's Blog")
Tags
AI, artificial-intelligence, configuration, development, ELK, Fluent Bit, Fluentd, LLM, observability, OpAMP, Technology
Something that vendors like Microsoft have been really good at is reducing the friction on getting started – from simplifying installations with MSI files and defaulted options through to very informative error messages in Excel when you’ve got a function slightly wrong. Apple is another good example of this; while no two Android phones are the same, my experience is that setting up an iPhone is just so much easier than setting up an Android phone. It is also the setup/configuration where most friction comes from.
Open-Source Software (OSS), as a generalisation, tend to be a bit weaker at minimising friction – this comes from several factors:
- When OSS is part of a business model, vendors can reduce that friction, making their enhanced version more attractive.
- OSS contributors are typically focused on the core problem space and are usually close enough to the fine details to not need those fancy features to keep the rest of us out of trouble.
- The expectation is that tools to make configuration easy are embedded in the application, making it heavier, when the aim is to keep things as light as possible.
- Occasionally, a little bit of intellectual snobbery can creep in
The common challenge
The issue that I have observed is that we often go through cycles of working with a technology. For example, you’re building a microservice. Chances are, you’ll start writing and running it locally, without worrying about containerization. Once you’re pretty happy with things, you’ll Dockerize the service, start testing it locally, and then you’ll be ready to deploy it to a cluster. Now you’ll need your YAML. It may well be weeks since you last looked at Helm charts. You end up cutting and pasting your last configuration. But now you need to use another feature of Helm, can you remember the exact settings for the feature. So now you’re trawling the net for documentation, and then it takes several tries to get it right.
AI may well step in to help developers in this area, where solutions and products are well-documented. But with the wrong model or insufficient detail in the prompt, it’s easy to make a mistake. Personally, I’d turn to AI when it becomes necessary to trawl code to better understand the configuration and its behaviour, and to set options.
Experimental Solution
Solution – well, that depends upon the configuration syntax. We have been experimenting with RJSF (React JSON Schema Form), which provides a React-based UI that can be dynamically driven by a JSON schema and validate data with AJV (an alternative stack considered would have been around JSON Forms).
{ "type": "object", "title": "Dummy", "properties": { "name": { "type": "string", "const": "dummy", "title": "Plugin" }, "copies": { "type": "integer", "description": "Number of messages to generate each time messages are generated.", "x-doc-reference": "https://docs.fluentbit.io/manual/data-pipeline/inputs/dummy#configuration-parameters", "x-doc-required": false, "x-config-data-type": "integer", "default": 1 }, "dummy": { "type": "string", "description": "Dummy JSON record.", "x-doc-reference": "https://docs.fluentbit.io/manual/data-pipeline/inputs/dummy#configuration-parameters", "x-doc-required": false, "x-config-data-type": "string", "default": "{\"message\":\"dummy\"}" }, "fixed_timestamp": { "type": "boolean", "description": "If enabled, use a fixed timestamp.", "x-doc-reference": "https://docs.fluentbit.io/manual/data-pipeline/inputs/dummy#configuration-parameters", "x-doc-required": false, "x-config-data-type": "boolean", "default": false } }}
The above fragment shows part of the Schema definition for the Dummy plugin for Fluent Bit.
By then creating a schema that defines the different plugins, attributes, etc., we can drive validation and menu items easily in the UI. Admittedly, the config file is significant given all the plugins and configuration options, but it is a fair price to pay for a UI that validates the data. Establishing the schema to start with, we’ve covered it through scripting the retrieval and scraping of the Fluent Bit pages, which are pretty consistent in structure.
We have added some custom elements into the definition, for example, x-doc-reference, which allows us to extend the React components to provide features such as a link back to the original documentation as you select attributes or plugins.
