Many of the most potent features being added to Fluent Bit are only available in the newer YAML format. At the same time Fluent Bit is celebrating its 10th anniversary, so we can be sure that are some established deployments that are being maintained with the classic format.
The transition between the two Fluent Bit formats can be a bit fiddly. We built a tool as described in my Fluent Bit config from classic to YAML post using Java over a year ago. While it addressed many of the needs, I wasn’t entirely happy with the solution, for several reasons:
Written in Java, which, as a language, is the one I’m most at home with, as an implementation, it does increase the workload for using and implementing – needing a container, etc., ideally. Not unreasonable, but as a small tool project, we’re not working with a nice enterprise build pipeline, so from a code tweak to test is just fiddlier. I’m sure any Java devs reading this will be shouting, ” Setting up Maven, Jenkins, JUnit isn’t difficult – and they’re right, but it’s a time-consuming distraction from working on the real problem.
While it works, the code didn’t feel as clean as it could or should.
Over the last couple of years, we’ve become more comfortable with Python, and messing around with LLMs and code generation has helped accelerate our development skills. Python offers a potentially better solution: many environments that use Fluentd or Fluent Bit are Linux-based and include Python by default, so you can use the tool without messing with containers if you don’t want to. For a tool intended to support development and maintenance of configurations rather than in production being able to use or modify/extend the code easily is attractive.
We’ve started afresh and built a new implementation that is more extensible and maintainable. The new Python implementation is under the same Apache 2 license, but in a different repo so that existing use and forks of the Java implementation aren’t disrupted.
We can wrap Python with all the production-class build processes, but it’s not necessary to get a tool up and running or to enable people to tinker as needed. So we have focused on that. Over time, we’ll play with Poetry or other packaging mechanisms to make it even easier.
MCP (Model Context Protocol) has really taken off as a way to amplify the power of AI, providing tools for utilising data to supplement what a foundation model has already been trained on, and so on.
With the rapid uptake of a standard and technology that has been development/implementation led aspects of governance and security can take time to catch up. While the use of credentials with tools and how they propagate is well covered, there are other attack vectors to consider. On the surface, it may seem superficial until you start looking more closely. A recent paper Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions highlights this well, and I thought (even if for my own benefit) to explain some of the vectors.
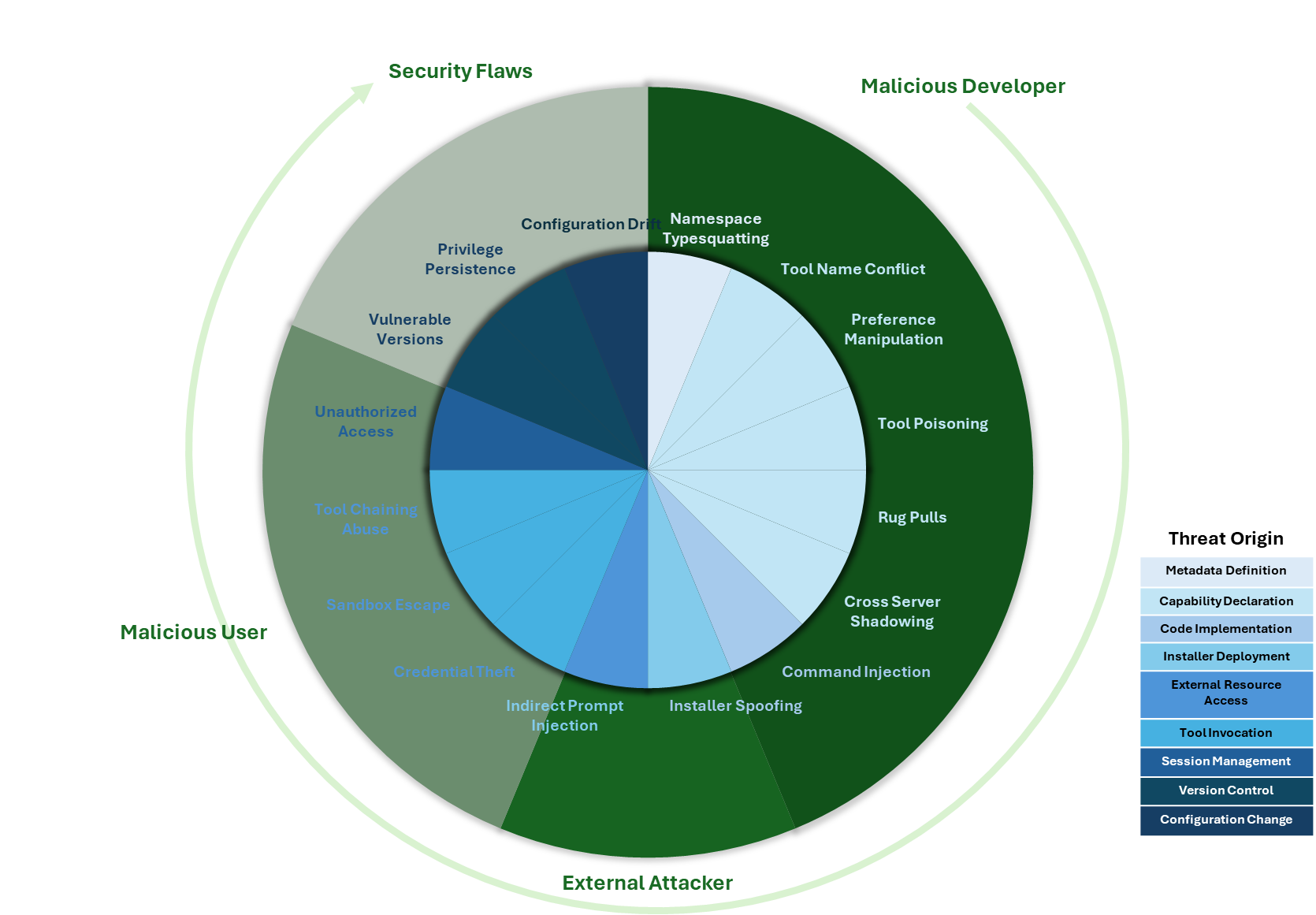
