's Blog")
Tags
Cipher, context, GQL, graph, LLM, LLMs, Natural Language, NL, NL2SQL, ontology, OpenCipher, Oracle, OWL, PGQL, RDF, SPARQL
A number of books on the use of LLMs demonstrate how to generate queries against a table from natural language. There is no doubt that providing an LLM and the definition of a simple database and a natural language question, and seeing it provide a valid result is impressive.
The problem is that this struggles to scale to enterprise scenarios where queries need to run on very large databases with tens, if not hundreds, of tables and views. Take a look at the results of the evaluation and benchmarking frameworks like Bird, Spider2, NL2SQL360, and others.
So why do we see a drop in efficacy between small use cases and enterprise systems. Let’s call out the headline challenges you may run into…
- The larger the database schema, the more tokens we use just to describe it.
- Understanding how relationships between tables work isn’t easy – do we need SQL to include a join, union, or nested queries?
- Which tables does the LLM start with?
- Does our natural language need the LLM to perform on-the-fly calculations or transformations (for example, I ask for data using inches, but data is stored using millimeters)?
- When the entity needs to use attributes that contain names (particularly people, places, chemicals, and medicines), the queries will fail, as there are often multiple spellings and truncations of names.
- Does the LLM have permissions to access all the schema (enterprise systems will typically have data subject to PII).
Does this mean that NL2SQL, in practice, is a bust? Not necessarily, but it is a lot harder than it might appear, and how we apply the power of LLM’s may need to be applied in more informed and targeted ways. But we should ask a few questions about the application of LLMs that may impact tolerance to issues…
- Will users understand and tolerate a degree of risk and the possibility of an error resulting from hallucination? It’s just like using a calculator for performing calculations – an error in the keying sequence or a failure to apply mathematical precedence, and the result will be wrong, but do you look at the answer and ask yourself whether this is in the right ‘ballpark’? For example, 4 + 2 x 8, if you simplify to 6 x 8, you’ll get the wrong result, as multipliers have precedence over addition, so we should perform 2 x 8 first. If there is no tolerance for error, you need your solution to be completely deterministic, which rules out the use of LLMs.
- More generally, will we tolerate SQL that is not performance-optimized? As we’re dealing with a non-deterministic system, we can’t anticipate all the possible indices that might help or other optimizations that could improve the query. If you’re thinking of simply creating many indexes to mitigate risk, remember that maintaining indexes comes at a cost, and the more indexes the SQL engine has to choose from, the harder it has to work to select one.
- What level of ‘explainability’ to the answer does the user want? Very few users of enterprise systems will want to have an answer to their questions explained by providing the SQL, and in the world of SaaS, we don’t want that to happen either.
- The last dimension is: if a user submits a question prematurely or with poor expression, do we really want to return hundreds or hundreds of thousands of records?
In addition to these questions, we should look at the complexity of our database. This can be covered using several metrics, such as:
- NA – Number of Attributes
- RD – Referential Degree (the amount of table cross-referencing)
- DRT – Depth Relational Tree (the number of relational steps that can be performed to traverse the data model)
The complexity score indicates how hard it will be to formulate queries; in other words, the LLM will have to work harder and, as a result, be more susceptible to errors. So, if we want to move forward with NL2SQL then we need to find a means to reduce the scores.
If you’d like to understand the formulas and theory, there are papers on the subject, such as:
How we respond to these questions will demonstrate our tolerance for challenges and our ability to drive enterprise adoption. Let’s look at some possible strategies to improve things.
Moving forward
One step forward is that each attribute and table can be described; this is essential when using shortened names and acronyms. Such schema metadata can be further extended by describing the relationships and purposes of tables, and even advise the LLM on how to approach common questions, start with table x when being asked about widgets, for example. In many respects, this is not too dissimilar to how we should approach APIs. The best APIs are clearly documented, have consistent naming, and so on.
We can use the LLM to analyse the question and use the result to truncate the provided schema details. For example, in an ERP system, we could easily generate natural-language questions about a supplier or monthly operating costs. But reducing the schema by excluding details from supplier-related tables will narrow the LLM’s scope and, therefore, reduce the likelihood of getting details wrong. This is no different from addressing an exam question and taking a moment to strike out redundant information, as it is noise. You could say we’re removing confounding variables. This idea could be taken further by restricting agents to only working with specific subdomains within the data model.