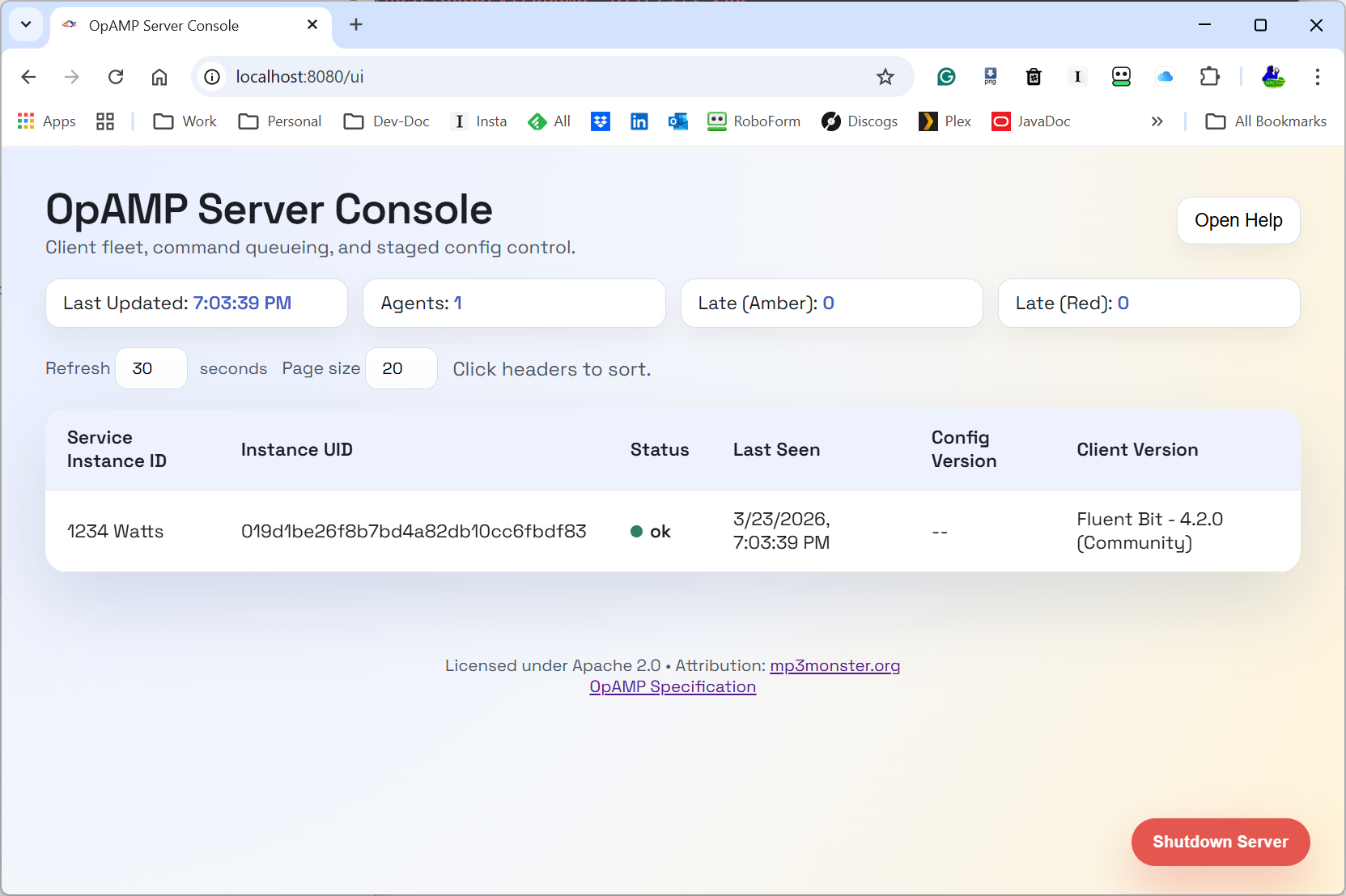
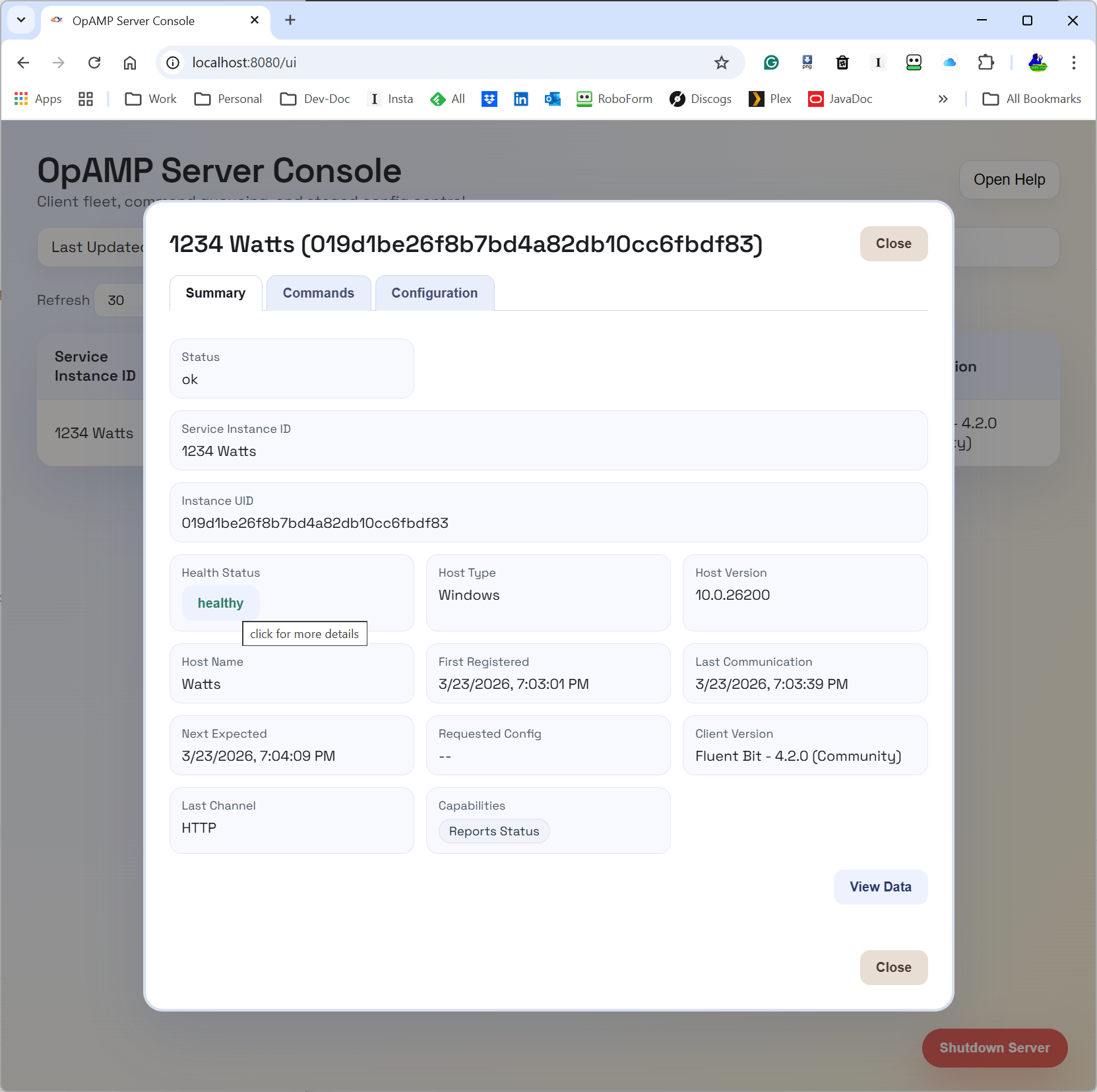
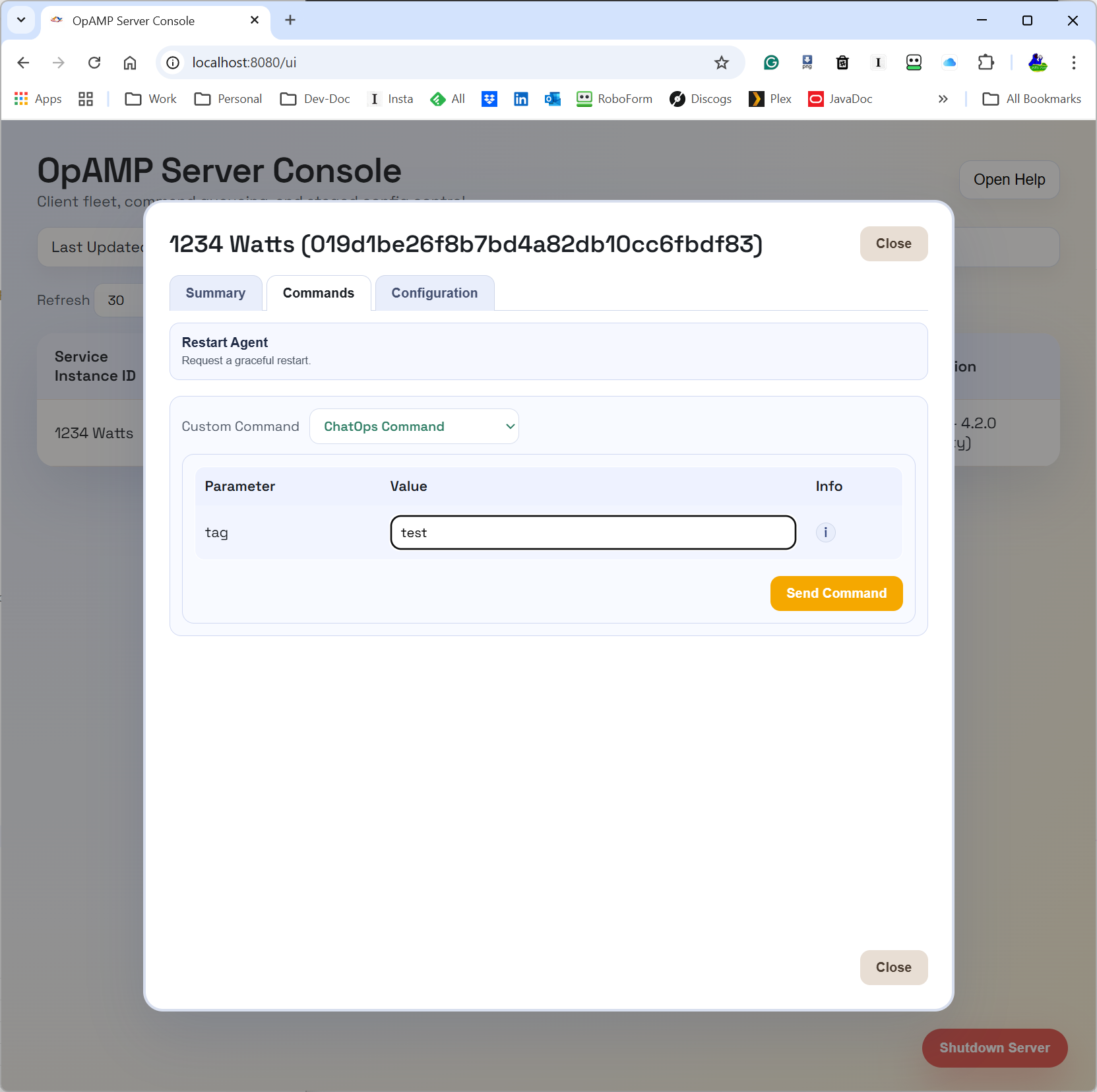
As a result, we very quickly have a UI that can look like this:
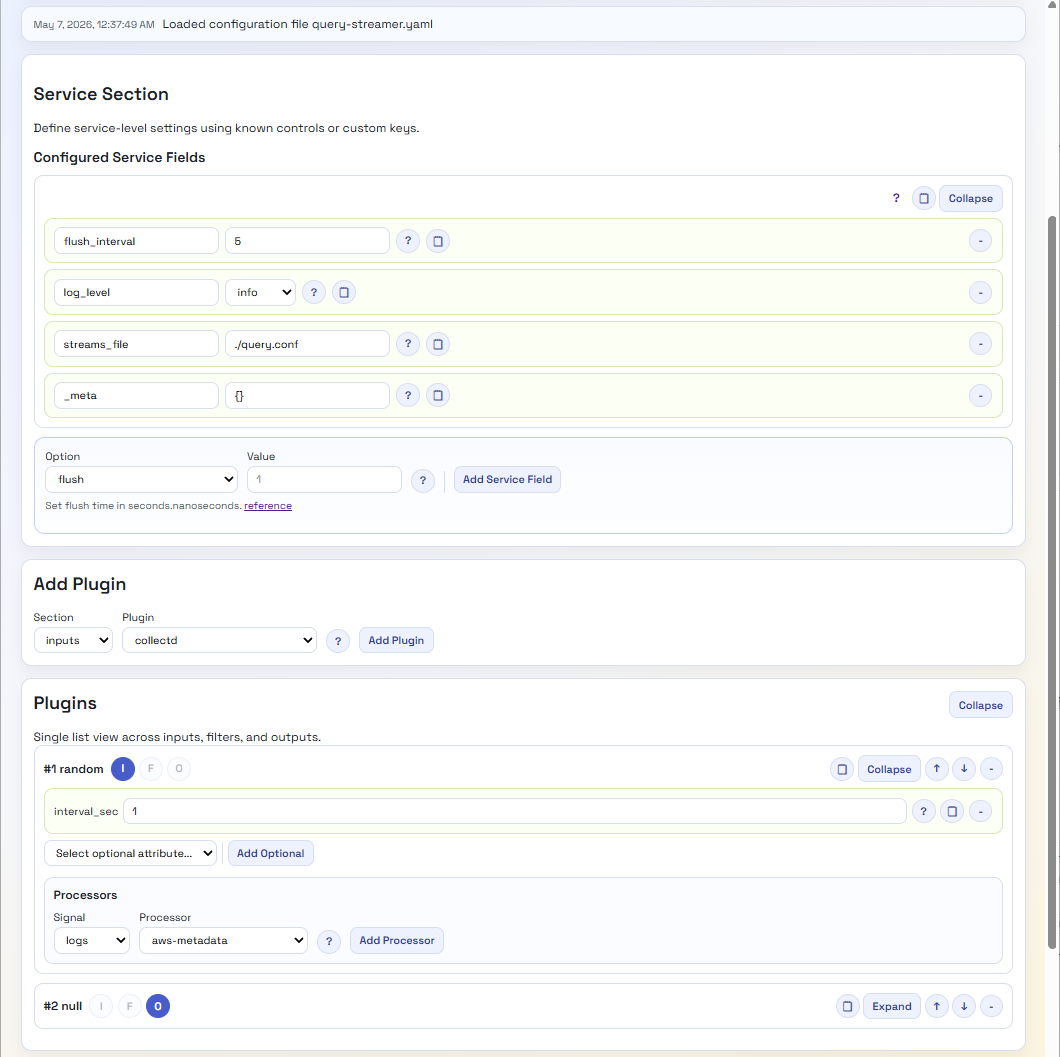
A lot easier to view and tweak, with no need to hunt for valid options. Even if we want more information, we’re just a button click away from the open-source data. Perhaps we should provide a version that hyperlinks to the Manning Live Books on Fluent Bit, etc.