I’ve also created a visual representation based on the paper of the vectors described.
The inner ring represents each threat, with its color denoting the likely origin of the threat. The outer ring groups threats into four categories, reflecting where in the lifecycle of an MCP solution the threat could originate.
I won’t go through all the vectors in detail, though I’ve summarized them below (the paper provides much more detail on each vector). But let’s take a look at one or two to highlight the unusual nature of some of the issues, where the threat in some respects is a hybrid of potential attack vectors we’ve seen elsewhere. It will be easy to view some of the vectors as fairly superficial until you start walking through the consequences of the attack, at which point things look a lot more insidious.
Several of the vectors can be characterised as forms of spoofing, such as namespace typosquatting, where a malicious tool is registered on a portal of MCP services, appearing to be a genuine service — for example, banking.com and bankin.com. Part of the problem here is that there are a number of MCP registries/markets, but the governance they have and use to mitigate abuse varies, and as this report points out, those with stronger governance tend to have smaller numbers of services registered. This isn’t a new problem; we have seen it before with other types of repositories (PyPI, npm, etc.). The difference here is that the attacker could install malicious logic, but also implement identity theft, where a spoofed service mimics the real service’s need for credentials. As the UI is likely to be primarily textual, it is far easier to deceive (compared to, say, a website, where the layout is adrift or we inspect URIs for graphics that might give clues to something being wrong). A similar vector is Tool Name Conflict, where the tool metadata provided makes it difficult for the LLM to distinguish the correct tool from a spoofed one, leading the LLM to trust the spoof rather than the user.
Another vector, which looks a little like search engine gaming (additional text is hidden in web pages to help websites improve their search rankings), is Preference Manipulation Attacks, where the tool description can include additional details to prompt the LLM to select one solution over another.
The last aspect of MCP attacks I wanted to touch upon is that, as an MCP tool can provide prompts or LLM workflows, it is possible for the tool to co-opt other utilities or tools to action the malicious operations. For example, an MCP-provided prompt or tool could ask the LLM to use an approved FTP tool to transfer a file, such as a secure token, to a legitimate service, such as Microsoft OneDrive, but rather than an approved account, it is using a different one for that task. While the MCP spec says that such external connectivity actions should have the tool request approval, if we see a request coming from something we trust, it is very typical for people to just say okay without looking too closely.