We can clean up questions. When names are involved, we can use standard language models to extract nouns and their types, then look them up before we formulate an SQL statement. If the question relates to a supplier name, we can easily extract it from the natural-language statement and determine whether such an entity exists. This sort of task doesn’t require us to use powerful, clever foundational LLMs; there are plenty of smaller language models that can do this.
Inject context from the UI
Ideally when a natural query is provided, the more traditional parts of the UI are showing the data, the user can navigate through in traditional manner – replacing years of UI use with a blank conversation page is going to really limit the users understanding of what is available in terms of data and the relationships that already exist, I’ve mentioned this before – Challenges of UX for AI. Assuming that we have something more than a blank conversation window, there is plenty of context to the natural language input. Let’s ensure we’re providing this in a rich manner; this could be more than just the fields on the screen, but associated attributes. For example, if the UI is showing a table, then identifying the entities or filters applied may well help.
Simplifying the schema
Most of our systems are not designed to support NL2SQL, but for core processes that demand considerations, such as frequently occurring queries that are efficient, even more importantly, so that we don’t have issues relating to data integrity. Unless you’re fortunate to be working with a greenfield and keeping the data model simple so processes like NL2SQL have an easy time, we’re going to need to take advantage of database techniques to try to simplify the schema (at least as the NL2SQL process sees it). The sort of things we can do include:
- simplify with views
- We can join tables and denormalize table structures, such as supplier and address, for example. Navigating table relationships is one of the biggest risks in SQL processing.
- Use virtual columns so we can offer data in different formats, such as inches and millimetres, so the LLM doesn’t need to apply unnecessary logic, such as transforming data values. Providing the calculation ourselves means we have control over issues such as precision.
- Exclude columns that your NL2SQL does not require. For example, if each table has columns that record who made a change and when, is that needed by the LLM?
- Synonyms and other aliasing techniques
- We can use synonyms to represent the same tables or columns, enabling us to map question entities to schema tables and columns. This can really help overcome specialist column names in a schema that the LLM is less likely to resolve.
- We can also use this to disambiguate meaning; for example, in our ERP, an orders table could have a column called sales. In the context of orders, that would be better expressed as sales-quantity. But then, in the accounting ledger, when we have a sales attribute, that really means sales value.
Simplifying through an Ontology and Graphs
We can model our data and the relationships using an ontology. This isn’t a small undertaking and can bring disruptions of its own. Using an ontology affords us several benefits:
- Ontology can drive consistency in our language and its meaning.
- An ontology in its pure form will capture the types of objects (entities), their relationships to other entities, and their connections to concepts.
- We have the option to exploit standards to notate the ontology in a implementation independent manner.
Applying an ontology allows us to describe the objects, attributes, and relationships in our data model using a structured language. For example supplier has an invoicing address. One key is that we’ve abstracted away how the data is stored (some might refer to this as the physical model, but I hedge on that, as there is a whole layer of science in data-to-storage hardware).
To get to grips with ontology and how we can use it in practice, we need some familiarity with concepts such as Knowledge Graphs, OWL, and RDF. Rather than explaining all these ideas here, here are some resources that cover each technology or concept.
To get to grips with ontology and how we can practically use it, we need some familiarity with concepts such as Knowledge Graphs, OWL, and RDF. Rather than explaining all these ideas here, here are some resources that cover each technology or concept. We’ve added some references for this below.
By modelling our data this way, we make it easier for the LLM by describing our entities and relationships, and, importantly, the description makes it much easier to infer and understand those relationships.
The step up using an ontology gives us the fact that we can express it with a Graph database. We can describe the ontology using graph notation (our entities are objects connected by edges that represent relationships; e.g., a supplier object and an address object are connected by an edge indicating that a supplier has an invoicing address. When we start describing our schema this way, we can begin to think about resolving our question using a graph query.
Not only do we have the relationship between our entities, but we can also describe entity instances with the relationship of ‘is a ‘, e.g., Acme Inc is a supplier.