There are a few other factors to consider; for example, Fluent Bit configuration is YAML, not JSON, which can be easily resolved given the relationship between the two standards. Then there are processors that can embed Lua code or a SQL-like syntax. As we’ve chosen to provide a Python backend, we’ve addressed this by providing REST endpoints which can query out of the JSON the code or SQL and perform validation using the Python Lua Parser, and the SQL syntax can be addressed using the Lark library for processing the SQL, as the syntax is simple enough to define and maintain the syntax.
Outstanding Gaps for Fluent Bit
We still need to address several features that Fluent Bit has, specifically:
- Environment variables
- Includes
These issues should be straightforward to overcome, although dynamically including the included elements into the UI view elements can be done. The challenge is: if any changes need to go into something that has been included, how do we push them back to the included file? Particularly if there are multiple layers of inclusion.
What about Fluentd?
Fluentd configuration isn’t JSON-based notation, but it is structured. So, to apply the same mechanism, we’ll need to define a schema and a mapping mechanism. The tricky part of the schema is that Fluentd supports nesting plugins, since the way pipelines are defined for routing differs. While JSON schema will enable this with constructs such as anyOf, oneOf, object nesting, and bounded object arrays, the structure will be more complex.
The second challenge will be the transformer/renderer, so we don’t introduce issues from having to escape and unescape characters, since JSON Schema is stricter about character use.
Then What?
