I’ve always had a fascination for pirate radio. A chance to hear non-mainstream playlisted music – that Peelsque subversiveness. My inner DJ may not be John Peel, probably closer to Lauren Laverne and Jo Whiley with the geekiness of Paul Gambaccini, but here are some suggested playlists …
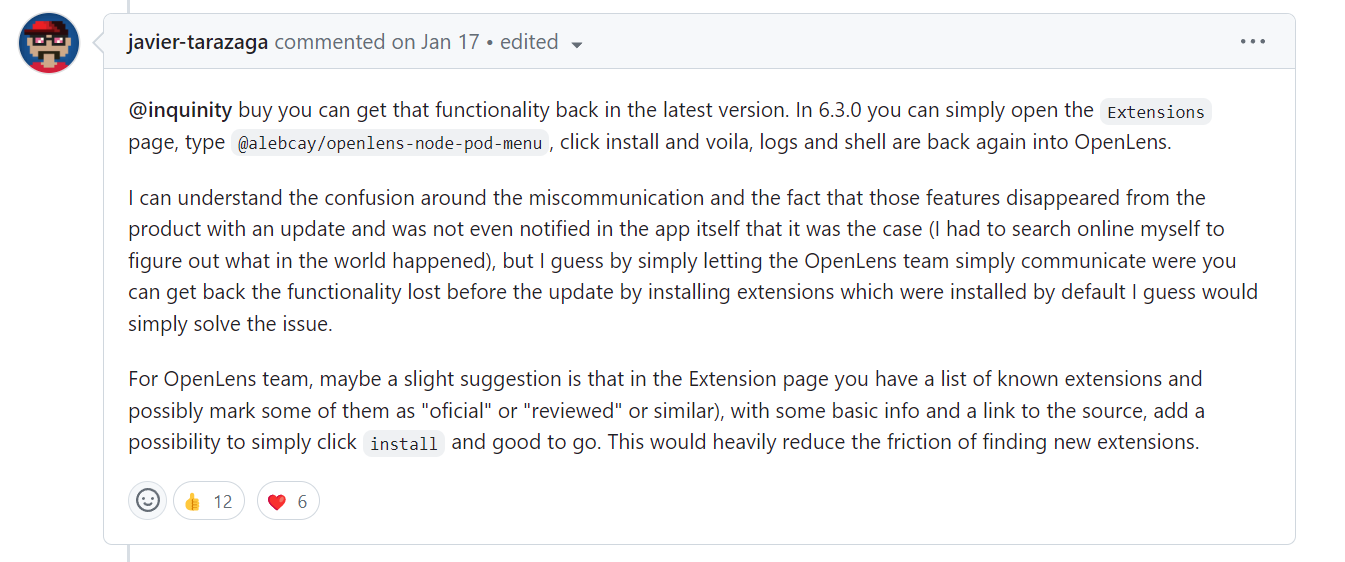
I wrote about how much I like the lens app K8s dashboard capability without needing to deploy K8s dashboard. Sadly recently, there has been some divergence from K8sLens being a pure open source to a licensed tool with an upstream open-source version called Open Lens (article here). It has fallen to individual contributors to maintain the open-lens binary (here) and made it available via Chocolatey and Brew. The downside is that one of the nice features of K8sLens has been removed – the ability to look at container logs. If you read the Git repo issue on this matter – you’ll see that a lot of people are not very happy about this.
If you read through all the commentary on the ticket, you’ll eventually find the following part of the post that describes how the feature can be reintroduced.
In short, if you use the extensions feature and provide the URL of the extension as @alebcay/openlens-node-pod-menu then the option will be reintroduced. The access to the extension is here:
I’m not sure why, but I did find the installation a little unstable, and needed to reinstall the plugin, restart OpenLens and reenable the plugin. But once we got past that, as you can see below the plugin delivered on its promise.
The problem with the licensing is that it doesn’t distinguish between me as an individual and using Lens for my own personal use vs. using Lens for commercial activities. The condition sets out:
ELIGIBILITY:You or your company have less than $10M in annual revenue or funding.