Even with these few illustrations, tooling interaction with an LLM comes with deceptive risks, partially because we are asking the LLM to work on our behalf, but we have not yet trained LLMs to reason about whether an action’s intent is in the user’s best interests. Furthermore, we need to educate users on the risks and telltale signs of malicious use.
Attack Vector Summary
The following list provides a brief summary of the attack vectors. The original paper examines each in greater depth, illustrating many of the vectors and describing possible mitigation strategies. While many technical things can be done. One of the most valuable things is to help potential users understand the risks, use that to guide which MCP solutions are used, and watch for signs that things aren’t as they should be.
So, there is a new book title published with me as the author (Logging Best Practices) published by Manning, and yes, the core content has been written by me. But was I involved with the book? Sadly, not. So what has happened?
Background
To introduce the book, I need to share some background. A tech author’s relationship with their publisher can be a little odd and potentially challenging (the editors are looking at the commerciality – what will ensure people will consider your book, as well as readability; as an author, you’re looking at what you think is important from a technical practitioner).
It is becoming increasingly common for software vendors to sponsor books. Book sponsorship involves the sponsor’s name on the cover and the option to give away ebook copies of the book for a period of time, typically during the development phase, and for 6-12 months afterwards.
This, of course, comes with a price tag for the sponsor and guarantees the publisher an immediate return. Of course, there is a gamble for the publisher as you’re risking possible sales revenue against an upfront guaranteed fee. However, for a title that isn’t guaranteed to be a best seller, as it focuses on a more specialized area, a sponsor is effectively taking the majority investment risk from the publisher (yes, the publisher still has some risk, but it is a lot smaller).
When I started on the Fluent Bit book (Logs and Telemetry), I introduced friends at Calyptia to Manning, and they struck a deal. Subsequently, Calyptia was acquired by Chronosphere (Chronosphere acquires Calyptia), so they inherited the sponsorship. An agreement I had no issue with, as I’ve written before, I write as it is a means to share what I know with the broader community. It meant my advance would be immediately settled (the advance, which comes pretty late in the process, is a payment that the publisher recovers by keeping the author’s share of a book sale).
The new book…
How does this relate to the new book? Well, the sponsorship of Logs and Telemetry is coming to an end. As a result, it appears that the commercial marketing relationship between Chronosphere and Manning has reached an agreement. Unfortunately, in this case, the agreement over publishing content wasn’t shared with the author or me, or the commissioning editor at Manning I have worked with. So we had no input on the content, who would contribute a foreword (usually someone the author knows).
Manning is allowed to do this; it is the most extreme application of the agreement with me as an author. But that isn’t the issue. The disappointing aspect is the lack of communication – discovering a new title while looking at the Chronosphere website (and then on Manning’s own website) and having to contact the commissioning editor to clarify the situation isn’t ideal.
Reading between the lines (and possibly coming to 2 + 2 = 5), Chronosphere’s new log management product launch, and presumably being interested in sponsoring content that ties in. My first book with Manning (Logging in Action), which focused on Fluentd, includes chapters on logging best practices and using logging frameworks. As a result, a decision was made to combine chapters from both books to create the new title.
Had we been in the loop during the discussion, we could have looked at tweaking the content to make it more cohesive and perhaps incorporated some new content – a missed opportunity.
If you already have the Logging in Action and Logs and Telemetry titles, then you already have all the material in Logging Best Practices. While the book is on the Manning site, if you follow the link or search for it, you’ll see it isn’t available. Today, the only way to get a copy is to go to Chronosphere and give them your details. Of course, suppose you only have one of the books. In that case, I’d recommend considering buying the other one (yes, I’ll get a small single-digit percentage of the money you spend), but more importantly, you’ll have details relating to the entire Fluent ecosystem, and plenty of insights that will help even if you’re currently only focused on one of the Fluent tools.
