Development trends have shown a shift towards precompiled languages like Go and Rust away from interpreted or Just-In-Time (JIT) compiled languages like Java and Ruby as it removes the startup time of the language virtual machine and the JIT compiler as well as a smaller memory footprint. All desirable features when you’re scaling containerized solutions and percentage point savings can really add up.
Oracle has been leading the way with its work on GraalVM for some years now, and as a result, not only can GraalVM be used to produce native binary images from Java code, GraalVM also supports TuffleRuby and GraalPy, among others. As TruffleRuby is an open-source project, Oracle isn’t the only vendor contributing to it, work effort has also come from Shopify.
Helping Ruby move forward isn’t new for the Shopify engineering team, and part of that investment is that they have just announced the open-sourcing of a toolchain called Ruvy. Ruvy takes Ruby and creates a WebAssembly (WASM) from it the code. This builds on the existing project ruby.wasm. In doing so they’ve addressed the Ruby startup overhead of the language VM we mentioned. They have also simplified the process of deployment, eliminating the need for Web Assembly System Interface (WASI) arguments, and overcome constraints of class loading by reading files by having the code bundled within the assembly and then accessing the content using WASI-VFS, a simple virtual file system.
The published benchmarks show a massive performance boost in the process of executing where the Ruby code needs to be executed by the packaged JIT. For me, this is interesting as one of the related cloud-native trends is the shift from Fluentd to Fluent Bit. Fluentd was built with Ruby and has a huge portfolio of third-party extensions. But Fluent Bit is built using C to get those performance gains previously described. But it does support plugins through WASM. This raises an interesting question can we take existing Ruby plugins and wrap them so the required interfacing works – which should be minimal and more likely to be impacted by the fact Fluent Bit v2 has refined the internal data structure that was common to both Fluentd and Fluent Bit to allow Fluent Bit to more easily engaged with OpenTelemetry.
If the extra bit of wrapping code isn’t complex, then applying Ruvy should mean the core plugin can then work with Fluent Bit. If this can be templated, then Fluent Bit is going to make a big leap forward with the number of available plugins.
Infoworld published a rather clickbait incendiary new item the other week ‘few open source projects actively maintained’. Personally, I find these statements a little frustrating, as it would be easy for the less informed to assume that adopting open-source software is dangerous. There are several missed points here:
How well and frequently are close source solutions being maintained, and does that stop businesses from using end-of-life products? There is big business to be had in offering support to end-of-life solutions. Just look at companies like Rimini Street. Such organizations aren’t going to change software unless there is a major issue.
Not all open-source software is intended to be undergoing continuous maintenance? Shocking until you consider that open-source projects will remain open and available even when they have been declared end-of-life. Why? One of the things about open-source is you don’t know who is using the code, and suddenly pulling the code because the originator has decided they can no longer maintain their investment could put others in a difficult position. So, the right thing is to leave the source available and allow people to fork it so they can continue maintaining their own version of it or until they’ve migrated away. That way, the originator is not impacted by changes.
Next up, not all open-source projects need continued maintenance; many repositories exist to provide demo and sample solutions – so that developers can see how to use a product or service. These repositories shouldn’t need to change often. Frequent change could easily be a sign of an unstable product or service. These solutions may not be the most secure, as you don’t want to complicate the illustration with all the checks and balances that should be considered. Look at it this way: when we start learning a new language or tool, we start with the classic Hello World – which today means pointing your browser at a URL and seeing the words appear on the page. Do we insist that the initial implementation be secure? No, because it distracts from the basic message. For example, in my GitHub repository, I have multiple public repositories with Apache2 licenses attached to them – i.e., open-source. A number of them support the books I’ve written – they aren’t going to change – in fact, change would be a bad thing unless the associated book is corrected (this repo, for example).
When it comes to security vulnerabilities. This needs to be viewed with some intelligence. For several reasons:
As mentioned, our demo examples are unlikely to be patched with the latest versions of dependencies all the time. The point is to see how the code works. Unless the demo relates directly to something that has to be patched and that changes the demo itself. I don’t think it is unreasonable to expect developers to apply some intelligence to ensure dependencies (and therefore the risk of known vulnerabilities) are checked rather than blindly cutting and pasting. The majority of the time, such content will be published with a minimum version number, not a maximum.
Sometimes, a security vulnerability isn’t an issue. For example, I rarely run vulnerability checks on my LogSimulator. Not because I have a cavalier attitude to security but because I don’t expect it to ever be near a production environment, and the data flowing through the tool will be known and controlled by the user in advance of any activity. Secondly, it shouldn’t be using sensitive data, and thirdly, if there was any malicious intent intended, then I’d be more concerned about how secure its data source and configuration is. The tool is a command-line solution. That said, I still apply development practices that minimize potential exploitation.