Given this wording, I can’t use the licensed version, even if I was working on an open-source project and in a personal capacity, as the company I’m employed by has more than $10 million in revenue. For me, the issue is $200 per year is a lot for something I only need to use intermittently. While I get k8slens includes additional features such as Lens Security which performs vulnerability management, and Lens Teamwork, along with support, are features and services that are oriented to commercial use – these are features I don’t actually want or need. Lens Kubernetes sounds like an interesting proposition (a built-in distribution of K8s), but when many others already provide this freely – from Docker Desktop to Kind it seems rather limited in value.
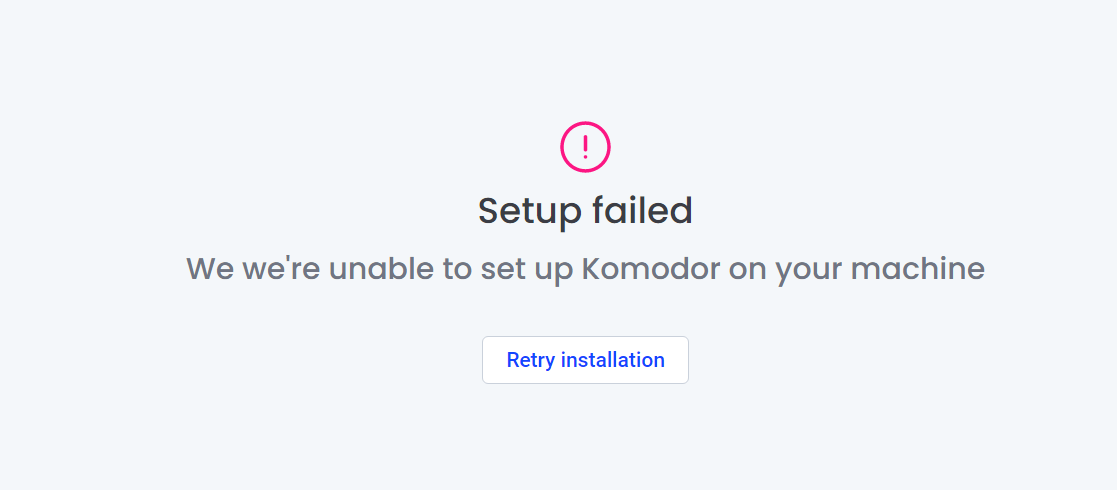
We did try installing Komodor, given its claims for an always free edition. But on my Windows 11 Pro (developer early access) installation, it failed to install, as you can see:
The API blog is part of a larger piece that explores the use of APIs across some of the industries that Oracle works in and how APIs can enable future innovations. The piece on OCI Queue is almost the opposite of the APIs material. Very detailed and implementation specific, covering the technical details of Terraform and the Stomp messaging protocol.
DZone
We also have an article over on DZone now, for regular readers of my blog, this is familiar stuff, as it looks at the LogGenerator utility I’ve built and working on custom extensions so it can be used with OCI to generate Notifications, messages on OCI Queue and more.
Presenting…
I’ll be presenting to the Bucharest Tech Week. With a presentation exploring Monoliths in the context of microservice solution delivery.
Outside of my Oracle cloud-related content, we’ve just published an article on DZone. Those who follow this blog will be familiar with the article theme as it relates to the Log Simulator work. We’ve also written for Devmio – although we don’t yet know when the article will be published and whether the content will be publicly available or behind their paid firewall.
The last week or so has been the DeveloperWeek 23 Conference – in Hybrid form, with the physical event last week and online this week. Circumstances prevented me from attending physically, but yesterday I was honored with the opportunity to present virtually. My session covered the adoption of API Streaming as an alternative approach to needing to poll with APIs to get the latest data state/updates.
One of the benefits of using cloud providers is the potential to scale solutions to meet demand by scaling out with additional compute nodes without concern for physical capacity limits (cost considerations are smaller, but still apply). Dynamic scaling is typically driven by monitoring defined groups of nodes for CPU use and when demand hits a threshold an additional node is spun up. Kubernetes can create some more nuanced scaling configurations but this is tends to be used for microservice style solutions.
