used anywhere in our network. Ultimately we could use it to stream the albums I’ve ripped to MP3. If my son wants/needs to learn a little bit about databases – then migrating the data into something like SQLLite becomes a simple development opportunity.
This does mean some prep work and including part of the solution, so something works very quickly. For me that’s fine, my Python web skills could benefit from some work and Jinja2 is new to me. But I could take the project embed suitable security and deploy it to my free Oracle cloud instance as a container into K8s. Those bits I won’t be sharing (minimize the risk of someone wanting to test how well I patch code etc).
Feel free to take the code and use it for yourself, extend, etc. But you don’t have to use my idea. The important thing is the idea is going to interest your child. But keep it simple. for example, if your child is a gamer, then perhaps you generate a simple data extract from the gaming servers to capture player performance, then your app does simple things like searching the content, sorting it, and providing a vanilla UI. The secret I think is each bit of the project is simple steps and not over well with heaps of code. Provide results quickly for example just search for an album by its title, and get the results into a webpage quickly.
One aspect of logging I didn’t directly address with my Fluentd book was consuming multiline logs, such as those you’ll often see when a stack trace is included in the log output. Implementing the feature with Fluentd isn’t hugely complex as it leverages the use of regular expressions (addressed in the book in more depth) to recognize the 1st line in a multiline log entry and for subsequent lines.
I didn’t address it for a couple of reasons:
Using parsers is fairly inefficient, particularly when you’re using a parser to just decide how to then transform a line (this is why I’m not a huge fan of some of the 12 Factor App‘s recommendations when it comes to logging).
Incorporating into your Fluentd parser configurations for specific app log setups is arguably increasing the level of coupling.
Many logging frameworks can talk directly to Fluentd as we saw in the book. This is can be more efficient, which means that the log event is more likely to be passed over in a structured format (therefore less work to do).
But let’s also be realistic, many applications will be configured to simply log to a file and aren’t likely to be changed. At which point we do need to process such situations, so is it done? The process remains largely the same as the tail plugin we illustrated. Except we introduce a different parser called multiline. The documentation provided by Fluentd includes several examples of multiline configurations that will work for default log formats (such as Log4J and Rails). If we took our most basic source setup:
Then assuming our log Simulator played back multiline logs (the provided configuration doesn’t do that) extended to consume standard Log4J2 logs we would have a configuration as follows:
As you can see we’ve set the parser type to multiline. Then there are two regular expressions, format_firstline is used to help recognize the start of a log event. Every line of the log is tested with this expression as we now assume unless this produces a valid result that the line will be part of a multiline event. If you look at the expression you’ll realize it is looking for a DateTime stamp in the form YYYY-MM-DD. This does mean if you generate a log that starts with the date even if it is part of a multiline output then you’ll trip up the parser. You could extend the expression – but the longer it is the slower the processing.
Following format_firstline we have in our example format1 which describes how to process the first line. This can be extended to define how to handle subsequent lines but this could be multiple format definitions. They do need to be presented in numerical order eg. format1, format2, format, and so on.
LogSimulator – Playing back multi-line logs
The Log simulator uses a very similar mechanism to Fluentd to understand how to playback multiple line logs. When it is reading the log lines in for replay it uses a regular expression to recognize the start of a new log entry (FIRSTOFMULTILINEREGEX) defined in the properties file. The simulator will concatenate lines together until it either hits the end of the file or has a new line that complies with the REGEX. It stores the line with an encoded /n (newline character). It will then print the log using the format specified and will allow the /n to create a newline (or not) based on another config parameter (ALLOWNL).
Fluentd has an incredible catalogue of plugins including notification and collaboration channels from good old-fashioned email through to slack, teams, and others.
The thing to remember if you use these channels is that if you’re sending errors, from application logs it isn’t unusual for there to be multiple error events as a root event can cause a cascade of related issues. For example, if your code is writing transactions to a database and the database goes down with no failover mechanism, then your code will most likely experience an error, roll back the transaction perhaps to some sort of queue, and then try to process the next event. Which will again fail. This is the classic situation where multiple errors will get reported for the same issue. This problem is often referred to as a mail storm given that there was a time when we didn’t have social collaboration tools and everyone used email.
There are several ways to overcome this problem. But the most simple and elegant of these is using the suppress plugin in its filter mode.
<filter **>
@type suppress
interval 60 # period in seconds when the condition to supress is triggered
num 2 # number of occurences of a value before suppressing
attr_keys source # the element of the event to consider.
</filter>
In this example if we encounter an event with an attribute called source containing the same value twice then the suppression will kick in for 60 seconds. If you want the key to the valuebeing checked to be the tag then simply omit the attr_keys parameter.