Don’t get me wrong, there are risks with all software – closed and open-source, whether it is maintained or has security vulnerabilities. A software development team has a responsibility to make informed, risk-aware selections of software (open or closed source). If you have the means to check for risks, then they are best used. It is worth not only scanning our own code but also considering whether the dependencies we use have been scanned if appropriate (e.g. used in production). Utilizing innovations like SBOM, and exercising routine checks and reviews can also help.
While I can’t prove it, I suspect there are more risks being carried by organizations adopting a library that was considered sufficiently secure when downloaded, but subsequent vulnerabilities have been found, or selected mitigations to risks have been eroded over time.
I recently wrote a piece for DZone about visualizing career paths. As an enabler for people to make use of the diagrams to help the visualization, we’ve made the original PowerPoint diagrams used available here:
when you’re testing apps, it is pretty common to want to send JSON via CURL to a local endpoint. The problem is that this usually means that the string you provide curl needs to have characters escaped, such as quote marks. By hand, this can be irritating to sort out, particularly if you’re using an IDE to make sure the JSON is correct. I’d concluded this is hardly a new problem; someone must have produced a nice little multiple-platform command line utility that can do it for you. The result was a bit more surprising.
There are plenty of online utils that solve it, but if you’re working with data, you don’t want to publicly share (or the fiddling around with copy-pasting to your browser). Nothing wrong with these tools, but you can’t script them without resorting to RPA (Robotic Process Automation) either. Here are a couple of services I found that are straightforward, and when I’ve tried them, not plagued by annoying ads.
But finding command line tools, well, finding an answer, has proven a bit more challenging. For removing escaped characters, you could use jq, but we actually want to go the other way to use curl with JSON that has been escaped. I have come across conversations covering the use of bash (making use of awk and sed. Plus, details about how the manipulation could be done in various languages (so you could code your own solution if so inclined. Coding is unlikely to take much effort, but testing permutations is going to demand effort).
The one solution I have found that meant I could escape (or reverse) JSON locally is a plugin for VS Code called appropriately JSON-escaper, which does what is needed in a nice and clean manner. All credit to Joshua Poehls for the tool.
The solution JSON-escaper built on top of a more generic JavaScript utility which addresses escaping special characters which can be found here.
We could solve this with custom integrations, or we can exploit an IETF standard called SCIM (System for Cross-domain Identity Management). The beauty of SCIM is that it brings a level of standardization to the mechanics of sharing personal identity information, addressing the fact that this data goes through a life cycle.
While Oracle’s IDCS and IAM support identity management for authentication and authorization for OCI and SaaS such as HCM, SCM, and so on. Most software ecosystems need more than that. If you have personalized custom applications or COTS or non-Oracle SaaS that need more than just authentication and need some of your people’s data needs to be replicated.
The lifecycle would include:
Creation of users.
Users move in and out of groups as their roles and responsibilities change.
User details change, reflecting life events such as changing names.
Users leave as they’re no longer employees, deleted their account for the service, or exercise their right to be forgotten.
It means any SCIM-compliant application can be connected to IDCS or IAM, and they’ll receive the relevant changes. Not only does it standardize the process of integrating it helps handle compliance needs such as ensuring data is correct in other applications, that data is not retained any longer than is needed (removal in IDCS can trigger the removal elsewhere through the SCIM interface). In effect we have the opportunity to achieve master data management around PII.
SCIM works through the use of standardized RESTful APIs. The payloads have a standardized set of definitions which allows for customized extension as well. The customization is a lot like how LDAP can accommodate additional data.
The value of SCIM is such that there are independent service providers who support and aid the configuration and management of SCIM to enable other applications.
Securing such data flows
As this is flowing data that is by its nature very sensitive, we need to maximize security. Risks that we should consider:
Malicious intent that results in the introduction of a fake SCIM client to egress data
Use of the SCIM interface to ingress the poisoning of data (use of SCIM means that poisoned data could then propagate to all the identity-connected systems).
Identity hijacking – manipulating an identity to gain further access.
There are several things that can be done to help secure the SCIM interfaces. This can include the use of an API Gateway to validate details such as the identity of the client and where the request originated from. We can look at the payload and validate it against the SCIM schema using an OCI Function.
We can block the use of operations by preventing the use of certain HTTP verbs and/or URLs for particular or all origins.