This is well and fine, but if we need to finesse the configuration to ensure multiple container instances (such as microservices) can be allowed on a single node without compromising the deployment of containers across nodes of a cluster to provide resilience things can get a lot more challenging. We also want to manage the number of active containers – we don’t want to have unnecessary volumes of containers effectively idling. So how do we manage this?
In addition to this, what if we’re using services that demand tens of seconds or even minutes to be spun up to a point of readiness – such as instantiating database servers, adding new nodes to data caches such as Coherence which will need time to clone data, and adjust the demand balancing algorithms? Likewise, for more traditional application servers. Some service calls will impact upstream configuration changes, such as altering load-balancing configurations. Cloud-native Load Balancers typically can understand node groups, but what if your configuration is more nuanced? If you’re running services such as ActiveMQ you need to update all the impacted nodes in a cluster to be aware of the new node. Bottomline is some solutions or solution parts need lead time to handle increased demand?
This points to more advanced, nuanced metrics than simply current CPU load. And possibly the scaling algorithm needs to be aware of lead times of the different types of functionality involved. So how can we advance a more nuanced, and informed scaling logic? You could look at the inbound traffic on firewalls or load balancers. But this will require a fair bit of additional effort to apply application context. For example is the traffic just getting directed to static page content? We do need to derive some context so that the right rules are impacted. Even in simple K8s only hosted solutions a cluster may host services that aren’t related to the changes in demand and need to be scaled as a result.
A use case perspective