Going forward
While I’m disappointed by how this played out, it doesn’t mean I won’t work with Manning again. But we’ll probably approach things a little differently. At the end of the day, the relationship with Manning extends beyond commercial marketing.
Manning has a tremendous group of authors, and aside from writing, the relationship allows me to see new titles in development.
Working with the development team is an enriching experience.
It is a brand with a recognized quality.
The social/online marketing team(s) are great to interact with – not just to help with my book, but with opportunities to help other authors.
As to another book, if there was an ask or need for an update on the original books, we’d certainly consider it. If we identify an area that warrants a book and I possess the necessary knowledge to write it, then maybe. However, I tend to focus on more specialized domains, so the books won’t be best-selling titles. It is this sort of content that is most at risk of being disrupted by AI, and things like vibe coding will have the most significant impact, making it the riskiest area for publishers. Oh, and this has to be worked around the day job and family.
The latest release of Fluent Bit is only considered a patch release (based on SemVer naming). But given the enhancements included it would be reasonable to have called it a minor change. There are some really good enhancements here.
Character Encoding
As all mainstream programming languages have syntaxes that lend themselves to English or Western-based languages, it is easy to forget that a lot of the global population use languages that don’t have this heritage, and therefore can’t be encoded using UTF-8. For example, according to the World Factbook, 13.8% speak Mandarin Chinese. While this doesn’t immediately translate into written communication or language use with computers, it is a clear indicator that when logging, we need to support log files that can be encoded to support idiomatic languages, such as Simplified Chinese, and recognized extensions, such as GSK and BIG5. However, internally, Fluent Bit transmits the payload as JSON, so the encoding needs to be handled. This means log file ingestion with the Tail plugin ideally needs to support such encodings. To achieve this, the plugin features a native character encoding engine that can be directed using a new attribute called generic. encoding, which is used to specify the encoding the file is using.
The Win**** encodings are Windows-based formats that predate the adoption of UTF-8 by Microsoft.
Log Rotation handling
The Tail plugin, has also seen another improvement. Working with remote file mounts has been challenging, as it is necessary to ensure that file rotation is properly recognized. To improve the file rotation recognition, Fluent Bit has been modified to take full advantage of fstat. From a configuration perspective, we’ll not see any changes, but from the viewpoint of handling edge cases the plugin is far more robust.
Lua scripting for OpenTelemetry
In my opinion, the Lua plugin has been an underappreciated filter. It provides the means to create customized filtering and transformers with minimal overhead and effort. Until now, Lua has been limited in its ability to interact with OpenTelemetry payloads. This has been rectified by introducing a new callback signature with an additional parameter, which allows access to the OLTP attributes, enabling examination and, if necessary, return of a modified set. The new signature does not invalidate existing Lua scripts with the older three or four parameters. So backward compatibility is retained.
The most challenging aspect of using Lua scripts with OpenTelemetry is understanding the attribute values. Given this, let’s just see an example of the updated Lua callback. We’ll explore this feature further in future blogs.
function cb(tag, ts, group, metadata, record)
if group['resource']['attributes']['service.name'] then
record['service_name'] = group['resource']['attributes']['service.name']
end
if metadata['otlp']['severity_number'] == 9 then
metadata['otlp']['severity_number'] = 13
metadata['otlp']['severity_text'] = 'WARN'
end
return 1, ts, metadata, record
end
Other enhancements
With nearly every release of Fluent Bit, you can find plugin enhancements to improve performance (e.g., OpenTelemetry) or leverage the latest platform enhancements, such as AWS services.
One of the benefits of being an author with a publisher like Manning is being given early access to books in development and being invited to share my thoughts. Recently, I was asked if I’d have a look at Think Distributed Systems by Dominik Tornow.
Systems have become increasingly distributed for years, but the growth has been accelerating fast, enabled by technologies like CORBA, SOAP, REST frameworks, and microservices. However, some distribution challenges even manifest themselves when using multithreading applications. So, I was very interested in seeing what new perspectives could be offered that may help people, and Dominik has given us a valuable perspective.