The 12 Factor App definition is now ten years old. In the world of software that is a long time. So perhaps it’s time to revisit and review what it says. As I have spent a lot of time around Logging – I’ve focussed on Factor 11 – Logging.
I have been fortunate enough to present at the hybrid JAX London conference on this subject. It was great to get out and see people at a conference rather than just with a screen and a chat console of online-only events.
When building Node solutions, even if you’re not going to publish the code to a public repository you’re likely to be using package.json to declare the dependencies for your app. Doing this makes it easier to build and deploy a utility. But if you’re conversant with several languages there is a tendency to just adapt your existing skills to work with others. The downside of this is small tooling nuances can catch you off guard and consume time while figuring them out. The workings of packages with NPM (as shown below) is one possible case.
If you create the package.json using npm init to create the initial version of the file, it is fairly common to set values to default. In the case of the license, this is an ISC license. This is easily forgotten. The problem here is twofold:
Does the license set reflect the constraints of the dependencies and their licenses
Does the default license reflect the position you want?
Looking at the latter point first, This is important as organizations have matured (and tooling greatly improved) when it comes to understanding how open source licensing can impact. This is particularly important for any organizations leveraging open source as part of their revenue generating activities either ‘as a service’ but also selling software solutions. If you put the wrong license here the license checking tools often protecting code repositories may reject your code, even in internal only use cases (yes this tripped me up).
To help overcome this issue you can install a tool that will analyze the dependencies and optionally their dependencies and report back on your license exposure. This tool is called license-report. Once installed (npm install -g license-report) we just need to point the tool to the package.json file. e.g. license-report package.json. We can make the results a lot more consumable by outputting the content in a number of formats. For example a simple text value:
From this, you could set your license declaration in package.json or validate that your preferred license won’t conflict,
I’ve designed a variety of GraphQL schemas and developed microservice backends. But not done much with configuring the Apollo implementation of a GraphQL server until recently. This may reflect the fact my understanding of JavaScript doesn’t extend into the world of Node.JS as much as I’d like (the problem with being a multi-language developer is you’re likely to find your way around many languages but never be a master of one). Anyway, the following content is about the implementation within a GraphQL server part of a solution. It may be these pointers are just for my benefit you might find them helpful as well.
To make it easy to reference the code, we’ve added entries (n) into the code, where n is a number. This is not part of the code. But there to make the different lines referenceable. Where code should go but is not relevant to the point being made I’ve added ellipsis (…)
Dynamic loading and server configuration
import { ApolloServer } from 'apollo-server';
import { loadFilesSync } from '@graphql-tools/load-files';
import { resolvers } from './resolvers.js'; (1)
import ProviderInternalAPI from './ProviderInternalAPI.js'; (1)
import EventsInternalAPI from './EventsInternalAPI.js'; (1)
const server = new ApolloServer({
debug : true, (2)
typeDefs: loadFilesSync('./schema.graphql'), (3)
resolvers,
dataSources: () => {
return {
eventsInternalAPI: new EventsInternalAPI(), (4)
providerInternalAPI: new ProviderInternalAPI() (4)
pro
};
}});
There is the potential to dynamically load the resolvers rather than importing each JavaScript file as we see on lines (1). The mechanics to do this is documented here. It would be cool if an opinionated implementation was provided. As shown by (3) we can take a independent schema file being loaded. The Apollo example approach for this didn’t seem to work for us, although both approaches make use of graphql-tools in a synchronous manner.
We can switch on debugging (2) for the GraphQL server, although the level of information published doesn’t appear to be significant. Ideally this setting is changed for production.
Defining the resolvers
The prefix for each resolver (1) must correlate to the name in the schema of the mutator or query (not the type as you would expect with Java). Often we don’t need all the parameters for the resolver. The documentation describes replacing each unused parameter with one or more underscores (i.e _, __ ). The underscore denoting the field not in use. However we can satisfy the indication of not being used, but keep the meaning of each position by using the underscore then a name (i.e. _parent, _args ) as shown in (2).
By taking the response into a variable (3) we can optionally log it. Trying to return using invocation line would result in the handler object rather than the payload itself. By taking the result into a variable we can log the content if desired and return the content.
The use of the backward quote is a node feature. It allows us to incorporate variables into a string by referencing it within ${}(4).