Let’s look at this from a hypothetical use case. We’re a music streaming service. Artists can control when their music is made available, but the industry norm is 12:01am on a Friday morning. There is always a demand spike at this time, but the size of the demand spike can vary, with some artists triggering larger spikes (this isn’t directly correlating to an artist’s popularity, some smaller groups can have very enthusiastic fans) – so dynamic scaling is needed, and reactive to demand. Reporting, analytics, and payment services see cyclical bumps around the monthly financial periods. These monthly cyclic activities can also be done during quieter operating hours. So it is clear we may wish to apply logical partitioning, but for maximum cost efficiency keep everything in the same cluster. There are correlations between different service demands. Certain data services see increased demand during the demand spikes and reporting period, but ‘The bottom line is we need to not only address dynamic scaling, but tailor the scaling to different services at different times.
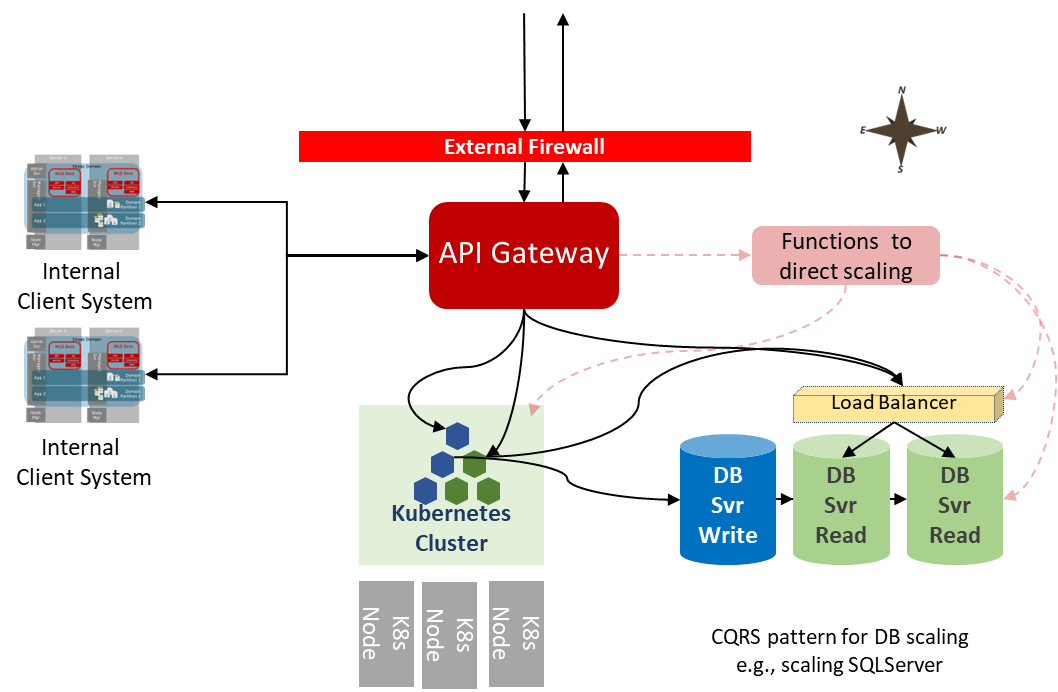
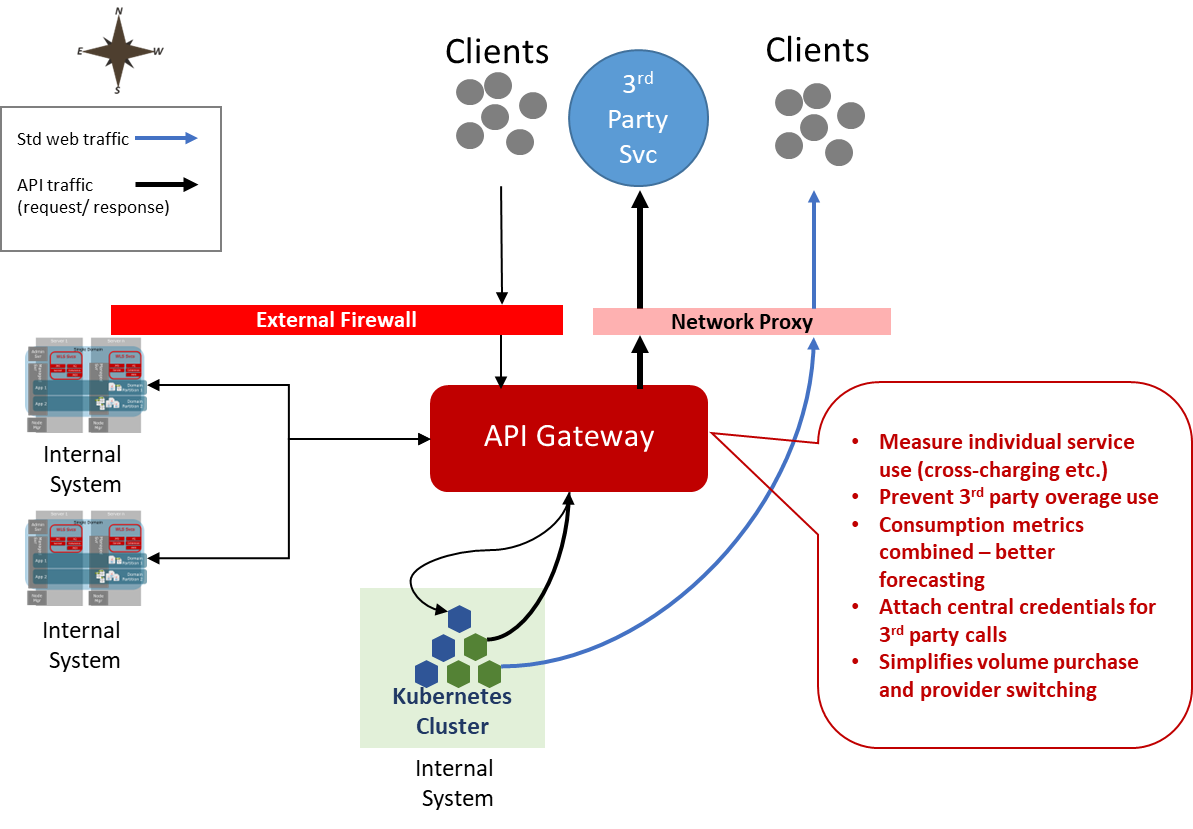
Back to our question – how do we manage the scaling? We could monitor the firewall and load balancer logs and analyze the kinds of requests being received. That would need additional processing logic to determine which services are receiving the traffic. But our API gateway is likely to have that intelligence implicitly in place as we have different API policies for the different types of endpoints. So we can monitor specific endpoints or groups of endpoints very easily – meaning we can infer the types of traffic demand and how to respond. Not only that, we may have API plans in place so we can control priority and prevent the free versions of our service from using APIs to initiate high-quality media streams. So we already have business and specific process meaning. So linking scaling controls such as KEDA (Kubernetes Event-driven Autoscaling) directly to measurements such as plans and specific APIs creates a relatively easy way to control scaling. Further, we may also use the gateways to provide a rate throttle so it’s not possible to crash our backend with an instantaneous spike. This strategy isn’t that different from an approach we’ve demonstrated for scaling message processing backends (see here and here).