But, before we start thinking, this is an easily solvable problem; there are still some challenges to be overcome. There is a lot of published advice on how to approach ontology development, including not extrapolating from a database schema (sometimes referred to as a bottom-up approach). If you develop your ontology from a top-down approach, you’ll likely have a nice logical representation of your data. But, the more practical issue is that we can’t convert our existing ERP schema to a fit the logical model, or impose a graph database onto our existing solution; that has horrible implications, such as:
- Our existing data model will, even with abstraction layers, affect our application code (yes, the abstractions will mitigate and simplify), but those abstractions will need to be overhauled.
- Existing application schemas reflect a balancing act of performance, managing data integrity, and maintainability. Replacing the relational model with a Graph will impact the performance dimension because we’ve abstracted the relationships.
- There is also the double-edged challenge of a top-down approach that may reveal entities and relationships we should have in our ERP that aren’t represented for one reason or another. I say double-edged, because knowing the potential gap and representation is a good thing, but it may also create pressure to introduce those entities into a system that doesn’t make it easy to realize them.
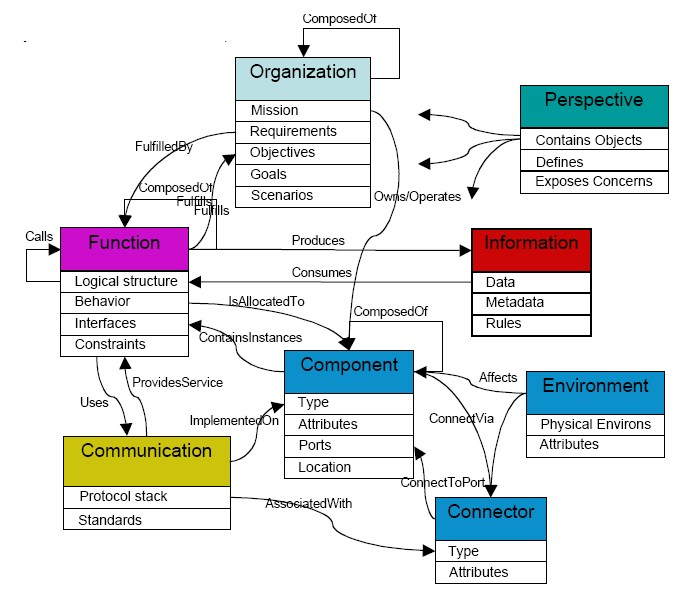
If you follow the guidance on developing an Ontology from the research referenced by NIST, which points to defining ontologies in layers and avoiding drawing on data models.
That said, there is guidance, standards, and tooling for building an ontology from a relational schema, such as the W3C’s A Direct Mapping of Relational Data to RDF, papers such as Bringing Relational Databases into the Semantic Web: A Survey. The true magic of an ontology, aside from its role in driving clarity, is that it can be modelled in a Graph database and therefore queried easily.
There is also the challenge of avoiding the ontology from imposing an enterprise-wide data model, which slows an organization’s ability to adapt to new needs quickly (the argument for microservices and schema alignment to services). While the effective use of an ontology should act as an accelerator (we know how to represent data constructs, etc.) within an organization that is more siloed in its thinking, it could well become an impediment. Eric Evans’ book Domain Driven Design tries to address indirectly.
Graphs – the magic sauce of ontology and its application
With a schema expressed as a graph (tables and attributes are nodes, and edges represent relationships), we can query the graph to determine how to traverse the schema (if possible or practical) to reach different entities. If the relational schema’s details can be enriched with strong semantic meaning in the relationships, we get further clues about which tables need to be joined. We say practical because it may be possible to traverse the schema, but the number of steps can result in a series of joins that generate unworkable datasets.
We could consider storing not just the schema as a graph, but also the data. There are limits when the nodes become records, and the edges link each node; as a result, data volume explodes, particularly if each leaf node is an attribute. Some graph databases also try to manage things in memory – for multimillion-row tables, this is going to be a challenge.
Some databases that support a converged model can map queries, schemas, and data across the different models. This is very true for Oracle, where services exist that allow us to retrieve the schema as a graph (docs on RDF-based capabilities), translate graph queries (SPARQL / GQL) into relational ones, and so on. The following papers address this sort of capability more generally:
- A mapping of SPARQL into conventional SQL
- Mapping between Relational Database Schema and OWL Ontology for Deep Annotation
One consideration when using graph queries is the constraints imposed by meeting data manipulation needs, since most relational database SQL provides many more operators.