I’ve been fortunate enough that my career started with working on large multi-server, multithreaded mission-critical systems. Using Ada and working with a mentor who challenged me to work through such issues. How does this relate to the book? This work and the mentor meant I built some good mental models of distributed development early in my career. Dominik calls out that having good mental models to understand distributed systems and the challenges they can bring is key to success. It’s this understanding that equips you to understand challenges such as resource locking, contending with mutual deadlock, transaction ordering, the pros and cons of optimistic locking, and so on.
As highlighted early on in this book, most technical books come from the perspective of explaining tools, languages, or patterns and to make the examples easy to follow, the examples tend to be fairly simplistic. This is completely understandable; these books aim to teach the features of the language. Not how to bring these things to bear in complex real-world use cases. As a result, we don’t necessarily get the fullest insight and understanding of the problems that can come with optimistic locking.
Given the constraints of explaining through the use of programming features, the book takes a language-agnostic approach to explaining the ideas, and complexities of distributed solutions. Instead, the book favors using examples, analogies, and mathematics to illustrate its points. The mathematics is great at showing the implications of different aspects of distributed systems. But, for readers like me who are more visual and less comfortable with numeric abstraction, this does mean some parts of the book require more effort – but it is worth it. You can’t deny hard numeric proofs can really land a message, and if you know what the variables are that can change a result, you’re well on your way.
For anyone starting to design and implement distributed and multi-threaded applications for the first time, I’d recommend looking at this book. From what I’ve seen so far, the lessons you’ll take away will help keep you from walking into some situations that can be very difficult to overcome later or, worse, only manifest themselves when your system starts to experience a lot of load.
Fluent Bit supports both a classic configuration file format and a YAML format. The support for YAML reflects industry direction. But if you’ve come from Fluentd to Fluent Bit or have been using Fluent Bit from the early days, you’re likely to be using the classic format. The differences can be seen here:
[SERVICE]
flush 5
log_level debug
[INPUT]
name dummy
dummy {"key" : "value"}
tag blah
[OUTPUT]
name stdout
match *
#
# Classic Format
#
Beyond having a consistent file format, the driver is that some new features are not supported by the classic format. Currently, this is predominantly for Processors; it is fair to assume that any other new major features will likely follow suit.
Migrating from classic to YAML
The process for migrating from classic to YAML has two dimensions:
Change of formatting
YAML indentation and plugins as array elements
addressing any quirks such as wildcard (*) being quoted, etc
Addressing constraints such as:
Using include is more restrictive
Ordering of inputs and outputs is more restrictive – therefore match attributes need to be refined.
None of this is too difficult, but doing it by hand can be laborious and easy to make mistakes. So, we’ve just built a utility that can help with the process. At the moment, this solution is in an MVP state. But we hope to have beefed it up over the coming few weeks. What we plan to do and how to use the util are all covered in the GitHub readme.
A quick update to say that we now have a container configuration in the repository to make the tool very easy to use. All the details will be included in the readme, along with some additional features.
Update 7th July
We’ve progressed past the MVP state now. The detected include statements get incorporated into a proper include block but commented out.
We’ve added an option to convert the attributes to use Kubernetes idiomatic form, i.e., aValue rather than a_value.
The command line has a help option that outputs details such as the control flags.
Update 12th July
In the last couple of days, we pushed a little too quickly to GitHub and discovered we’d broken some cases. We’ve been testing the development a lot more rigorously now, and it helps that we have the regression container image working nicely. The Javadoc is also generating properly.
We have identified some edge cases that need to be sorted, but most scenarios have been correctly handled. Hopefully, we’ll have those edge scenarios fixed tomorrow, so we’ll tag a release version then.
When it comes to observability, particularly logs, and traces, there is a historical tendency to process things in a batch manner or even only once the need to determine the root cause of an outage, often only using something in the metrics to indicate something might not be right. This misses a real opportunity given Fluent Bit can capture observability events in near real-time, whether that is a log, metric, or trace indicating something unhealthy; why not present the issue to those performing an ops role as soon as it is recognized by Fluent Bit. Not once the data is processed by a back end?