Representation of how we can use the metrics from a gateway to not only support the scaling of a K8s cluster but also other cloud services
We can also use the data KEDA can see in terms of node readiness to adjust the API Gateway rate limiting dynamically as well. Either as a direct trigger from the number of active container instances or by triggering a more advanced check because we still have to address our services that need more lead time before relaxing the rate limiting.
Handling slow scaling services
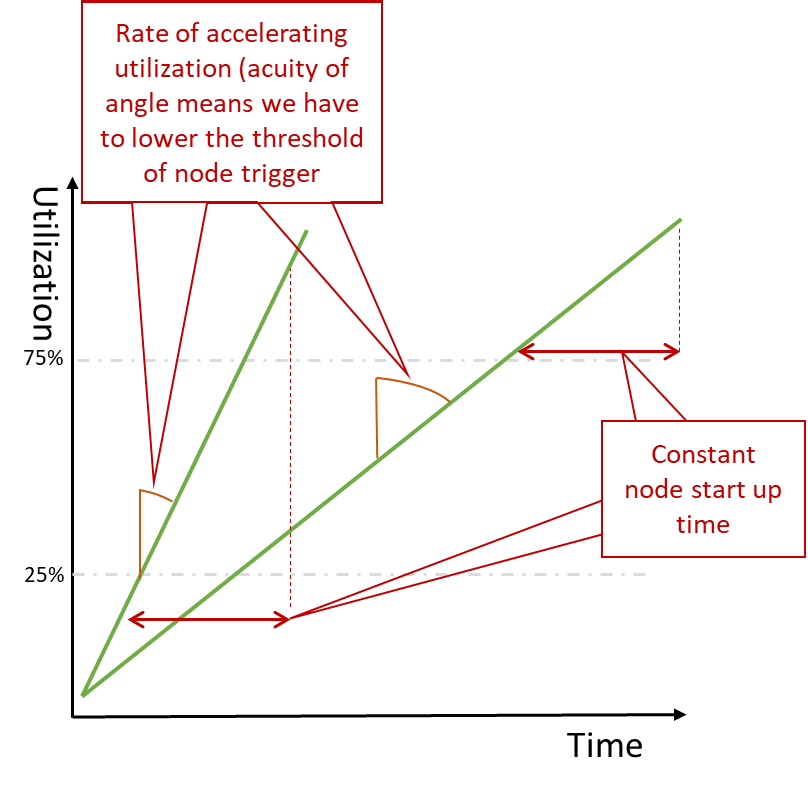
So we’ve got a way of targeting the scaling of services. But what do we do to address the slower scaling services we described? With the data dimensioned, we can do a couple of things. Firstly we can use the rate of change to determine how many nodes to add. A very sudden increase in demand and adding a node at a time will create the effect of the service performance stuttering as it scales, and all additional capacity is suddenly consumed and then scales again. Factoring in the rate of change to the workload threshold and the context of which services could generate the increased workload can be used to not only determine which databases may need scaling but also be used to adjust the threshold of workload that actually triggers the node introduction. So a sudden increase in demand on services that are known to create a lot of DB activity is then met with dropping the threshold that triggers new nodes from, say, 75% to 25% so we effectively start the nodes on a lower threshold, means the process is effectively started sooner.
With different rates of utilization growth, we can see that we need to alter the trigger threshold for launching new resources
For this to be fully effective we do need the Gateway tracking traffic both internally (East-West) and inbound (North-South). Using the gateway with East-West traffic means that we can establish an anti corruption layer.