Ontology more than an aide to AI
A lot of research and thought pieces on ontology have focused on its role in supporting the application of AI. But the concepts as applied to IT and software aren’t new. We can see this by examining standards such as OWL and RDF. Ontology can support many design activities, such as developing initial data models (pre-normalization), API design, and user journey description. The change is that these processes implicitly or indirectly engage with ontological ideas. For example, when we’re designing APIs, particularly for graph queries, we’re thinking about entities and how they relate. While we tend to view relationships through the CRUD lens, this is a crude classification of the relationship that exists.
Getting from Natural Language to the query
This leads us to the question of how to translate our natural language question into a Graph query without encountering the same problems. This is a question of understanding intent; the focus is no longer to jump to prompting for SQL generation, but to extract the attributes that are wanted by examining the natural language (we can even look to do this with smaller models focusing on language), and tease out the actual values (keys) that may be referenced. With this information, we can determine how to traverse the schema and potentially generate the query. If we can’t make that direct step with the graph (we may be asked to perform data manipulation operations that graph query languages aren’t designed for), relational databases offer a wealth of DML operators that graph query languages lack. We can now provide more explicit instructions to the LLM to generate SQL. To the point, our prompt for this step could look more like a developer prompt. Of course, with these prechecks, we can also direct the process to address ambiguities, such as matching the NL statement to the schemas’ attributes that should be involved.
As you can see through the use of graph representations of our relational data, we can look to move the LLM from trying to reason about complex schemas to examining the natural language, providing information on its intent, and then directing it to generate a formalized syntax – all of which leans into the strengths of LLMs. Yes, LLMs are getting better as research and development drive ever-improving reasoning. But ultimately, to assure results and eliminate hallucination, the more we can push towards deterministic behaviour, the better. After all, determinism means we can be confident that the result is right for the right reasons, rather than getting things right, but that the means by which the answer was achieved was wrong.
Growing evidence that graph is the way to go
This blog has been evolving for some time, since I started to dial into the use of ontologies and, more critically, graphs. I’ve started to see more articles on the strategy as a way to make NL2SQL work with enterprise schemas. So I’ve added a few of these references to the following useful resources.
Useful Resources
- Why ontology for SQL
- Palantir ontology blog series
- Reverse engineering an ontology
- NIST Guidance on ontology
- Basic Formal Ontology
- Timbr.ai on ontology for AI
- Semantic Web Journal
- A novel approach for learning ontology from relational database: from the construction to the evaluation
- Ontology Development 101: A Guide to Creating Your First Ontology
- SPARQL Standard – for querying RDF data.
- Graph Query Language (GQL)
- Property Graph Query Language (PGQL) (and formal standard specification)
- Resource Description Framework (RDF) standard
- Web Ontology Language – OWL standard
- Knowledge Graph & RDF
- Ontology Engineering
- QueryWeaver – open source tool uses Graph to build SQL
- Timbre.ai blog post
A final note on Graph Querying
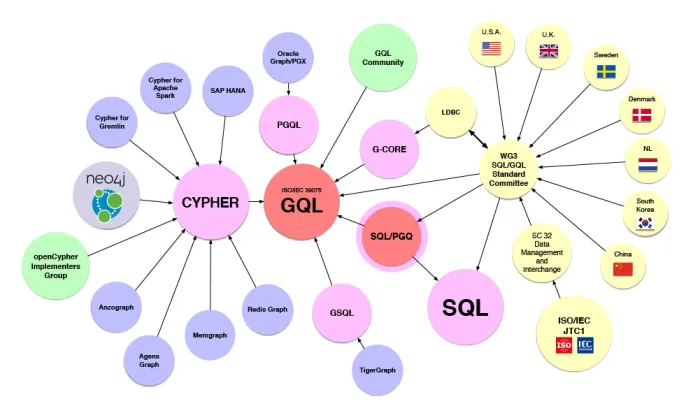
Graph querying can be a bit of a challenging landscape to initially get your head around; after all, there is SPARQL, PGQL, GQL, and if you come from a Neo4J background, you’ll be most familiar with Cipher/OpenCipher. Rather than try to address this here, there is a handy blog here, and the following diagram from graph.build.

You must be logged in to post a comment.