While we have solutions like PagerDuty, they tend to be integrated with back-end event analytics tools. Fluent Bit can talk to social channels such as Slack – so why not direct critical events to Slack and interact with the Ops team more directly. After all, if we’re told quickly about an imminent issue or as soon after something wrong occurs, the impact and effort involved in remediation and recovery are smaller. This is the basis of a presentation that Patrick Stephens (from Chronosphere and a committer to the Fluent Bit project) and I have put together. Patrick will be leading the session at the Cloud Native Rejekts conference in Paris (the ‘b side’ to Kube Con Europe), which takes place on the two days before Kubecon itself.
The session looks at the idea of what has been called ChatOps, why and how it can bring value, facilitated with a demo of using Fluent Bit to detect and share an event with Fluent Bit and also pick up and handle directions from the Ops team in the Slack channel.
We hope you’ll see from the session why we think the approach is worthy of consideration and how the potential security considerations can be mitigated. The MVP code is currently here but may, in due course, actually be migrated to the Fluent repos here.
We’ve bundled readme content and scripts to build and help test the additional functionality created to facilitate part of the operation.
We don’t want to spoil the presentation, so we won’t share too much. But it’ll also be worth checking with the blog, seeing as we’ll record a video and eventually record a session explaining the MVP’s ins and outs.
The new book focuses on Fluent Bit, given its significant advances, reflected by the fact it is now at Version 2 and is deserving of its own title. The new book is a free-standing book but is complimentary to the Logging In Action book. Logging in Action focuses on Fluentd but compliments by addressing more deeply deployment strategies for Fluent Bit and Fluentd. The new book engages a lot more with OpenTelemetry now it has matured, along with technologies such as Prometheus.
It is the fact that we’ve seen increasing focus in the cloud native space on startup speeds and efficiency in footprints that have helped drive Fluent Bit, as it operates with native binaries rather than using a Just-In-Time compilation like Ruby (used for Fluentd). The other significant development is the support for OpenTelemetry.
The book has entered the MEAP (Manning Early Access Program). The first three chapters have been peer-reviewed, and changes have been applied; another three are with the development editor. If you’ve not read a MEAP title before, you’ll find the critical content is in the chapters, but from my experience, as we work through the process, the chapters improve as feedback is received. In addition, as an author, when we have had time away from a chapter and then revisit it – it is easier to spot things that aren’t as clear as they could be. So, it is always worth returning as a reader and looking at chapters. Then, as we move to the production phases, any linguistic or readability issues that still exist are addressed as a copy editor goes through the manuscript.
I’d like to thank those involved with the peer review. Their suggestions and insights have been really helpful. Plus, the team at Calyptia is sponsoring the book (and happens to be employing a number of the Fluent Bit contributors).
We also have a discount code on the book, valid until 20th November – mlwilkins2
Development trends have shown a shift towards precompiled languages like Go and Rust away from interpreted or Just-In-Time (JIT) compiled languages like Java and Ruby as it removes the startup time of the language virtual machine and the JIT compiler as well as a smaller memory footprint. All desirable features when you’re scaling containerized solutions and percentage point savings can really add up.
Oracle has been leading the way with its work on GraalVM for some years now, and as a result, not only can GraalVM be used to produce native binary images from Java code, GraalVM also supports TuffleRuby and GraalPy, among others. As TruffleRuby is an open-source project, Oracle isn’t the only vendor contributing to it, work effort has also come from Shopify.
Helping Ruby move forward isn’t new for the Shopify engineering team, and part of that investment is that they have just announced the open-sourcing of a toolchain called Ruvy. Ruvy takes Ruby and creates a WebAssembly (WASM) from it the code. This builds on the existing project ruby.wasm. In doing so they’ve addressed the Ruby startup overhead of the language VM we mentioned. They have also simplified the process of deployment, eliminating the need for Web Assembly System Interface (WASI) arguments, and overcome constraints of class loading by reading files by having the code bundled within the assembly and then accessing the content using WASI-VFS, a simple virtual file system.