Conclusion
Not all parts of a solution will be instantaneous in scaling – regardless of how fast the code startup cycle might be, some services have to address the need to move large chunks of data before becoming ready, e.g., in-memory databases. Some services may not have been built for the latest business demands and the ability to exploit cloud scale and dynamic scaling. Some services need time to adjust configurations.
We may also need to adjust our protection mechanisms if we’re protecting against service overloading.
Scaling capabilities that have response latency to the scaling process can be addressed by achieving earlier, more intelligent recognition of need than warning simply by CPU loads hitting a threshold. The intelligence that can be derived from implicit service context simplifies the effort in creating such intelligence and makes it easier to recognize the change. API Gateways, message queues, message streams, and shared data storage are all means that, by their nature, have implicit context.
Pushing the recognition towards the front of the process creates milliseconds or possibly seconds more warning of the demand than waiting for the impacted nodes to see compute spikes.
The Phoenix Project by Gene Kim has been recommended reading for the IT industry for a long time now. It’s been on my to-read list for a good while, but to be candid, it never made the top of my reading list, as I had some reservations. Who wants to read a novel about IT if you already work and live it every day.
Recently IT Revolution, to celebrate its 10th anniversary, offered the book through Amazon for free for a limited period (even now, as a Kindle ebook, it isn’t that expensive anymore). Given I had determined I should read it at some point, I took the opportunity to get a copy. As it happens, through the Christmas break, I got into a run of reading books, and with it being at the top of my ebook list, I bit the bullet.
First of all, the story was engaging and very readable, characters are likable, human, and relatable. It isn’t a huge book either (perhaps I’ve been looking at too many 500+ page novels), making it a fairly quick read. As a pure novel, some of the devices to keep the narrative moving along were perhaps a little obvious, but then given the goal of the story, that isn’t really an issue. It didn’t break the reading flow, which did keep the pages turning with a plausible story; plausible enough to wonder how much of the story was based on a real-life experience of Gene or one of his writing collaborators.
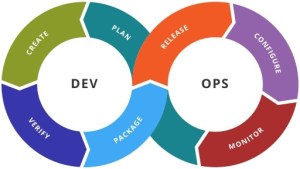
What struck me the most is that most industry writing I have read doesn’t address all the points the book makes. So, DevOps, as is typically presented by a lot (most ?) content, uses some variation of a diagram like the infinite cycle, as shown here:
Not only that, it is common to view DevOps as focusing on either :
Automation, particularly around CI/CD and IaC (Infrastructure as Code)
The development team also owns the operations tasks
But the book portrayed DevOps as both and neither of these. I say this as these approaches can help with the goal, but they should be subservient to the larger objective. Unfortunately, we do get caught up with the mechanics and tools and not the wider goal. The story is about how to deliver business value and needs in a streamlined manner, so we aren’t tying up the investment (time or spend) any longer than necessary. Yes, that does mean IaC and CI/CD style automation but only in service of the goal, which is the business need, not IaC.
The book also highlights the point of continuously working on improvement and paying down against debt, as removing debt is part of the way we remove the blockages to the streamlining (in the story, we actually see the release pipeline being temporarily stopped so that time could be invested in paying down the debt). Yet, this aspect is rarely discussed in a lot of the industry content on the subject. Maybe we are, in part, our own enemy here, as debit work is not greenfield. It is going back over old ground and making it better. We all love breaking new ground and leaving the past behind. Not to mention many organizations measure progress on the number of features rather than how well a feature serves the business goals. I have to admit to that mistake, which in our world of microservices is a bit of a mistake. After all, aren’t microservices about doing one thing and doing it well?
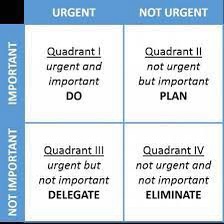
Another interesting view that the book put a lot of emphasis on was a variant of what is sometimes called the Eisenhower matrix. Anyone who has done any leadership training will most likely recognize it (see below).