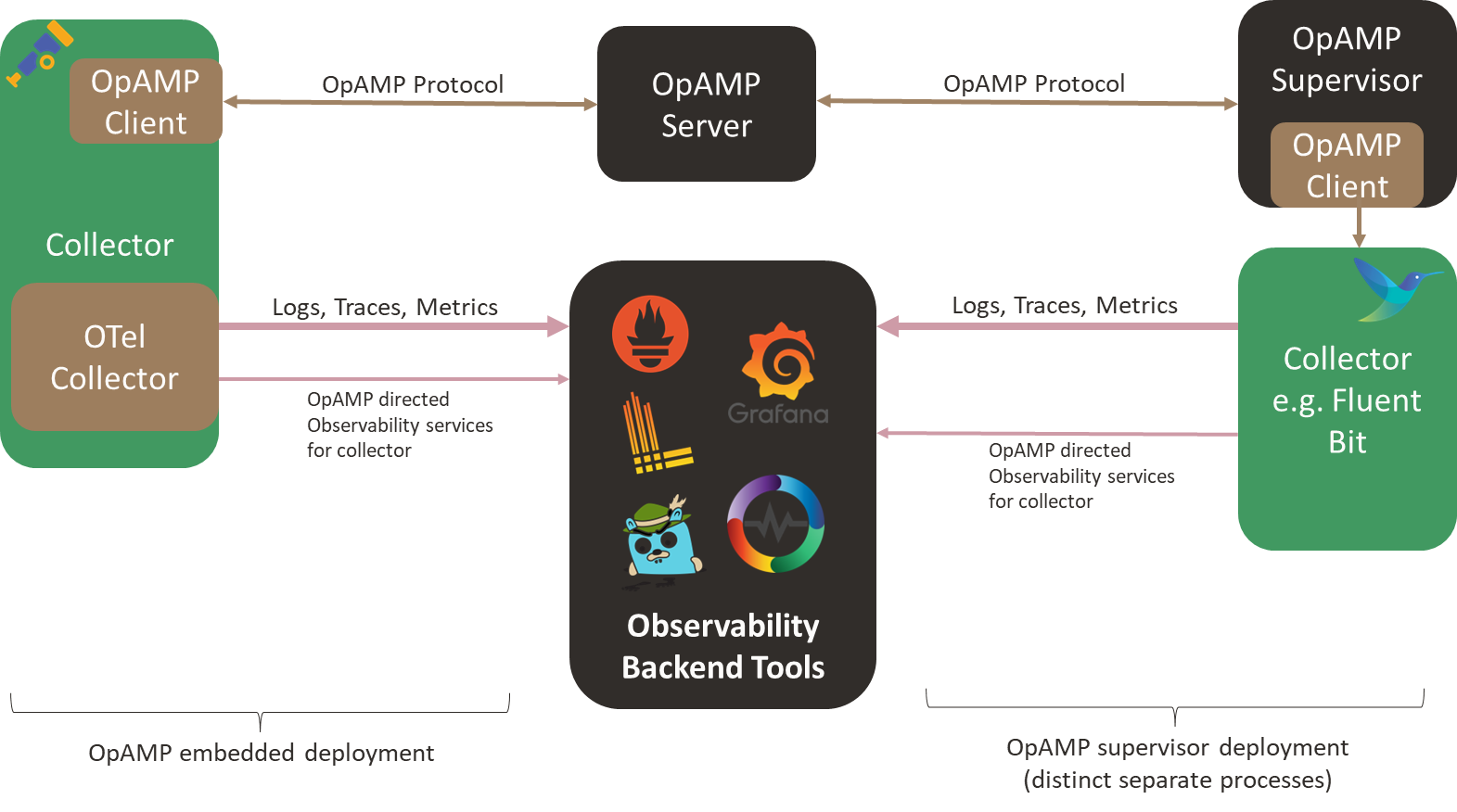
Well, if we get this going, we’ll probably incorporate the capability into our OpAMP project and maybe create a build that lets the configuration tool run independently. Lastly, perhaps we should look to see if we can make the different layers a little more abstract, so we can plug in editors for other configurations, such as OTel Collectors or the ELK Stack.
As a bonus, perhaps transform the Schema into a quick reference web document?




You must be logged in to post a comment.