We need to supply the GraphQL server with instances with a layer of code that will interact with the resolvers. We can instantiate the instances in the declaration. The naming of the object is important (4) to the resolver.js (declarations).
import { useLogger } from "@graphql-yoga/node";
...
latestEvent (1): async (_parent, _args, { dataSources }, _info) (2) => {
if (log) { console.log("resolvers - get latest event"); }
let responseValue = await dataSources.eventsInternalAPI.getLatestEvent(); (3)
if (log) { console.log(`(4) Resolver response for latest event:\n ${responseValue}`); }
return responseValue;
},
To handle the use of resolvers within a larger resolver we need to declare the resolution outside of the Query and Mutator blocks (but inside the whole declaration block)(1). The name provided needs to match the parent entity that the query resolver contributes to.
To then provide values from the outer resolution we need to prover to the chained resolution use the naming as represented in the GraphQL schema as shown by (2). The GraphQL engine will resolve the mapping values.
Web resolver URL
// GET
async getProvider(code) {
console.log("getProvider (%s) directing to %s",code,this.baseURL);
return this.get(`provider?code=${code} (1)`);
}
The URL parameters need to be appended to the base URL path for the parent class to use in the invocation as shown by (1). The Apollo examples showed a setter option but we didn’t see the URI being addressed properly. This approach produces the relevant requirement.
A container registry is as essential as a Kubernetes service as you want to manage the deployable resources. That registry could be the public Docker repository or something else. In most people’s cases, the registry needs to be private as you don’t want to expose your product assets to potential external tampering. As a result, we need a service such as Oracle’s container registry OCIR.
The re of this blog is going to walk through how to push a container you’ve built into OCIR and a gotcha that can trip up users if you make assumptions about how the registry works.
Build container
Let’s assume you’re building your microservices locally or retrieving vetting 3rd party services for use. In both cases, you want to manually push your assets into OCIR manually rather than have an automated build pipeline do it for you.
This creates a container locally, and we can see the container listed using the command:
docker images
Setup of OCIR
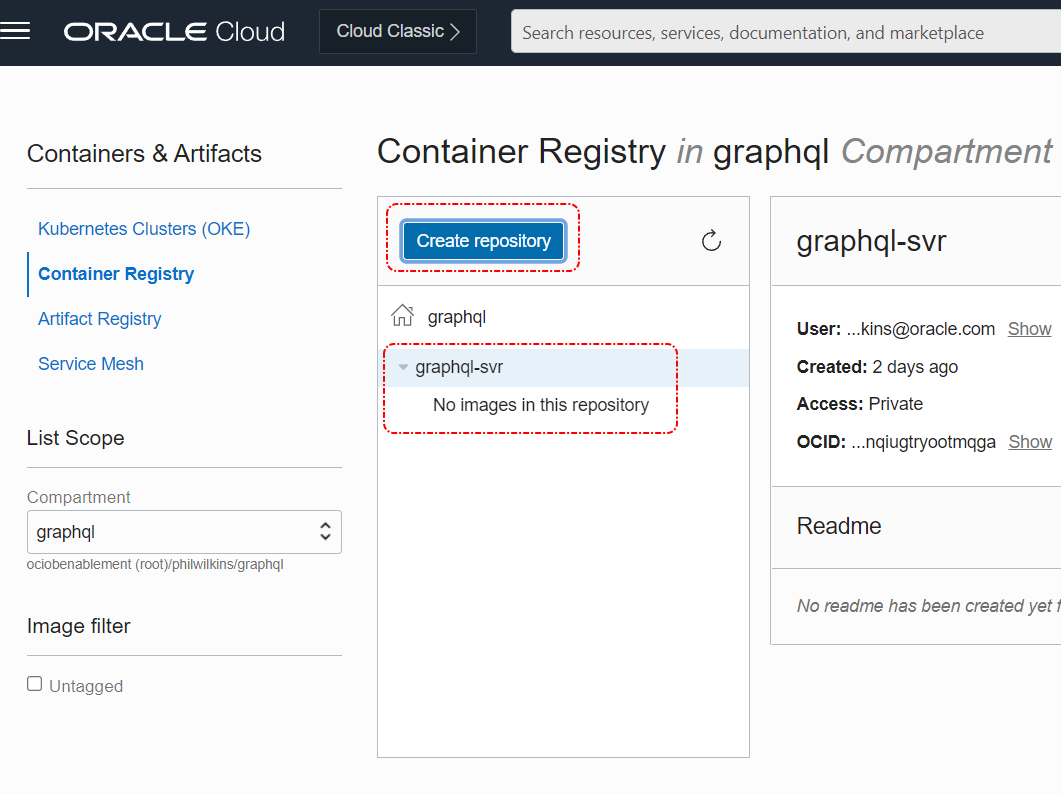
We need an OCIR to target so the easiest thing is to manually create an OCIR instance in one of the regions, for the sake of this illustration we’ll use Ashburn (short code is IAD). To help with the visibility we can put the registry in a separate compartment as a child of the root. Let’s assume we’re going to call the registry GraphQL. So before creating your OCIR set up the compartment as necessary.
fragment of the compartment hierarchy
In the screenshot, you can see I’ve created a registry, which is very quick and easy in the UI (in the menu it’s in the Developer Services section).