However, the quadrants of work are as the book describes them are:
Quadrant 1 – Project work (i.e., planned activities central to the business)
Quadrant II – IT work (work that is planned and needed but doesn’t originate from the business, such as building new infrastructure)
Quadrant III – Updates and changes (e.g., system patching)
Quadrant IV – Unplanned (e.g., outage recovery work, demands on the team that has bypassed scheduling / divert individuals from the agreed goals, etc.)
The key difference between this representation and that of the book’s work definition is the words on each of the columns and rows. For example, Quadrant IV isn’t ‘Not Important’ and ‘Not Urgent’ – but it would be fair to say ‘Not Wanted’ and ‘Not Productive’. Unplanned work is the killer and roughly aligns with quadrant IV. This comes from the issues of not dealing with technical debt and solution facilities etc.
My last observation is that in the last couple of years, we have seen the rise of DevSecOps, which recognizes the need that security should be as much of the delivery process as Dev and Ops. The book (written 10 years ago) showed that security should be part of the DevOps process. Like other areas, the story seeks to address the point that security focussing on just the development and operational processes while necessary for things like catching OWASP Top 10 also needs to see the bigger picture otherwise, you could easily add additional needs that are already handled by controls elsewhere in the end-to-end business processes. That doesn’t mean to say security controls can5 be in software, but are they part o& improvement and pushing actions left vs. getting out of the starting blocks?
More reading
The book provides references, but for my own personal benefit, a number of particularly interesting and useful references are made, which may interest:
The Goal by Eliyahu M. Goldratt (a novel addressing his Theory of Constraints in the same way as The Phoenix Project is a novel around the DevOps handbook)
Most larger organizations route their outbound web traffic through a web proxy. The primary motivation for this is to measure where traffic is going. Log traffic for analysis to try and detect activities trying to egress data that should remain within the organization and prevent access to websites that are considered harmful in one form or another.
So why consider an API Gateway as part of an outbound traffic flow? After all, isn’t a Gateway there to protect us? Several very good reasons. Let’s look at them:
Managing the use of an external paid service. You may have multiple solutions using a third-party service – for example, an SMS service. Rather than expecting all these different calls to the external API, each having a copy of the 3rd party credentials to manage, we could use the gateway as a single point to attach the credentials.
When it comes to being charged for a service, being able to identify the requests at the API level makes it very easy to track your own consumption and forecast forward before being billed. This is really helpful if you have an agreement that provides a good price for pre-booked capacity and a higher charge for overage/capacity not pre-booked.
Economies of scale for using 3rd party services can be very powerful. But it can also present two problems.
Switching providers quickly can be difficult as multiple points of possible change
How to partition the cost of the external service across different departments if everyone is using a common account.
The first of these issues can be easily overcome using the anti-corruption layer pattern where the gateway represents the correct route so it can reformat the requests in one place to work with a different provider.
At the same time, we can more intelligently use Gateway’s metering mechanisms rather than having to implement functionality to mine the proxy’s logs.
Of course you can achieve same effect without a gateway, but you don’t get the benefits that a gateway will offer out of the box. In addition the chances are that you have already got an API Gateway running for your current North-South traffic.
Just before the Christmas break, I got to record an excellent podcast with Anatolii of UNmiss. It was a great conversation about Cloud Integration, APIs, and approaches to Cloud-based integration. While I am not in a consulting role in the conventional sense, a lot of an Evangelist’s task is still to listen, understand, and, when necessary, challenge assumptions and help people understand how technologies can help address problems. This might include sketching out a journey of evolution and improvement. During the podcast, we discussed some of these ideas.
In addition to some of the practices, we’ve used. The conversation touched upon books. My books are on the sidebar, including links to Manning, who, as a publisher, I’d recommend. I’ve previously blogged some reading recommendations and previously written some book reviews which may be of interest to anyone following up.
We haven’t blogged too much recently as we have been busy helping get and producing content for my employer Oracle, working with Software Engineering Daily, and developing a collaborative book. So, I thought I’d pull together some links to these new resources.
's Blog")









You must be logged in to post a comment.