Of course, we don’t want the suppression to kick in if the same value in the attribute keys occured once every few hours. To address this the occurence count is applied over not a time period, but a number of events received by the configuration of max_slot_num which defaults to 10k, but resets
In the filter mode, this plugin is best positionbed immediately before the match block. This means we don’t accidentally suppress messages before they are routed anywhere else.
For the purposes of a demo this is less of an issue. But for a realworld use case would probably benefit from some tuning. All the documentation for this plugin is at https://github.com/fujiwara/fluent-plugin-suppress
Before joining Oracle I used to typically refer to a couple of key resources from Oracle – docs.oracle.com, and occasionally developer.oracle.com and ateam-oracle.com. We’d obviously use cloud.oracle.com and the main oracle.com to be able to reference published stats, success references etc. Now I’m part of the company and working in the OCI product team with an outbound side of things, I needed to gem up on all the assets that exist. So that we can help contribute, and ensure that they are up to date etc. In doing so, the number of resources available is so much more than I’d realized.
Upon reflection, this may have been from the fact we didn’t drill down deeply enough, also in part that Capgemini has its own approaches and strategies as well.
This in part is linked to the organizational structures e.g. OCI Product Management’s outbound work overlaps with the Marketing Developer Relations, for example, something that is inevitable in an organization that provides such a diverse portfolio of products.
For my own benefit, and for others to exploit, the following table summarises the different areas of information. The nature of the content and – where content overlaps or is presented in different ways.
We’ve moved this content so it can be easily revised to here (and accessible from the site menu). But also available here …
The members of this team are the ‘gurus’ of product applications. These cover a range of domains – structured in a similar way to blogs.oracle.com with different posts. These posts represent patterns and solutions to problems encountered by the team. How to, or not to implement things. This can overlap with some blogs in so far as both product blogs and A-Team blogs may address how to leverage product features.
Developer relations lead, which covers not only Oracle products but also the application of open source. By its very name, there is a strong emphasis on coding (rather than low-code) covering not just Java but .Net languages such as C#, Node, JavaScript, and so on. There is some content overlap here with the Architectural Center, where Architecture Centre provides reference solutions.
Developer relations lead, which covers not only Oracle products but also the application of open source. By its very name, there is a strong emphasis on coding (rather than low-code) covering not just Java, but .Net languages such as C#, Node, JavaScript, and so on. There is some content overlap here with the Architectural Center, where Architecture Centre provides reference solutions.
This is the Architecture Center which provides reference solutions. But these aren’t exclusive to the SaaS products (which would be easy to interpret). A lot of examples cover deploying and running open-source solutions on IaaS, for example, Drupal, WordPress, and Magento to name just a couple. A lot of these are backed up with scripts, Terraform, and code to achieve the deployment and configuration. In addition to this, there are use cases of what customers have deployed into production (known as built and deployed).
This contains a lot of free tutorials and labs that can be taken a run to implement different things, from deploying a Python with Flask solution on Kubernetes to Creating USB Installation Media for Oracle Linux with Fedora Media Writer. As you can see from these examples, the tutorials cover both Oracle products and open source. These resources interlink with the Architecture Centre and can overlap with developer.oracle.com.
This contains the code artifacts developed by Developer Relations and the Architecture Center team. So covers Reference Architectures, tutorials, and Live Labs all freely available to use.
This provides a catalog of links to the various open-source repositories available. This includes oracle-sample and devrel but also the many other projects including, but not limited to Helidon, Fn, Verrrazano, GraalVM, Apiary
This is really for the educational community (Universities, Colleges & Schools) and provides resources to take you from zero to certified skills for Java and Oracle Database.
This provides a catalog of links to the various open-source repositories available. This includes oracle-sample and devrel but also many other projects including, but not limited to Helidon, Fn, Verrrazano, GraalVM, Apiary
YouTube training videos. With multiple channels based on different technologies.
Java (OpenJDK and Oracle JDK)
A number of Oracle open-source projects have their own independent web resources as well. Helidon includes additional technical resources. The ones we know more about are : Helidon, Fn, Verrrazano, GraalVM, Apiary But it includes references to Java core language etc.
Managed by Jurgen Kress (Prod Mgr for Oracle PaaS). It acts as an aggregator for contributions from the community and shares news about what is happening within Oracle to support customers and partners in the PaaS space.
Perhaps not access usable as documentation, how-to, etc. but Podcasts can yield a lot of broad picture insights. Oracle has a range of podcasts covering a diverse range of subjects. Not all podcasts are active at any one time. But the site provides a catalog and episode list.
's Blog")













You must be logged in to post a comment.