The Oracle meu to navigate to the OCIR servicethe UI to create a OCIR
Finally, we click on the button to create the specific OCIR.
Deployment…
Having created the image, and with a repo ready we can start the steps of pushing the container to OCIR.
The next step is to tag the created image. This has to be done carefully as the tag needs to reflect where the image is going using the formula <region name>/<tenancy name/<registry name>:<version>. All the registries will be addressed by <region short code>.ocir.io In our case, it would be iad.ocir.io.
docker tag graph-svr:latest iad.ocir.io/ociobenablement/graphql-svr:v0.1-dev
As you may have realized the tag being applied effectively tells OCI which instance of OCIR to place the container in. Getting this wrong can be the core of the gotcha previously mentioned and we’ll elaborate upon it shortly.
To sign in you’ll need an auth token as that is passed as the password. For simplicity, I’ve passed the token in the docker command, which Docker will warn you of as being insecure, and suggest it is passed in as part of a prompt. Note my token will have been changed by the time this is published. The username is built on the structure of <cloud tenancy name>/identitycloudservice/<username>. The identitycloudservice piece only needs to be included for your authentication is managed through IDCS, as is the case here. The final bit is the URI for the appropriate regional OCIR address, as we’ve used previously.
With hopefully a successful authentication response we can push the container. It is worth noting that the Docker authenticated connection will timeout which is why we’ve put everything in place before connecting. The push command is very simple, it is the tag name assigned to the artifact including the version number.
When we deal with repositories from Git to SVN or Apache Archiva to Nexus we work with a repository that holds multiple different assets with multiple versions of those assets. as a result, when we identify an asset uniquely we would expect to name things based on server/location, repository, asset name, and version. However, here each repository is designed for one type of asset but multiple versions. In reality, a Docker repository works in the same manner (but the extended path impact is different).
This means it becomes easy to accidentally define a tag with an extra element. Depending upon your OCI tenancy privileges if you get the path wrong, OCI creates a new root compartment container repository with a name that is a composite of the name elements after the tenancy and puts your artifact in that repository, not the one you expected.
We can address this in several ways, first and probably the best option is to automate the process of loading assets into OCIR, once the process is correct, it will remain correct. Another is to adopt a principle of never holding repositories at the root of a tenancy, which means you can then explicitly remove the permissions to create repositories in that compartment (you’ll need to explicitly grant the permissions elsewhere in the compartment hierarchy because of policy inheritance. This will result in the process of pushing a container to fail because of privileges if the tag is wrong.
Visual representation of structure differences
Repository Structure
Registry Structure
Condensed to a simple script
These steps can be condensed to a simple platform neutral script as follows:
This script would need modifying for each container being built, but you could easily make it parameterized or configuration drive.
A Note on Registry Standards
Oracle’s Container Registry has adopted the Open Registries standard for OCIR. Open Registries come under the Linux Foundation‘s governance. This standard has been adopted by all the major hyperscalers (Google, AWS, Azure, etc). All the technical spec information for the standard is published through GitHub rather than the main website.
Oracle’s product portfolio is significant, from databases (obviously) to GraalVM to a cloud platform capable of competing with GCP, AWS, and Azure. This means locating the Oracle-provided plugins, or community ones can get messy. Depending on your perspective Oracle Developer Plugins could relate to Java and GraalVM or Oracle Database.
As broad as the portfolio, is the Oracle details regarding the plugins. So the following two tables represent what we’ve identified as Oracle-provided tooling, and the second table of plugins we’ve used when working on Oracle-based solutions from the community.
Name / Plugin Search
Description / Additional Details
Related resource links
search:Oracle Labs This will return all the Oracle plugins related to GraalVM
SuiteCloud Extension for Visual Studio Code is part of the SuiteCloud Software Development Kit (SuiteCloud SDK), a set of tools to customize your NetSuite accounts.
Github actions is a means by which actions like commits to github trigger external infrastructure to perform actions such as creating application binaries.
's Blog")














You must be logged in to post a comment.