The published benchmarks show a massive performance boost in the process of executing where the Ruby code needs to be executed by the packaged JIT. For me, this is interesting as one of the related cloud-native trends is the shift from Fluentd to Fluent Bit. Fluentd was built with Ruby and has a huge portfolio of third-party extensions. But Fluent Bit is built using C to get those performance gains previously described. But it does support plugins through WASM. This raises an interesting question can we take existing Ruby plugins and wrap them so the required interfacing works – which should be minimal and more likely to be impacted by the fact Fluent Bit v2 has refined the internal data structure that was common to both Fluentd and Fluent Bit to allow Fluent Bit to more easily engaged with OpenTelemetry.
If the extra bit of wrapping code isn’t complex, then applying Ruvy should mean the core plugin can then work with Fluent Bit. If this can be templated, then Fluent Bit is going to make a big leap forward with the number of available plugins.
Infoworld published a rather clickbait incendiary new item the other week ‘few open source projects actively maintained’. Personally, I find these statements a little frustrating, as it would be easy for the less informed to assume that adopting open-source software is dangerous. There are several missed points here:
How well and frequently are close source solutions being maintained, and does that stop businesses from using end-of-life products? There is big business to be had in offering support to end-of-life solutions. Just look at companies like Rimini Street. Such organizations aren’t going to change software unless there is a major issue.
Not all open-source software is intended to be undergoing continuous maintenance? Shocking until you consider that open-source projects will remain open and available even when they have been declared end-of-life. Why? One of the things about open-source is you don’t know who is using the code, and suddenly pulling the code because the originator has decided they can no longer maintain their investment could put others in a difficult position. So, the right thing is to leave the source available and allow people to fork it so they can continue maintaining their own version of it or until they’ve migrated away. That way, the originator is not impacted by changes.
Next up, not all open-source projects need continued maintenance; many repositories exist to provide demo and sample solutions – so that developers can see how to use a product or service. These repositories shouldn’t need to change often. Frequent change could easily be a sign of an unstable product or service. These solutions may not be the most secure, as you don’t want to complicate the illustration with all the checks and balances that should be considered. Look at it this way: when we start learning a new language or tool, we start with the classic Hello World – which today means pointing your browser at a URL and seeing the words appear on the page. Do we insist that the initial implementation be secure? No, because it distracts from the basic message. For example, in my GitHub repository, I have multiple public repositories with Apache2 licenses attached to them – i.e., open-source. A number of them support the books I’ve written – they aren’t going to change – in fact, change would be a bad thing unless the associated book is corrected (this repo, for example).
When it comes to security vulnerabilities. This needs to be viewed with some intelligence. For several reasons:
As mentioned, our demo examples are unlikely to be patched with the latest versions of dependencies all the time. The point is to see how the code works. Unless the demo relates directly to something that has to be patched and that changes the demo itself. I don’t think it is unreasonable to expect developers to apply some intelligence to ensure dependencies (and therefore the risk of known vulnerabilities) are checked rather than blindly cutting and pasting. The majority of the time, such content will be published with a minimum version number, not a maximum.
Sometimes, a security vulnerability isn’t an issue. For example, I rarely run vulnerability checks on my LogSimulator. Not because I have a cavalier attitude to security but because I don’t expect it to ever be near a production environment, and the data flowing through the tool will be known and controlled by the user in advance of any activity. Secondly, it shouldn’t be using sensitive data, and thirdly, if there was any malicious intent intended, then I’d be more concerned about how secure its data source and configuration is. The tool is a command-line solution. That said, I still apply development practices that minimize potential exploitation.
Don’t get me wrong, there are risks with all software – closed and open-source, whether it is maintained or has security vulnerabilities. A software development team has a responsibility to make informed, risk-aware selections of software (open or closed source). If you have the means to check for risks, then they are best used. It is worth not only scanning our own code but also considering whether the dependencies we use have been scanned if appropriate (e.g. used in production). Utilizing innovations like SBOM, and exercising routine checks and reviews can also help.
While I can’t prove it, I suspect there are more risks being carried by organizations adopting a library that was considered sufficiently secure when downloaded, but subsequent vulnerabilities have been found, or selected mitigations to risks have been eroded over time.
's Blog")





You must be logged in to post a comment.